Off for a week’s holiday in Costa Rica!
Month: June 2017
Towards Web-based Word Processors p2
To get this discussion off the ground, I think it’s helpful to first think of what the standard features of a text editor are since word processors have all these features and then some. It’s the ‘and then some’ that I’m most interested in i.e. the essential features that make something a word processor.
Text Editor Features
So, here is my first stab at defining the features of a general, all-purpose, text editor. Keeping in mind that there are no strict rules to this and all category clumpings for this entire discussion are necessarily loosey goosey… text editors include the ability to:
- open, update, and save a suitable document, format, and store (eg on the file system or online) for recording the text.
- CRUD (to slightly abuse an acronym used in programming) text ie Create, Read, Update, and Delete text. I include here the ability to add/update/delete via normal keyboard input as well as common cut and paste tools.
That is actually it – the core feature set for a basic editor. A text editor doesn’t need to do much more than this.
Then there is another set of features that your favorite text editor may have (most text editors have some of the following) while still remaining a text editor. I want to categorise these as text editor features (most are related directly to editing text) and they include the ability to:
- select text
- select single and multiple block level items (eg paragraphs)
- apply inline styles (such as italics, bold, underline, strikethrough etc)
- apply subscript/superscript
- spell check (to varying degrees of sophistication)
- find and replace characters and words (to varying degrees of sophistication)
- calculate a document-wide word count (including possibly character count, line count etc)
- add and remove tabbed space / indents
- create, modify and remove hyperlinks
- add and remove images
- apply block level (eg para/image) justification / alignment
- undo / redo edits
- undo formatting
- add special characters (including diacritics)
- apply block level formatting eg heading 1, heading 2, paragraph, block quotes etc
- add, modify and remove colored highlighting to text elements
- add. modify, and remove text color
- ability to set the document language
- support for right to left, vertical, and left to right word orientation
- printing
- table support (create, modify, delete)
- show invisible characters (line breaks, para breaks etc)
- CRUD Math and display math in correct fonts and layout
- export to various document formats
- the ability to change fonts per selection, style and document
- the ability to change character size
That’s a good starting list. Undoubtedly you will be able to think of more. If you think of anything critical you think I missed, either add a comment to this post or email me (adam@coko.foundation).
Word Processor Features
So, what does a typical word processor have that a general purpose text editor doesn’t have? I think it is really, at present, a small set of features which inhabit two categories – content processing and document formatting. First, content processing:
- track changes. Yes the famous track changes, common to many word processors and sometimes called ‘Record Changes’ etc
- ability to create a document outline / ‘table of contents’
- insert special field / meta data (date / page number / time / author etc)
- annotation / commenting features
- bibliography control (including citation / reference placement etc)
- hyphenation control
- thesaurus control
- grammar check
- CRUD form elements
- create and insert charts
- create and insert basic shapes (with colors)
- ability to extend (typically via macros)
- footnote and end note support
…and, interestingly, the following document formatting features:
- ability to set style palettes
- ability to set page size
- margin control
- pagination support
- page numbering
- ability to create, modify, delete and use document templates
- header / footer control
Web Based Word Processing
So, why am I going through the rather mundane task of separating a list of features of text editors vs word processors? Well, its because when it comes to publishing we talk far too much about editors, and we don’t go far enough to define what it is we need from them. Far too often the tacit understanding is that we need good online text editors when we actually mean word processors. Hence our designs and requirements fall short of what publishing requires.
Not so? Well, take a look around. I see many projects suggesting we need to bring publishing into the web. Great, I agree completely. Implicit in that is the need to have good tools for changing text in the browser. Yet how many open source tools do we see that fill out the list of requirements for word processors that you see above. I don’t see any. I do see Google Docs, but that is closed source, suffers from insufferable UX (user experience design), and we can’t customise it, extend it, and integrate it into publishing workflows. So it is more or less useless to us. Same with what ever Microsoft is doing in this area (I would guess, I don’t know the MS Live product in any detail).
I also see attempts to make an online version of LibreOffice. But, I have to say, this so far looks horrible. Picking up a desktop app and just transferring the user interface and all the internal thinking ‘into a browser’ is not the same as making a web based word processor.
So, just so I get this all out there. Making a web based word processor that is open source, reusable, and native to the web is what the Wax editor is all about. Wax is a new product coming out of Coko and it aims to be a highly customisable, highly extendable web based word processor. It is built on top of the Substance.io libs. Wax so far supports some of the word processor features listed above, however, our aim is to componentize it so others can jump in and help us fill out the rest.
