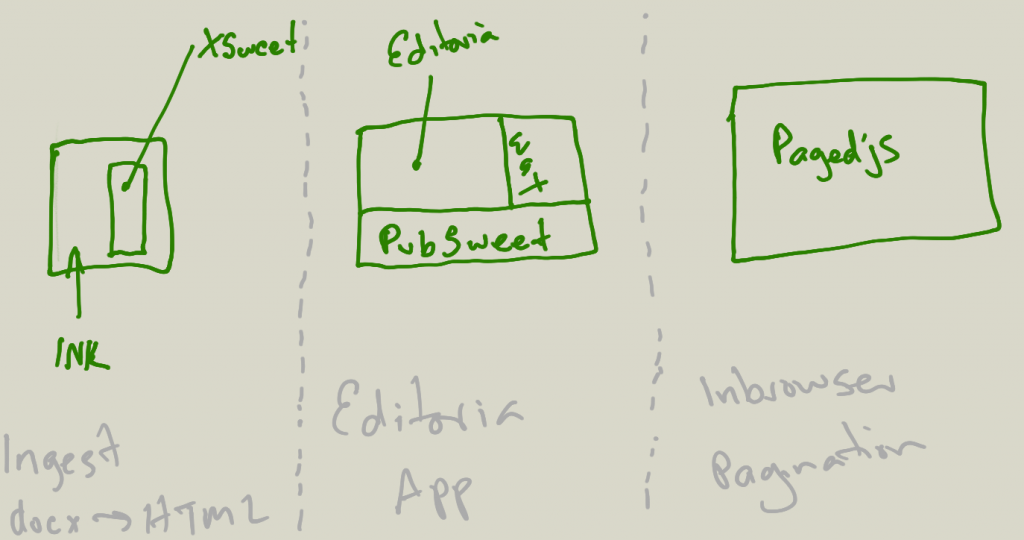
We have a webinar coming up soon for Editoria. In anticipation of that I thought I’d write a little overview of what was involved in building the product. So… Starting with a little hand drawn schematic…
The above shows all the moving parts that we had to consider, and build, to make Editoria what it is. From the user’s perspective, it looks like one app – the Editoria interface – where they can upload a docx file (or files) and start work on producing a book.
From an ‘under the hood’ perspective, it looks like the following…
As it happens, we had to build all of the above to make it possible… So, here is a list of all the parts starting from ingest…
Ingest
Ingest consists of 2 parts:
INK
XSweet
INK is a job processing workhorse. Essentially it will run any kind of job you want and ‘steps’ are written for specific kinds of jobs/processes. These are a kind of ‘wrapper’ around executable code. INK has an API that enables platforms like Editoria to send files to it and request a specific set of steps to be run, and then return the result. In this instance, INK runs a set of steps that wrap up XSweet.
XSweet is a set of scripts that take a docx file and convert it to HTML. It is very modular and can be pretty easily extended and improved. It can also be customised per use case.
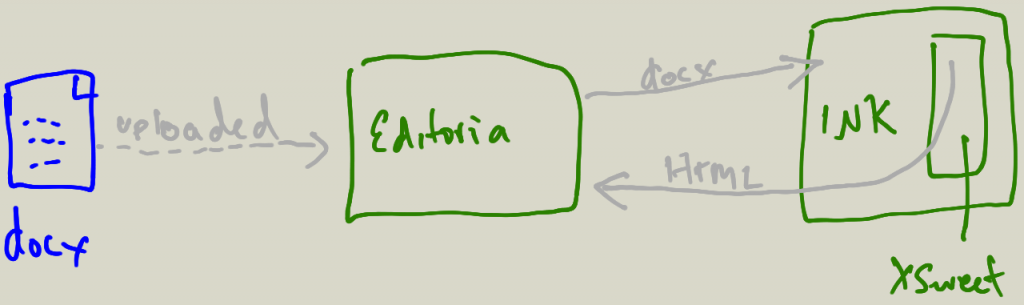
So, on the ingest stage it looks like the following to the user:
user logins in to Editoria
they create a new book from the book dash
they vlivk on the new book
from the book builder interface they choose ‘upload multiple word files’ or ‘upload word’.
they select the word file(s) from a system dialog
these files are automagically appear ‘in the book’ and can be edited
note : in the case of multiple docs files, if the files have been named according to a simple convention, Editoria will create each new chapter and automatically populate the structure of the book and load the content in the right place
From the tech side the following happens:
when a word doc file or files are selected, the files are sent to INK via the INK API, with a request to convert to docx using the XSweet steps
INK runs the docx file(s) through the XSweet steps, creating HTML
when the job is done, INK signals Editoria that the files are good to go
Editoria grabs each file when it is ready and puts in the the right chapter, creating the chapter if multiple word files are uploaded at once
So… we had to build all of the above. First, INK exists because, crazy as it sounds, we could not find an elegant open source pipeline manager to manage jobs like this. So we decided to build from zero. In addition, which also sounds crazy, there is not a comprehensive open source library out there for converting docx to HTML that was easy to extend or customise for different use cases. We certainly know of many scripts for docx->html (many are listed on the XSweet site), but they are either unmaintained, or difficult to extend. So, unfortunately, we had to build that also.
Editoria App
The Editoria App is what people think of ‘as Editoria’. Everything the user interacts with is, on the surface, Editoria interfaces in the browser. However, Editoria comprises of 3 main parts:
PubSweet
the Editoria interfaces
Wax
PubSweet is the ‘under the hood’ CMS that enables apps like Editoria to be built on top. PubSweet is a Node/React application written entirely in Javascript and it sits on the server and provides a ‘wrapper’ for the Editoria interfaces. You can think of PubSweet as a ‘headless’ CMS that thinks like a publishing system. Once again, when we started (and still today) there was nothing out there that could realise multiple publishing use cases, as diverse as micropubs, books, journals, content aggregation etc, built on top of the same CMS. So we had to build it ourselves. PubSweet is now pretty mature and indeed supports multiple publishing platforms – at last count I think that totals 6 platforms built on top of PubSweet (and it is early days).
The Editoria interfaces are the ‘web pages’ that make up the Editoria application. This includes the dashboard, the book builder etc… these are all custom code written on top of PubSweet to realise the Editoria use case / platform.
Wax is an online editor, it is so sophisticated we prefer to call it a web-based word processor. It is actually an Editoria interface, except that it is so complex and such a critical part of any online publishing tool, that it is a product in its own right. Nothing like this existed either, so we built our own (typical WYSIWYG editors are not sophisticated enough for the publishing use case).