But that’s not the end of the story. Bringing word processing into the web is not just about a translation of a desktop word processor to the browser. You need to embrace the web and extend the concept of word processing into a browser-based, shared document, networked environment. That means extending the concept in some areas, and potentially closing down some ‘old fashioned’ ideas. Where does that point to exactly? Well…that’s the topic of my next post in this series!
Some links
Coko Products
I am currently planning how to keep all the Coko projects balanced and moving forward. It gave me a moment to reflect on just how productive we have been. At present we have 6 major products, all moving forward at an excellent pace, they include :
- PubSweet – the API toolkit for building publishing workflows (website coming soon).
- INK – the file prosessing (conversion, extraction, enrichment etc) framework.
- Editoria – the monograph production platform for publishers
- XSweet – the XSLT production for converting MS Word to HTML (HTML Typescript)
- Wax – the web based word processor built on top of Substance.io libs
- xpub – the (early stage) journal platform.
All this in less than 18 months, which is amazing enough but also consider that Coko was only 3 people (with Jure being the only developer) until 12 months ago. Its kind of astonishing to me.
The invisible skill
I do a lot of facilitation and I’m very good at it. I don’t know how I came to be a facilitator exactly, it’s not the sort of thing I think you go to school to learn. It just somehow comes out of you bit by bit on a road to achieving something else entirely. In my case, I think it came about while trying to build FLOSS Manuals (a community that produces free manuals about free software). FLOSS Manuals (FM) needed content, and I realised that it was not going to happen at the scale needed if I wrote it all myself. So I had to learn to build community and building community requires facilitation (even if you don’t know it at the time).

Anyway, long story short, I became a facilitator the hard way – by not knowing that it was facilitation that I was doing. I had no context. ‘How you get things done’ in the world seemed to be all about the doing of those things. If you want to write software manuals, for example, you wrote manuals. That is what publishers and author, editors etc did. Who ever heard of facilitation in the context? No one that I could find.
So it took me a while to even realise that facilitation could play a role in making manuals (books) and I only had that realisation after I first tried it the publishing industry’s way and failed. It’s even fair to say that I had no understanding that facilitation could have a role in helping people to make books until I had been facilitating people to make books for many years. I was that blind to the idea. Instead, I had this strange, slowly evolving awareness that somehow when I got people in a room and I was there also, then books resulted. It seemed like it was the participants that ‘were doing it’ and, bizarrely, every time we did it, it worked, every time we did it it was better than the last time, and I happened to be there to witness it.

It took me some time to work out that this result was because of the role I played. It took a very very long time – I would say, possibly, 2-3 years. The awareness didn’t come in one shot either. I first thought it must be the process that made it work. So I started trying some stuff out. I remember very strongly thinking that there was this process that actually existed, like publishing processes exist, and that it was concrete and tangible, but it was just that it was unknown. As seriously kooky as that might sound, that’s how I thought of it at the time. I felt I was discovering something that pre-existed, some process that just needed to be revealed.
Then, slowly, after Book Sprints were really kicking ass and producing remarkable books I’d have thoughts like ‘I wonder how important this process is?’ I wonder if it might actually be me that is the most important ingredient. Not me in an egoist way, like Adam Hyde is the only person that can do this (interestingly, other people thought this might be the case!), but maybe that it is not so much the process but what I am doing that is making this work.

So comes the understanding of the extremely interesting and tangled relationship between facilitation and method. I spent many years untangling it and now I think I have a 1.0 understanding. Like, at the school of facilitation if you get this idea, then you are actually allowed to call yourself a facilitator…. it is that basic, and that central to what facilitation is. My un-battle-hardened synopsis is this series of truths might seem a little contradictory: a good facilitator is better with a good methodology. A good methodology is nothing without a good facilitator. And a good methodology to a good facilitator is nothing but an interesting yet weak navigational instrument.
Anyhow. My sum of this is that I often get people telling me they would be a good facilitator for this or that, or that they would be if they had the opportunity. I also see a world where methodology is seen as king, you just need to read it and follow it to the letter and you’ll be sweet! I can’t blame people for this. How could I when it took me so long to understand that facilitation was a thing? I can’t blame people when they think it’s something anyone can do. But of course, I do find it frustrating. I’m no saint! But after many many years of practice and experimentation, pondering, trying things out when I was terrified they would fail, failing, succeeding, mentoring others to do it well, exploring the weird psychology of it all, seeing others do it so very badly – I can now say I know what facilitation is and how special it is to be able to do well this invisible skill that so many do not know even exists.

Back from Travels
I was back from my travels, but then slipped in an extra one at the end (London for 3 days). Now I can do stuff like look at the photos of the very cool PubSweet Global meet we had in Athens a few weeks ago. Here are some action shots to give an idea of what we were up to.

















Off to London
Off to London at short notice for meetings with publishers. Back in San Francisco on Thursday.
Towards Web-based Word Processors p1
Working with publishers is fantastic because they are hardcore text workers. These people need a lot from their tools, in particular, they need a lot from the tools they use to edit and improve texts.
Typically this has been the realm of Microsoft Word. But there are very many reasons why we need to liberate the publishing world from this approach. I won’t list all the reasons here, but at the top of my personal list are the following:
- MS Word forces publishers into an email-and-attachment workflow which is probably one of the single biggest problems in publishing workflows today
- MS Word is not transparent to publishing systems. You cannot see what is being done by whom and when. You can only look back and reflect on what has been done (if you are lucky enough to have the most recent version)
- MS Word is unstructured. This means that the display semantics (what you see) do not match the ‘under the hood’ document structure in any sane way. Ugh. I don’t know how to write about this without first saying ‘World of Pain’. Publishing needs (surprise!) nice clean structured content – even if only to make nice looking things to share (eg books) or, and this is where it really hurts, to share important information (eg scientifc research) that is machine-readable. MS Word really has caused the world so much hurt in this area and this issue in itself has slowed down the sharing of research and made the process unnecessarily expensive (and no, LaTeX is not the answer).
- Publishers rely on extending MS Word through macros… well, you might think this is completely awesome because you can extend MS Word. Well…take a moment.. .exhale that cool aid…. this is just the worst situation imaginable. This forces publishers to resort to maintaining workstations (yes, physical spaces where you need to go to in order to be able to do your work) running the exact version of MS Word that still supports the critical macros some developer made (before they moved to some inner rural district and started their own microbrewery) so the publishing staff can do their work. If you are a publisher, you know this is true. If you are not, please believe me – I am not kidding. Not ideal.
Oh my… I was just getting started. I have to stop – the list is much longer and I’m not even sure I am really putting the most important issues at the top. The situation is that bad.
So… we need to liberate publishers, and (most other) humans, from this situation. So, what would be ideal? Well… imagine a situation where display semantics have a 100% reliable co-relation to the underlying structure of the document – so you could just look at a document and know it was well structured. Imagine a world where you, as a publisher, knew what stage the document was in your workflow without you (or your staff) having to send out emails to whoever has the latest version.. .imagine if you could ask staff to work on the document with the tools they need from anywhere in the world…. imagine if this situation was also customisable to the nth degree, that you could take control of your tools, own your tools, and that the tools where… wait for it…. free…
Interestingly, most publishers seem to think this is still crazy future-think. However, it is not so. We can do it.
The trick is for us to collaborate on open source products and to move beyond the idea that word processors belong to the desktop and everything online is just a text editor. We can’t fault people for thinking like that – it has largely been true. However at Coko, we are moving away from the idea of building web based text editors, and towards building web-based word processors.
This is an interesting proposition because web-based word processors are not exactly like the word processors you know today… what makes them different? That’s the subject for my next post on this topic!