PagedJS
From Editoria, you can press a button and have a book appear in the browser. If you print from the browser, you will then get a PDF ready to take to the printers with all the typographical bells and whistles that books need. It looks magical. We currently use Vivliostyle for this but we have hit many limitations with the software. We reached out to the org that produces the code but they weren’t ready to collaborate to improve the product. Hence, unfortunately, we had to build our own. Soon we will replace Vivliostyle with this new offering. The speed of dev has been incredibly fast on paged.js (working title) and so watch this space for some exciting news.. there are some early demos in the pagedjs repo if you are interested.
Summary
…. So, as you can see, Editoria is more complex than it appears to the eye of the user. Also, the crazy thing is that most of these parts should have existed already, but, crazy as it is, they didn’t exist. There has been no full page, open source, editor out there gives the source control and extensability required for the publishing use case. The docx conversion tools available do not yet do a good enough job of the conversion, and are not easy to customise. There is no headless CMS that ‘thinks like a publisher’ and would help us build Editoria; and we had to create a pagination engine (paged.js) because the one open source option couldn’t give us what we needed and we failed at trying to help them improve the product.
Its not like we wanted to build all this, but the sad fact is for the publishing industry the web is still an innovation they haven’t embraced (except as a distribution medium). So while all of these parts (or many of them) should exist, the sad truth is they did not exist. We did a pretty good look around to see if we could save ourselves the effort before embarking on these projects. We did, for example, bank on Substance Lens Writer for our editor, but it was not maintained and proved unstable, and our eventual assessment was that it was better to start again – hence Wax. We also have gone a long way down the path of using and promoting Vivliostyle, until it became apparent that neither the technology nor the technology providers could get us to where we needed to be… consequently, after implementing Vivliostyle (it is still baked into Editoria) we started a new approach to this problem – Pagedjs.
So, we had to build all of this ourselves… the good news is, that all of these moving parts are reusable in other scenarios… so you can take whatever you like from the above, and add it to your own product and hopefully that will fuel the publisher sectors ability to innovate and transform their products and workflows.
Strange days… We use Vivliostyle at Coko, but it has been a fraught experience. Vivliostyle is an open source javascript library for automating typesetting of HTML/CSS content. We use it in Editoria for automating the production of book-formatted PDF from an HTML source. You can read a little about how this works here.
The source code is open source, but it was apparent from the beginning that Vivliostyle-the-company were not into collaborating unless we could pay. We tried very hard to get inside their bubble and contribute, but were pretty well cold-shouldered. We offered meeting resources for community building, and developer and designer time, to help move it all on. Coko went to quite some effort to promote what they were doing (eg https://www.adamhyde.net/why-vivliostyle-is-important/ + the posts on PagedMedia.org by Coko’s Julien Taquet. But they wanted none of it. I was also pretty sure they were being paid to extend Vivliostyle but not putting those changes back into the common pool. Fauxpen, as they say.
We weren’t the only ones to feel things were odd – I spoke to many people who felt the same way and who had had similar experiences. As a result, to de-risk ourselves I founded another initiative – pagedmedia.org – so we would not be reliant on Vivliostyle. My thoughts on this were very similar to what I recently wrote about editors ie. if an open source community is not open to building community, something is wrong and you should carefully consider whether you should be involved with them. They could at any time change direction, and if there was no community at play, then you could be left high and dry. Sometimes you have to make hard decisions and we made it…
No one really wants to build an automated typesetting solution from zero unless they have to. After trying to solve this problem for the last 10 years or so (with open source) I wanted to see it done…so… sigh… if it (unfortunately) wasn’t going to be Vivliostyle after all, then what choice did I have? So I committed to this new endeavor (which is going very well! some cool updates soon) and we launched at MIT Press earlier this year with a community-first approach. We are, similarly, currently considering our choice of editor libraries because of similar concerns.
So, as it happens, I guessed it right and moved at the right time… as that is exactly what has happened with Vivliostyle. A few weeks ago they mysteriously posted a new company name (Trim-Marks Inc) and site under the old URL and pointed vivliostyle.com to vivliostyle.org. No further information was forthcoming. Now there is an announcement about it all on vivliostyle.org… you can read it here: https://vivliostyle.org/blog/2018/03/26/a-new-beginning/
Essentially Vivliostyle-the-company went off to form trim-marks.com.
I have no idea what they do, but it isn’t open source. Vivliostyle, the open source project, is apparently continuing under the new .org site, led by Shinyu Murakami and Florian Rivoal. I know them and like them both. Very talented and committed people. I met Shinyu when he was thinking about how to tackle this problem – we met at Books in Browsers a long time ago and talked about strategies for solving this problem. So, I wish them all the best, but I retain some initial skepticism – until I see them actively building community, I won’t be terribly interested in going down that path again… They are good folks, so who knows… fingers crossed (the more projects active in this space the better).
I’ve been in the business of trying to work out how to get Publishing (capital ‘P’) into the web. From the start, there have been some ‘big ticket’ items that have needed to be solved. Some are more urgent than others, but by and large we are cracking these nuts one by one. I have considered for a long time the big 4 to be:
MS Word to HTML conversion
an open source web-based word processor
paginated output via the browser to print-ready copy
in-browser designer
1,2 an 3 are the ‘now’ critical items, number 4 is necessary but a little further down the line. Thankfully, at Coko we are solving these first 3 problems. To solve (1) we are building XSweet, a comprehensive (open source) XSLT conversion suite for converting MS Word to HTML. We are also building Wax to solve (2), Wax is an open source web based word processor based on the Substance.io libs. And for (3) we are using Vivliostyle for in-browser rendering. Number 4) is still on the cards.
Interestingly, the pagination technology (3) might need re-evaluating since pagination will eventually be required for the editor and the in-browser designer.
While pagination inside a web-based processor is not critical for publishers, it is critical for authors and small offices etc and if we are going to get publishers to use a web-based word processor then it would be better that they share infrastructure rather than sit on their own island of technology ie. eventually we need authors to use these tools too. By sharing infrastructure I don’t mean they need to use exactly the same tools, they just need to use compatible tools. So, eventually, we need to migrate authors into the web. It is not critical now, but over time, as the workflow for authors and publishers inevitably becomes more integrated, it will turn out to be necessary.
For in-browser design we need pagination support also so we can work off a single source for the content and then design in the browser to output to the various formats publishers need. Think Gimp or InDesign in the browser. It’s not as far away as it might sound, but to do this we need to be able to paginate inside the browser and have that update with live style changes to CSS.
So far, we are solving the big ticket issues 1-3, but for the next stage of changes we may need to change the tools we use for pagination so we can live-update content and styles and reflow in an editor and in-browser designer. That may mean we to start looking for a different pagination solution.
The past two posts I wrote on this topic looked at defining the difference between a text editor and a word processor. The posts in this series represent me ‘thinking out loud’ about what word processing needs to evolve into in the age of the web. So far, in my opinion we haven’t seen an evolution from the desktop given that Google Docs, as the premier example, looks and thinks pretty much like MS Word.
For this post I’m going to look at the first obvious visual differentiator between a text editor and a word processor. You notice this immediately when you open a word processor document, and you are skilled at manipulating its characteristics, but you might not think of it as a ‘feature’ as it is so present to almost be invisible – I’m talking about pagination. The first thing you notice when you open an existing document or start a new one is pagination, the boundaried space that makes your digital interface look like a piece of paper. Its not the sort of thing we think of when we think about a ‘feature’ but it is probably the strongest differentiating characteristic that separates the two categories of software.
Pagination
Why do we need pagination in a word processor? What purpose does it serve?
There are a number of purposes. Picking them off one by one:
navigation. We can generate navigational schemas if the content is paginated. These can either be inline references to page numbers or it might be in the form of a table of contents.
position in document. Related to (1) above – knowing what page number you are on, and the total number of pages, is an important function of pagination.
boundaried read/write space. In the print world it has long been considered a best practice to have between 45-75 characters per line (commonly abbreviated as CPL). Various arguments have been made that this number is optimum for speed of reading and comprehension (although I haven’t found any research about this, if you know of any please let me know!). Robert Bringhurst, the author of The Elements of Typographic Style (a goto for many book designers), goes even further to suggest the ideal number of characters for optimum legibility is 66. That is pretty specific. As it happens writing environments have always been around this range. Typewriters, for example, were generally around 80-90 CPL, teletype around 70-72 CPL, and this WordPress editor in which I am writing this has 72 CPL. Bounded spaces in Word Processors generally limit the CPL to around the same amount. Google docs is somewhere around 70-80 CPL, and LibreOffice is around 80. The area of 70-80 seems to be quite standard for Word Processors but laptops and larger screens can easily accommodate hundreds of characters per line so we need a bounded space to limit the CPL. Pages are a handy, and familiar, way to boundary the text area to limit CPL.
‘how much’ metrics. Word count is one indicator of how long a work is, but page count is often used both formally (ie. funding applications or job applications require a fixed number of pages) and intuitively by the writer to get a sense of how long their work is as they create it. Academics, in particular, often think of a works length in terms of page count.
expected ‘look’. Placement of headers and footers, page numbers etc are added to a document to make it conform to an expected look and feel. A letter of application for a job, for example, needs these elements as they are generally considered to add an air of formality to the document. This is obviously inherited from the age of paper but interestingly we still do this regardless of whether the content is printed, distributed as a word processor file, or rendered to paginated PDF.
design canvas. Interestingly, word processors are used as design environments. Think of the times you have played with fonts, tried to get the right spacing between a heading and the following paragraphs, added images and tweaked with the text flow to make the image sit well in the page etc. A boundaried ‘page’ presents a known canvas within which we can apply our implicit document design skills honed over many years of using word processors.
to print, or the possibility of print. There always is the possibility that the documents we create will be printed. If not by us, then those we share the documents with. We implicitly understand that if it looks fine on the screen then anyone printing it ‘sometime later’ will get a tidy outcome. In many cases we don’t think about it much, it’s more of an implicit assumption that covers us ‘just in case’ it is printed.
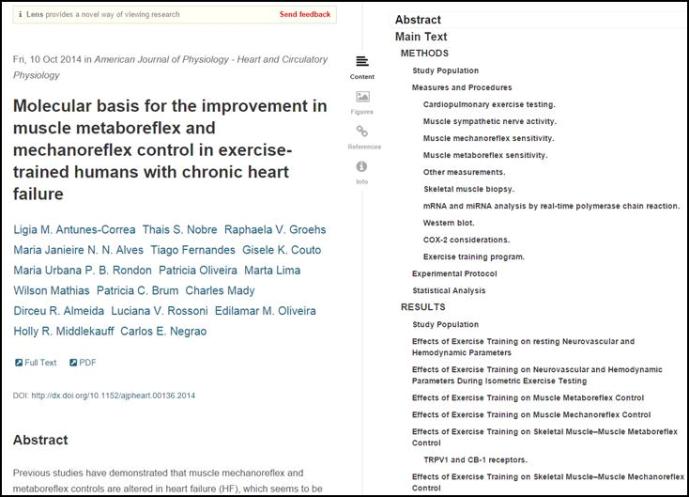
So, what to make of this. First, pagination is pretty essential to how many people use a Word Processor. It’s hard to think we can do without it. We might be able to achieve some of the above without a page paradigm. We could probably reasonably easily overcome the first 4 issues above – for example, we could provide word counts + ‘approximate page count’ indicators to give an idea of ‘how much’ content there is, provide a hierarchal navigation view of headings instead of page numbers for navigating around a document and as a ‘table of contents’ as Google Docs and eLife Lens (based on Substance.io) does.
eLife Lens. Table of Contents on right
In addition, there are a number of ways to indicate the reading position in a document that do not require page numbers – check out this example (thanks to Julien Taquet for this tip), and it is also possible to limit the CPL without providing page boundaries in the design as Wax Editor does.
Wax Editor
However…the show stoppers really are the last 3 from the list above (to summarise again) –
expected look – many documents are expected to have page-based design elements regardless of whether we actually print them
design canvas – we know how (from years of banging around on ugly Word Processors) how to design documents using Word Processors, and
to print, or the possibility of print – we never know when something might be printed so knowing it looks ok on a ‘virtual page’ is a nice guarantee that it will look fine if printed.
Are we stuck with pagination?
It is difficult to argue that we could easily, or completely, throw away the page based paradigm based on these three items. So…does that mean Word Processors will be forever tied to the rather ugly page that you see floating like an existentially blank canvas every time you start a new document? Will web-based word processors forever be stuck in this paper paradigm?
My argument is no. We don’t need the page. Or at least, right now, in many use cases we can throw it away. The examples I used above provided clear cases where we need to directly correlate what you see when you create a document to the final result – whether for screen-based display, or print. But not every use case is like this. What is one of the biggest situations where you do not require a strict co-relation like this? Publishing.
I think I might hear you thinking ‘huh’? Afterall, if there is one industry that actually does require pagination it is the publishing industry (thinking in terms of the book and journal publishing sector for now, excluding newspapers, magazines etc).