Onto Journals…
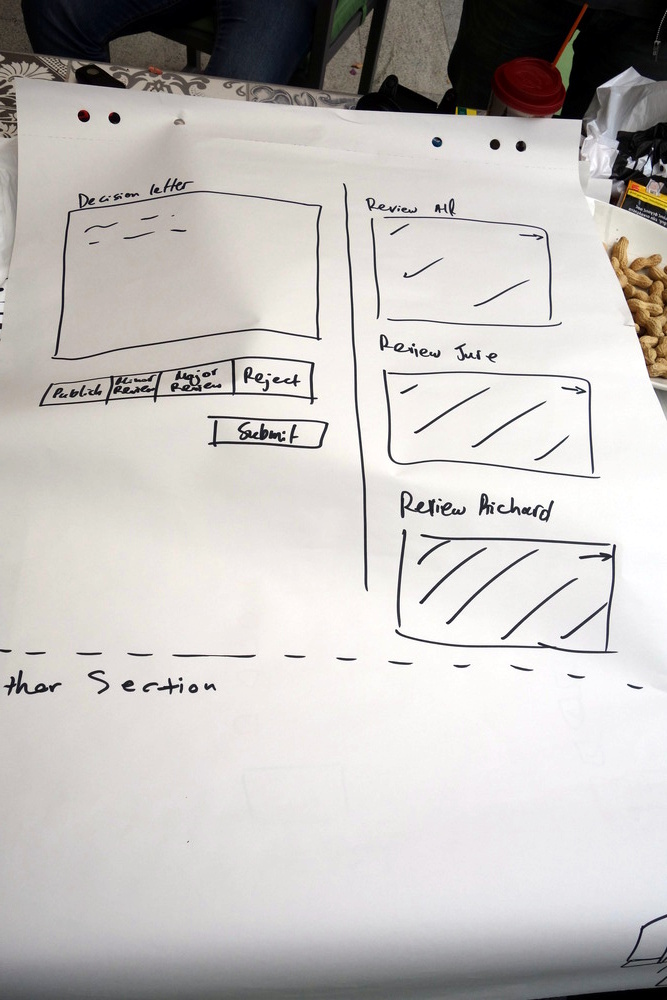
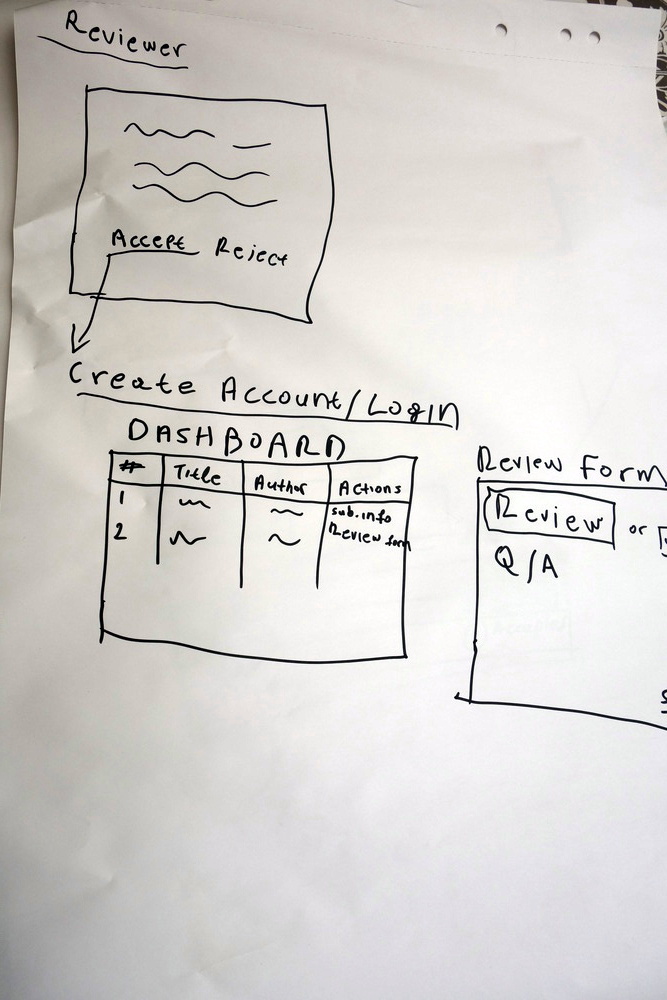
We (at Coko) have been working with Collabra Psychology to develop a Manuscript Submission System with them. The cool thing is, we can re-use a lot of work that we put into Editoria since we built PubSweet with the notion of highly reusable components (on the frontend and backend)…
I find it so satisfying to see our ideas and hard work put into building systems with the ‘right level of abstraction’ paying off. We are pretty much putting together a cluster of tech that can be re-assembled to meet a huge variety of publishing workflows very quickly…
The platform is called ‘xpub’ for now and it’s looking pretty good. We were able to assemble a basic dashboard, submission page, and editor plus link it up to INK for MS Word -> HTML conversion in a matter of days. All still in early days but looking great.

You knew the day was coming … 🙂
From Text Editor to Word Processor
We are currently adding features to the Editoria editor that migrate the component from a Text Editor towards being a web based Word Processor. More information coming soon!