That is true. However, the publishing industry doesn’t distribute to their readers a journal article as an MS Word file, or a book as a directory of MS Word files. They distribute unpaginated (usually) HTML files on the web, paginated PDF, EPUB files with various approaches to pagination, or paper. They generate these files by sending their source files (often MS Word) to an external vendor or in-house designer, who imports them into any number of design environments and converts this into the required formats.
Pagination comes ‘at the end of the line’ so to speak. Hence, unlike the typical home or office environment, there is no 1:1 correlation between what you see in word processors and what is finally distributed. So the needs of a word processor for a general user might be different to the needs of publisher. That, in itself, is pretty interesting. What if we could imagine specific word processors for specific use cases….
However, you will notice that word processors take a one-size-fits-all approach. We don’t have one word processor for book authors, one for publishers, one for lawyers (etc etc etc)…that is not to say we don’t need to differentiate these use cases and look at the specific needs of each. Interestingly, developing web based environments takes a lot less work that developing desktop applications and things have moved on since MS Word first hit the shelves. The web gives us substantially more room for modularity and customisation. With web-based word processors, every feature can be a configurable option. Don’t want or need track changes? That’s ok… remove it… Need a Diacritics interface? Easy… add it. Don’t want pagination? Remove it.
The point is, we can start building web based word processors that are highly customisable and can be configured to meet individual use cases. We haven’t seen that so far in word processing, Google Docs has also chosen a one size fits all – the only real difference here between GDocs and MS Word is that their ‘all’ is a smaller group. But that doesn’t mean we can’t do it if it makes sense. Technically it is very feasible and, as it happens, it’s the approach we are taking with the Wax Editor.
So, let’s imagine we have our own word processor made specifically for publishers. Do we need pagination? What role does it play in publisher workflows?
It is true that relative to the total number of publishers out there I’ve seen inside a small % of publishers’ workflows. However, interestingly, with each new publisher I work with I am seeing, more or less, the same workflows and from what I have seen so far, MS Word files are used widely to support a kind of early page-prep workflow. Publishers check and improve the content of course, but they also make sure certain elements are in place that will affect the final design. They check, for example, if all paragraphs are correctly indented. They check if images are in the right place, they check if headings are marked correctly and that no levels have been jumped etc. These all affect the final paginated outcomes, but none of this requires working within, or manipulating, pagination as it appears in the word processor. Checking the results of pagination (including page numbers, running heads, widows and orphans etc) comes when publishers do their page proofs ie. when they check the PDF before print or distribution (sadly, many publishers don’t check EPUB very thoroughly but just accept that it ‘is what it is’). Publishers don’t currently check the results of pagination, as it will appear in their final distributable form, in the word processor. So pagination in the word processor, at least on this point, is a little redundant.
So… my point is, if we get down to it, pagination features in a word processor are not required when you are working inside a publisher to prepare a document for publishing. We could instead use an unpaginated environment with a navigation based on document structure (not pages), word count as a metric for how much content there is, and simple constraints on CPL that do not look like a boxed, bounded, page.
But…what about the need to print on your office or home printer? Interestingly, I think this gets to the crux of the matter. Unbounded, flowable text, in a word processor does not mean you can’t print. It only means what you see in the word processor won’t have a one-to-one co-relation, with regard to pagination, to what is printed. But the big question is – is this acceptable to publishing staff? Can we get them to let go of thinking, a product of many years of legacy word processing user experience design, that the pagination in the browser ‘must’ correlate to the pagination that comes out of their home or office printer. My experience designing such systems alongside publishing staff leads me to believe his is possible. In fact, the University of California staff designed the Editoria system which features the Wax Editor which displays content sans pagination. The challenge is – it is up to us to show them that throwing pagination out works in their favour.
Before I go on to why throwing out pagination can be a convincing argument, I want to indulge in a rather lengthy aside and state that throwing out pagination is not the same as ‘not printing’. The results of printing from an ‘unpaginated’ form in a web-based word processor can be beautiful and a more consistent experience than printing off ‘any old’ word file. This is because we can use CSS print styles to make beautiful looking results that come out of your home printer. The point is only that the pagination will not correlate to what you see in the word processor. But you can have other things – for example, you could render pages for printing at any time that look like your final output. Quite probably this statement is news, or confusing, to you. It needs extensive explanation. But the idea, in basic form, is that content in HTML based word processors can be shaped by CSS into paginated form in the browser. This process allows you to automatically format the content into book or article form including running heads, page numbers, widow and orphan control, multiple columns (if desired) while also generating the table of contents and even indexes. This can be achieved, for example, by platforms that leverage tools like Vivliostyle. I’ll get to this in subsequent posts, maybe even the next one (in the meantime, you may wish to read this). For now, I want to leave this issue to the side but make the simple point that content that is not bounded by a page in the word processor can still be printed and, further, the results can be more beautiful and consistent than what you get by printing from Google Docs or MS Word today. However, the process of printing will feel slightly different because ‘how you print’ will be to first render a view that is conformant with your printer and then print. It’s not much different to how it is done now because this is how print-preview works in word processors today. When we print, we commonly choose the page format at print time, although most of the time we leave it at its defaults because we know that what we have seen in the word processor is the same as what will come out of the printer. ‘The new way’ would mean you will need to pay more attention to the second step – checking the formating in print preview before printing. Which is why I emphasise that the process will feel slightly different, the actual change in behaviour is minimal, if anything at all. But it would be a mistake to conflate user experience with user behaviour. The experience of the software is nothing to be brushed lightly aside, it can be a very strong impediment to new ways of working. So how things feel need to be taken into account. Which is why I think, ultimately, we will need other arguments to help many (not all) ‘get across the line’.
Which brings us back to the question – what is the advantage of not having pagination? If we can do away with it we have far more options for making beautiful experiences. The bounded page that all word processors commonly present is, in my opinion, hideous. It constrains how you construct a user interface, how people feel about that interface, and how people work. If we can free ourselves from it I think we open the door for much better experiences and innovations on what a word processor can do and be which also means, in the publishing industry, we can start innovating around word processor workflow.
Additionally, removing pagination from the word processor in publishing workflows is better aligned with how publishing works. Publishing formats do not share the same pagination. An EPUB page is not going to be the same page as the content displayed on the net, in a Kindle, in a PDF, or in a book. Might as well let that one go. If we need pagination at all, it needs to look like the final output and we need to get it earlier in the workflow than what currently occurs. Currently, publishers only see this after the content has been through their workflow and gets ingested and output to various formats by a designer, production staff, or external vendor. However…. HTML based word processors that leverage tools like Vivliostyle (mentioned above) enable the content to be paginated to all these formats on the fly. That means you can have ‘page proofs’ anytime you want in the process. So, letting go of pagination in the word processor, coupled with the ability to create these various paginated forms at any time, is an advantage to publishers. Publishers don’t need to wait for page proofs from a designer before they can tweak elements in the content (eg placement of images) to make the pages flow better in the final output. They can render, check, and tweak at any moment. From this point of view seeing one kind of pagination in the browser, especially one that conforms to a generic printed page coming out of the office printer, as it does now, is counter intuitive. But, I don’t expect many publishing staff to accept this by argument alone. We have to first get most people to experience this, and other benefits of a pagination free experience in a word processor, before they can start moving the way they work forward.
My conclusions? Well, I think it will be a while before we can convince the general user to drop pagination. But web based web processors allow us to build much more customisable experiences and avoid the ‘one size fits all’ approach. We can build to meet publishers’ specific needs and it is because of this that I believe we can produce software that will convince publishers to make the conversion sooner. This is because we can make the experience for them better if we drop pagination. The pages, which they look at for hours on end, can be cleaner, easier to read, and less tiring over long periods of time. We can also start using space more effectively by removing borders around pages (with their attendant inner and outer margins). And lastly, I think it is important to remove pagination from word processors for publishing workflows because it helps disambiguate what you see in the word processor from the final, designed and paginated, results. This latter point has positive knock-on effects that I will come to in other posts. Couple all this with the ability to ‘paginate on the fly’ (so to speak) at print time (for domestic/office printers) or to generate ‘page proofs’ of many target formats, and we have a winner.
The Cabbage Tree Book pictured above was made using entirely HTML as the base file format. It was then rendered from HTML to PDF using Vivliostyle and printed and bound. Julien Taquet did this work and he has written the first of a series of blog posts about how this was done here:
Yes, here it is. The 0.1 version of the book on the open source collaborative product development method known as…. The Cabbage Tree Method. It’s an early release just for you. I’d love comments (use the comments on this post for this version).
Vivliostyle advertises itself as a “publishing workflow tool.” It is a great tool but this isn’t a terribly accurate or descriptive byline since publishers can’t really use it without changing everything else they do. Hence my preference to refer to it as an HTML pagination engine (although I used to refer to this process as Browser Typesetting). It can be part of a publisher’s workflow but only after they have transformed everything else they do to an HTML-first workflow.
On this point, I think Vivliostyle have their sales pitch wrong but it is hard to know how they might do it better since Vivliostyle imagines, as do many other tools, a radically different way of doing things to how publishers operate now. Vivliostyle is one necessary part of an approach that is, in effect, a paradigm shift in how publishers work. This ‘new way’ of working is exciting and transformative, but it is also hard to capture paradigmatic changes in a few catch phrases. So, to understand the value of Vivliostyle, you first have to understand how publishers work now, why it is a terrible way to work, and what HTML-first workflows can offer. Once you understand that, you can see how exciting Vivliostyle could be for publishing.
So… what does it do? Vivliostyle is the latest in a long list of tools that, among other things (more on these in later posts), can enable the transformation of HTML to PDF. These tools have been typically used to produce PDF for printing – book formatted PDF. There are a few of these softwares out there but most are proprietary and only a handful of them have been Open Source (notably BookJS that I was involved in a long time ago, and CaSSius). Vivliostyle is the latest in this family tree, the root category of which I would describe as an HTML Pagination Engine.
What it does is this – it takes an HTML file and paginates it. It flows the HTML through the ‘boxes’ (pages) you have defined and lays the content out nicely in each box, one box after the other, flowing all the content through it with the right margins (and more, see below). So instead of scrolling through the web page, you page through the document on screen. Vivliostyle converts the HTML into ‘pages’. It is an HTML pagination engine.
It is then possible to do a lot more with these pages, including adding page numbers, using CSS (the style rules used by browsers) to define the look and feel of text and images(etc), adding headers, notes and footers etc. In other words, you can add to each page everything you need to make the result ‘look like a book’.
You can do this transformation in the browser because Vivliostyle is written in JavaScript. If you want to see this in action, check out their demos page. For example, look at this page showing the raw HTML of a book by Lea Verou (published by O’Reilly), then open this page (give it a minute to render). Now right click and print (best in Chrome or Chromium browsers – you may need turn margins off and background images on when printing). The result should give you a one to one co-relation of the paginated content in the browser (which is HTML) to the paginated print-ready PDF.
Since the browser can also print PDF, then you can take this newly styled ‘book looking’ HTML and print it to PDF from the browser. From this, you have a book-formatted PDF that is ready to send to the printer to be printed and bound. I’ve worked this way for many years and printed many books this way for organisations from the World Bank to Cisco. The system works and the printed books look great. Vivliostyle is, at this point, the most sophisticated open source tool for doing this.
It is pretty amazing stuff. From HTML to PDF to printed book at the press of a button. Magic. This process is also catching on. Hachette produce their trade paperbacks using an HTML-to-PDF rendering engine with styling via CSS. So it is no longer a process reserved for small experimental players.
So, why is this interesting? Well, it is interesting almost without an explanation! Transforming HTML in this manner seems pretty magical and it’s kinda neat just to look at the demos and marvel at it. However, the really interesting part comes into play when we start talking about workflows. This is where Vivliostyle can be part of transforming publishing workflows.
As a publisher, if you were to take Vivliostyle ‘out of the box’ it would not be of much use to you. How many web pages do you have that you want to turn into PDF? Not many, if any. How much of your book or journal content in your current workflow is stored in HTML? Probably none. In all likelihood, HTML in your business is restricted to your website and, perhaps, EPUB if you produce them (EPUB is just a zip archive containing HTML files and some other stuff). But in most publisher’s workflows the EPUB is an end-of-line format. Publishers take the completed copy in MS Word, or (sometimes, regrettably) PDF, and send it to a vendor (typically in India) to transform into EPUB and send back. So chances are, HTML is not the format being used as the basis for your book or journal workflows (apart from possibly being an end-of-line format).
As a publisher, you don’t have manuscript copy in HTML, so Vivliostyle is not going to fit snuggly into your workflow. In order to utilise it, you need to transform the way that you work. You have to start working in HTML or, more difficultly, work in some format that can transform into a very tightly controlled HTML output so that Vivliostyle can work with it.