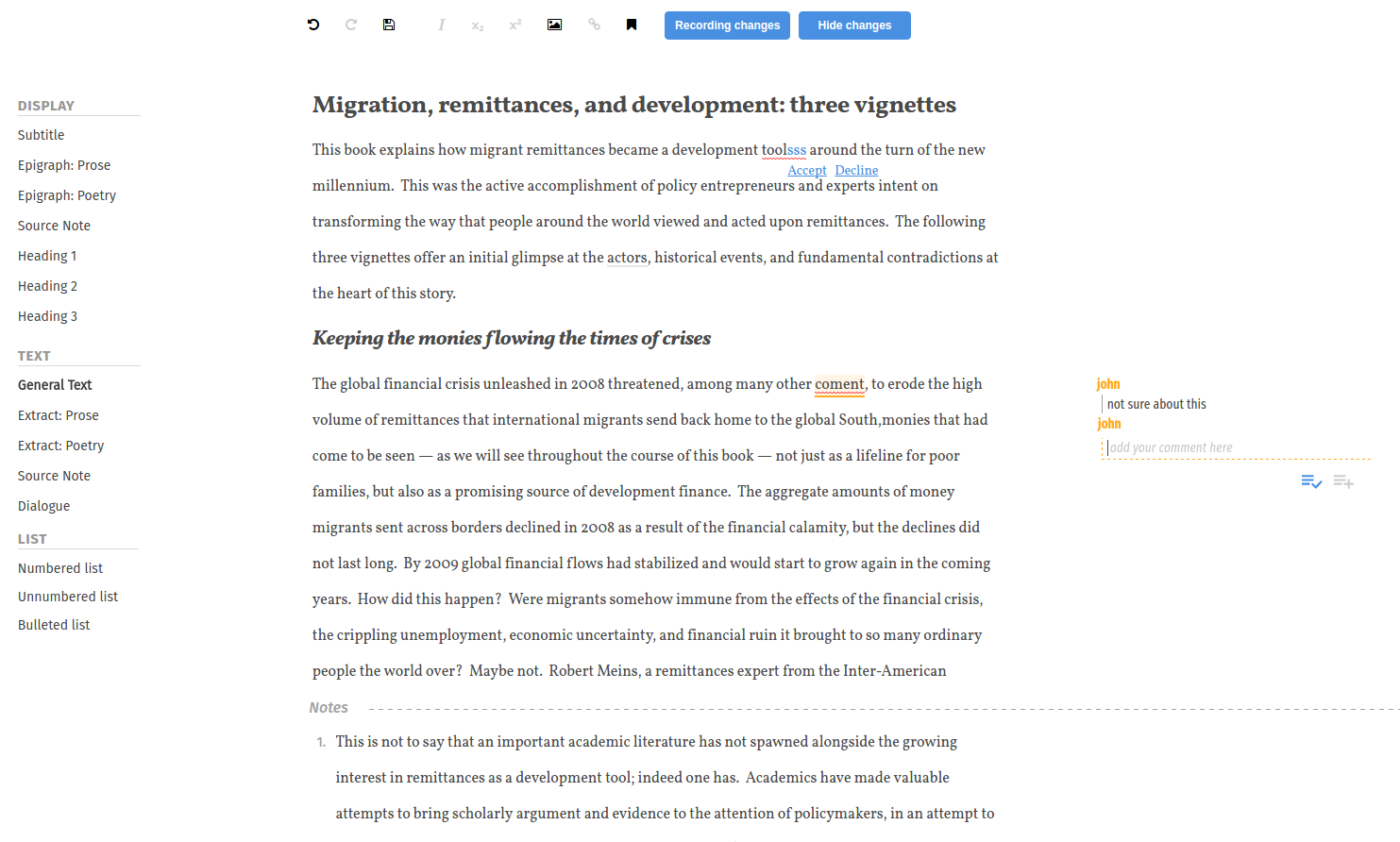
The Case of the Missing Click
We are drilling down further into Editoria – currently running production workflow tests with the copy editors and authors involved. During this process we are discovering some interesting insights into how production editors work.
One such case is that Kate Warne and Cindy Fulton from UCP wanted to be able to double click on a name of a chapter in the book builder component (a segment of which is displayed below), inorder to open up that chapter in the editor…

The interesting thing about this is that double clicks generally aren’t used in the web platform world. However, Kate and Cindy found they were constantly, out of habit, double clicking on the chapter names (but of course, nothing happened). This comes from their experience of working with MS Word documents on a file system (their computer). In these environments you do double click on the relevant .docx file to ‘open the chapter’.
I found this pretty interesting. It also exposes an interesting tension between what is generally considered standard user experience best practices for the web and established behavior (even if coming from another context). Many UX experts will go so far as to say double-click must die).
However, if Editoria did not support this, it would drive the production editors crazy as the behavior is so normal for them now. We will change Editoria’s behaviour to match their expectations.
Learning things like this is exactly why we use the Cabbage Tree Method to design software. Users are, after all, use case specialists and we should develop open source practices to involve them in the production design process as much as possible.