I don’t like the latter style of workflow. This is where you work in something like XML (of some sort) and then transform to HTML at the end of the process. It’s ugly workflow, not friendly for non-techie users and typically full of workflow redundancy. If you want good HTML, then just work with, and in, HTML. This comes with additional benefits since from good HTML you can get to any format you want PLUS you have the advantage of now being able to move your workflow into the browser. And this is where Vivliostyle fits into a toolset, an approach, that could transform how you work – the HTML-first production environment.
The current ‘state of the nation’ in publishing is pretty terrible. Most publishers use MS Word docx as their document format, and Track Changes and email are their primary workflow tools. This means that there is a single document of record – the collection of Word files. These are shareable, in the sense that you can email people copies, but you cannot have multiple people simultaneously accessing them at the same time. In effect, the MS Word files are like digital paper in the worst possible way. There is only one ‘up to date’ version and only one person that can work on that version while they hold onto the files. There is no easy way to follow a document’s history, revert to specific versions, or identify who made what change when. Further, there is no inherent backup strategy built into standalone MS Word files. Everything must be done manually. That means organizing the files in directory structures with naming conventions that are known by only those in the know (since there is no standard way of doing this). There are also problems with email as a collaboration tool. Did it send? Did they get it? Did they get the right version? Plus there is no way of understanding the status of the documents unless you ask via email or there is some other system that is manually updated for status tracking. The system is not transparent. Further, changing workflows when using systems like this, even for small optimisations, is quite difficult and the larger the team the more difficult it gets.
Additionally, using Word and email like this is really placing unnecessary gateway mechanisms on the content. If I have the up-to-date versions then you can’t have them or work on them. There is really only one copy and only one person can work on it. That makes for linear workflows and strongly delineated roles. No one can ‘jump in and help’ and it is very difficult to alter the linearity of the process or redistribute the labor to achieve efficiencies.
If publishing is to move on, then workflows need to migrate to the browser. With browser-based workflows, there is no need to have multiple copies of the same file, versioning is taken care of as is document history, it is easy to add and remove people from the process, and labor can be better distributed over both roles and time to create more elegant, efficient, workflows. I wrote about this in an earlier post and will write more in posts to come since there is a lotmore to it. But suffice to say that publishing workflows to the browser is a little like ‘sucking all the gaps’ out of the current Word-email workflows (plus a whole lot of other benefits). No more checking your Inbox while you wait for status updates or someone to send you the files so you, and you alone, can work on the next little part of the process while everyone else waits. Additionally, there can be full transparency as to what needs to be, has been, and is being done (and by whom). There is the opportunity to break down larger tasks into smaller tasks and have them all in play concurrently. There is the opportunity to share the same tools and hence enhance communication and redistribute the work to where (who) it makes most sense. There is so much to be gained.
This is not to say that browser-based workflows are ‘anything goes’ workflows (which is what most publishers think this way of working amounts to). You can still assert rules of who has access and when. But… in my experience, when you migrate workflows to the browser then publishers start rethinking how they work and you often hear comments like “but we don’t need to do it like that anymore’…They then start designing radically better workflows themselves.
So, the point of all this is that Vivliostyle by itself does not achieve this. It is not, in itself, a workflow tool for publishers. You first need all the other things that enable an HTML-first workflow to be in place and once they are there, then you can utilize Vivliostyle to transform the HTML (at the push of a button) to the PDF you need for printing. That is the radical improvement Vivliostyle can offer. Cut out the file conversion vendors and render the content according to templated style sheets (automated typesetting can produce beautiful results). This means you can check what the book will look like at any moment, plus the CSS stylesheets you use can also be included in your EPUBs (also rendered at the push of a button since the original content is already in HTML, the content filetype for EPUB) so your printed book and the EPUB look the same.
So, Vivliostyle is a necessary tool for HTML workflows and with an HTML workflow you will radically improve what you do.
This is why Vivliostyle is important to publishers but you cannot consider it isolation. You must consider it with regard to migrating to an HTML first workflow. If you migrate to this kind of workflow then not only will you experience the efficiencies described above but your organisational culture will be transformed and the types of content you can then produce will become a lot more open ended. This is the vision that Vivliostyle, and other tools that enable HTML-first workflows (including those developed by UCP and Coko), are imagining and building towards.
Dear reader, out of principle, I do not use proprietary social media platforms and networks. So, if you like this content, please use your channels to promote it – email it to a friend (for example). Many thanks! Adam
Editoria is a software platform Coko has been working on in collaboration with the University of California Press and the California Digital Library. It is the first product that we have taken through the Collaborative Product Development process and it is looking pretty good!
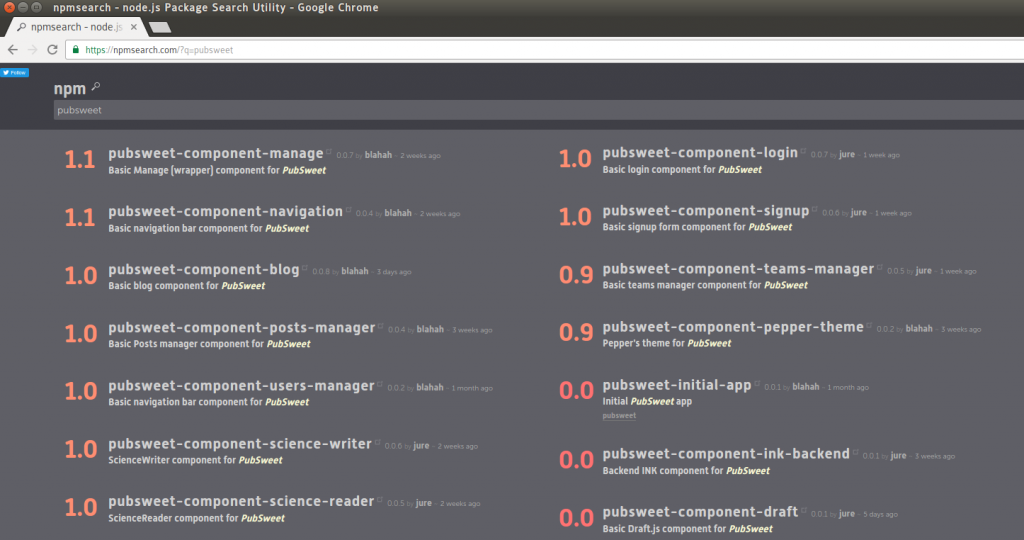
Editoria is built on top of PubSweet, which means there are separate frontend components integrated with the PubSweet core application. These frontend components are available as open source (MIT) in the Coko gitlab repositores. They have not yet been nicely bundled for distribution but this will be available soon as we have done with many other PubSweet components. You can see these if you search the NPM repository online:
PubSweet components on NPM
The frontend components enable 3 workspaces, a book dashboard, the book builder, and an editor. This follows the general pattern of book production platforms I have been involved in since FLOSS Manuals in 2006 or so. This kind of design places the structure of the book itself as a central workspace which gives not only an overview of the structure of the book but of all operations concerning the book. I think this is a good general strategy as I have previously written about here and others, including Micz Flor of Booktype, have also written about.
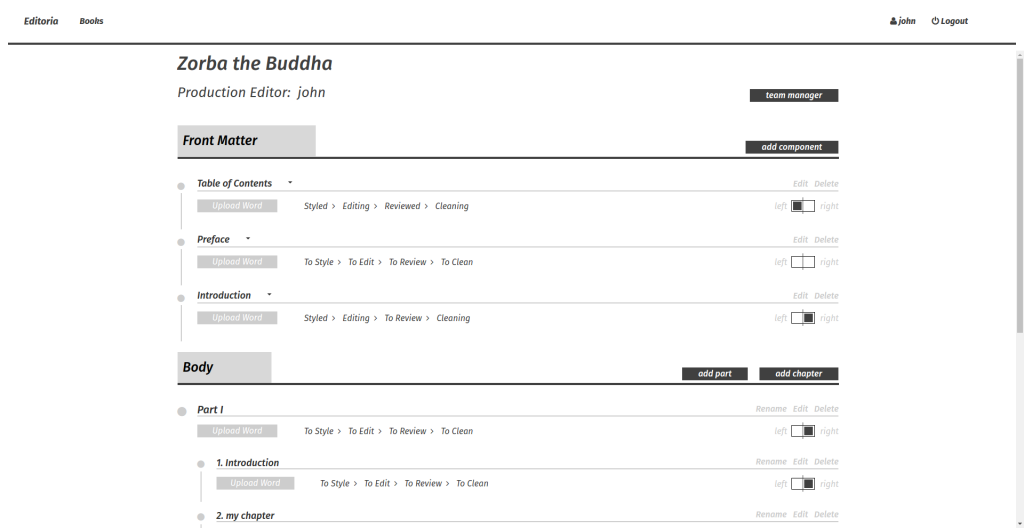
In Editoria, this central workspace is known as the Book Builder, and the following is a screenshot as of Nov 19, 2016.
Editoria Book Builder
It contains a lot of punch but is pretty simple to understand which is the ideal since you really want to get an understanding of the status of a book at a glance.
Before looking at this in detail, first a little disambiguation – we are following the Chicago Manual of Style for the naming of items. In this case, each of the front matter, body and back matter sections are known as divisions. Items within each of these, be they a table of contents, preface, glossary, appendix or chapter (etc) are known as components. A part is a collection of chapters (technically a part is also a type of component).
In the Book Builder we have the following:
Front matter, body, and back matter divisions
A list all book components (chapters/parts)
Status (4 status markers for each component, each with 3 states) – from the Book Builder you can set a status for each component. These are currently hard-coded (but may become configurable at a later date) to the following 4 items with 3 states each: To Style, Styling, Styled To Edit, Editing, Edited To Review, Reviewing, Reviewed To Clean, Cleaning, Cleaned Clicking on a status item moves it to the next state. These states are both indicators of the status of a component (what needs to be done, is being done, or is done) and they are connected to access permissions. When, for example, a chapter is marked To Review, in this case those that are Authors (see Team Manager below) can access the chapter in edit mode and review changes and make alterations as requested by the Copy Editor.
Upload word (converts to HTML, yet to be wired in) – we are working on the MS Word-to-HTML converter which will shortly be integrated. This will enable the upload of MS Word files into the system which is critical since all books come to UCP and CDL from the author(s) to Acquisitions to Production in MS Word format. It is the Production department that uses Editoria.
Tools to add, rename, and delete components – it is possible to add new components dynamically, rename them and delete them. It is also possible to drag and drop these components to reorder them.
Pagination markers – these indicate whether the component should be left or right breaking when paginated for paper book production. A click on the left or right pagination boxes changes the state. This state will later be important for exporting to PDF via the open source Vivliostyle HTML-to- PDF renderer.
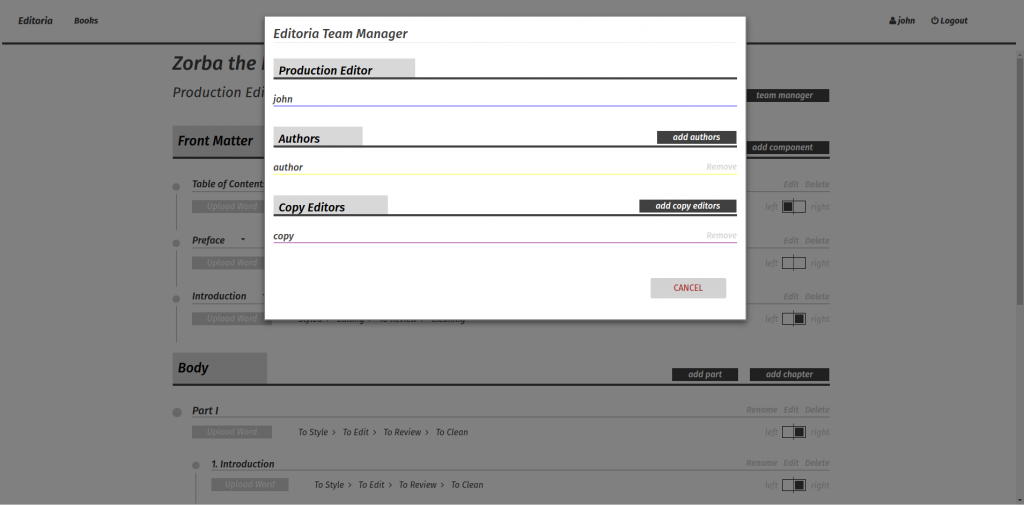
In addition to the above, there is a team manager interface available from the Book Builder:
Editoria Team Manager
Through this interface, you can add team members to the book. This affects access permissions. The team manager, in this case, has three roles – Production Editors, Authors, and Copy Editors. These are all in themselves configurable within the admin side of the system so it is possible to have different types of roles for different organisations (in my experience role names and duties differ quite a bit between publishers).
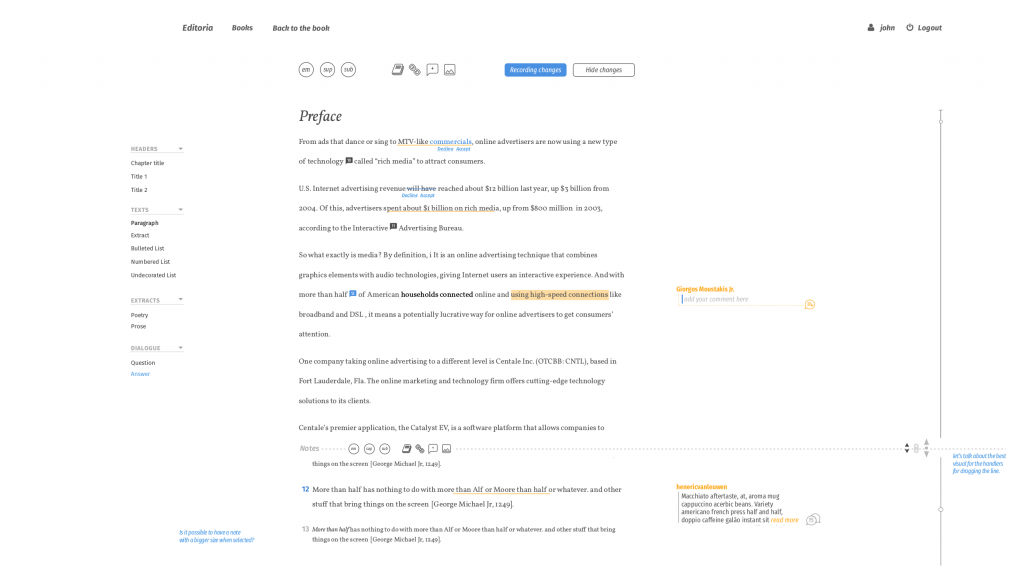
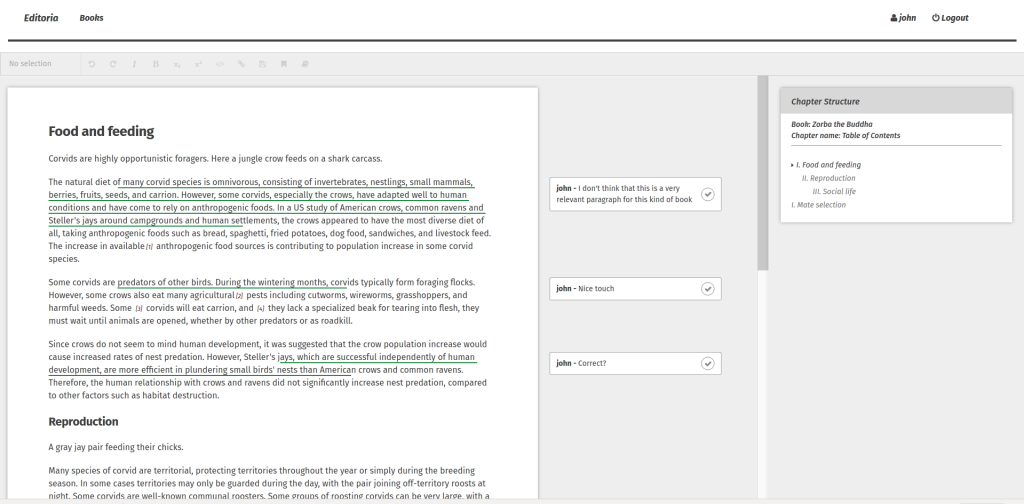
In addition, you can press edit next to any of the components and it takes you through to the editor for that component:
Editoria Editor
This editor has been built with the open source Substance libraries. To build this, we have first conducted an audit of the element types CDL and UCP require within a book. By this I mean we looked at the types of content UCP and CDL already has within chapters (components). For example, they require (as most books do) headings of various levels – Heading 1, Heading 2, Heading 3 etc. In addition, custom elements are required like an Extract, Block Quote or Dialogue etc. Our mission is to capture all these different content types and custom build these into the editor so that you can highlight a part of the text and apply the correct element type. This is extremely important when it comes to outputting the book since we need to know how to style each of these elements to the chosen design.
We also have all the regular features in the editor such as the ability to edit the document, add and remove bold, italics etc. We also have a number of additional features that were designed by the UCP Production Staff during our Collaborative Design Sessions. These features include:
Notes management – it is possible to add, edit, and remove notes. These notes correspond to end, book, or foot notes in books. In the editor, they are displayed at the bottom of the page while in the output they may appear at the end of the page, chapter, or book so we refer to them more generally as just notes in this environment. You can add notes and edit them through an overlay so that this can be done in situ (without having to scroll to the bottom of the page).
Comments – sometimes referred to as annotations. It is possible to select a portion of the text and add a comment. These appear in the margin. It is then possible to reply to, and resolve, these comments. This is intended to be used by Copy Editors and Authors for discussing and resolving issues in the text. For those that are interested, it took about 3 weeks to develop the annotation feature which is pretty quick.
Chapter Structure – the structure of the chapter is currently displayed at the far right of the page. This lists all headings in a nested fashion. Clicking on any heading will scroll the page to that position. It is intended to give a quick overview of the structure of a chapter and to enable fast navigation. It can also be used to check the headings follow the require d nesting conventions.
We are building in a few additional features in the editor before we trial books through the system. These are:
Images – the ability to add and remove images in the book
Spell check
Track changes – the ability to turn on and off a ‘track changes’ type function
We are also integrating the MS Word-to-HTML conversion and the PDF rendering features. MS Word-to-HTML conversion is done through a set of conversion scripts we are writing called XSweet. These convert MS Word to HTML in a series of steps. We have deliberately designed it this way so that we can customise various stages of the conversion for different publishers since content types vary enormously between different organisations (or different departments within the same publisher). The conversion will be executed using an additional software we are building called INK. More about INK can be found on the Coko website.
The HTML-to-PDF conversion will be done using Vivliostyle. This is a great open source software that uses the browser to paginate HTML into a book form that can be output from the browser to PDF. It requires the development of custom CSS for styling the outputs and this takes a little time but so far the results look good.
In time we will layer on more functionality but, for now, this is the overview of the system. The aim is to get it functional for production tests within a couple more months, then trial it, fix issues, and start adding on more functionality. It has been an interesting road so far. Working with the Coko team and the UCP and CDL teams has been a real pleasure and I think we are building an amazing open source system for the production and maintenance of scholarly monographs.
To watch the ongoing development of the system please see the Editoria website. Also, consider reaching out to UCP/CDL via the Editoria mailing list of you are interested in learning more.