I get asked a lot how many platforms are there built on top of PubSweet. It can be quite difficult to understand this by looking at the Coko website. So here goes (we might add to the below and put it on the Coko site).
Hindawi
Hindawi is currently considering names for the journal platform it currently has in production, plus they are building more than one platform. First up is their journal platform, currently in production for their first journal. It is a low volume journal, with 20 submissions so far and 1 article which has gone through the entire process and been accepted for publication.
Hindawi are looking to make the platform multi-tenanted – which is a often misused/misunderstood phrase, but essentially it points to a strategy for adapting the software so that one organisation can run multiple journals from the same (singular) install/instance. Hindawi then will be going live with the second journal in the near future. They are leading the charge in the Coko community on this multi-tenanted approach and we continue to learn a lot from this amazing team of folks.
On top of this Hindawi are building a QA platform on top of PubSweet. All of which is open source and available to whoever wants it. They went live within a year of beginning to build. Notably the first to go into production with a PubSweet Journal platform.
After gaining this experience (building their first PubSweet Journal platform) they scaled their team up to 18 people working on different PubSweet developments.
eLife
eLife have a special issue where they wish to replace their current platform – EJP – but in phases. So they have been working closely with the EJP team to replace the workflow step by step. The first step has been to replace the submission workflow. Now 60% of all submissions go through their PubSweet submission component and then the article is transitioned into EJP via an EJP API (recently built). The content is transferred between the two systems using a MECA bundle, representing the first time MECA has been used in the world in a live use case. The MECA component is, of course, is open source and available to anyone building a PubSweet platform. They went live with the submission app in just over a year of beginning to build.
eLife is building out their entire workflow as a series of inter-connected PubSweet apps. This means you can grab one part of their system and integrate it in your workflow. Its an interesting strategy.
The cool thing about the Coko community is that we have a variety of approaches to similar problems so it will be interesting to see how attractive the multiple app proposition is to others. They will name each standalone app with the prefix Libero (eg Libero Publisher, Libero Review etc). All is open source.
It has to be noted that EJP’s position is a very enlightened one and fantastic to see a forward-looking vendor working with a Coko community member. I am sure this is going to work out in their favor going forward. I think the number of folks working on these platform components for eLife is maybe 6-10 … will ask Paul and check.
EBI
Lead by the very awesome Audrey Hamelers, the EBI (European Bioinformatics Institute) platform is going live in May with their system. They are intending to flick the switch and go from 0 to 100. The platform looks awesome and it is essentially a multiple source post-publish QA system for content aggregation (pushing to EPMC). It supports manual input through a submission wizard as well as batch FTP upload/submission. Although built specifically for their workflow it is conceivable the platform could be used for any workflow requiring post acceptance/production QA.
They have done some cool stuff with annotations using Nick Stennings Annotator, to QA XML. They are also using XSweet for docx to HTML conversion and a whole lot of other interesting tech. EBI have built this extremely quickly, with most of it done in a couple of months. Other priorities got in the way and they had to pause for a few months, but even so, if they go live in May it will be done in under a year from starting. I think they have a small dev team of about 3-5.
EBI has most of the Coko community meets. Awesome folks. All open source.
Editoria
Editoria is developed by the Coko team. A fully fledged post-acquisition book production workflow. It was developed with the University of California Press and the Californian Digital Library. Editoria is now used in production by UCP, ATLA, Punctum Books and Book Sprints. There is a fledgling but healthy community evolving around the product as well as a forthcoming hosting vendor agreement (tba). All open source. Editoria has a small team of (currently) 2 devs working on the core Editoria platform, however much more horsepower is added when you consider dev done on CSS stylesheets, paged.js, XSweet (docx to HTML conversion) and Wax (editor). So really the team is more like 6.
Micropublications
The wonderful wormbase crew commissioned the Coko team to develop a micropublications platform for their micropublications.org project. It follows a simple micropubs workflow which has been designed and built to allow for its re-purposing by any micropubs use case. When it gets down to it however the line between a journal workflow and a micropubs workflow (even tho micropubs is a broadly used and misused term) is a little imaginary. The two look very similar, the real difference is the scope of material submitted and the intention to process it quickly. This platform could probably also be used for journal submissions.
It has been in active dev for a year. Unsure when we will go live, it will probably be a progressively live situation with the initial switch being thrown sometime this year. All open source. Currently one (extremely productive) Coko dev.
Aperture
Another micropubs platform, dev just just begun with one person. It is a platform built for the Organisation of Human Brain Mapping. Awesome folks. I did a workflow sprint with them last year. Cool people and this will be a cool platform. Most interesting is their desire to publish living entities eg Jupyter Notebooks. Super interesting. All open source.
Pre-Review
Built by the pre-review folks and most specifically by Coko friend Rik Smith Unna. Great chap. This is a pre-print review system built to replace their current system that was built ontop of Authorea. All open source. One current dev (Rik).
Digital Science
A new addition – their innovations team is building a very interesting awards system. That in itself isn’t so exciting but their idea is to build a system with configurable workflows. You model a workflow, export, and then the PubSweet app is automatically compiled to suit. Very ambitious and very speculative. A lot to be learned from this and the good thing is that it is all open source and the DS folks are great to work with. Looking forward to see how this evolves. I think there is one developer currently working on this.
Xpub-Collabra
Xpub-collabra is a journal platform the Coko dev team have developed with Dan Morgan from the Collabra Psychology journal. We have put one year dev into it but with just one developer working on it. I’ve decided to pause dev for a little while so we can accelerate other efforts. Our platform dev team is small and we need to maximise resources, and as eLife and Hindawi have Journal offerings in the mix, we have less urgency to develop this platform at the moment. Though we aren’t abandoning it …stay tuned. (One interesting avenue is to collaborate with orgs with dev resources to finish this off – if that sounds like you, give me a call).
And…
There are a number of projects in the wind. A pre-acquistion monograph workflow, emergency medicines workflow and some other stuff. Plenty going on…consider this though… although PubSweet has been in development for 3 years, we only started building the community a year ago. Already 9 platforms are being built, covering a variety of fascinating usecases and 3 of which are now in production, 2 of which started building less than a year ago… needless to say, watch this space.
Just been in Athens, hanging out with the Coko Athens crew – Yannis, Christos, Giannis and Alexis. A thoroughly good bunch.
I think before I’ve mentioned how proud I am to work with them and what we are achieving. I mean, it’s a teamof 4 people and together they are developing 3 publishing platforms and a sophisticated web-based word processor … essentially 4 platforms – Editoria, xpub (Journals), micropubs, and Wax (editor)… I mean… talk about punching above your weight! More than that, we have fun doing it.
Every month I come to Athens and we discuss the coming month’s roadmaps. I come for a few days, we drink a lot of Freddo Espresso and sometimes (at the other end of the day) some margaritas. In between, we order some iffy delivery food and plan the future.
The roadmapping sessions involve us going through each platform together, and looking at last month’s roadmap. Discuss the next priorities and approaches, and then commit those to the next month’s roadmap for that project. It’s pretty interesting and super great to have everyone involved in the process. We get a good wide range of opinions and at the same time give everyone ownership of their own project. This is what collaboration is all about.
So some short notes here on this month’s roadmapping…
Wax – We have come very close to a fully functional web-based word processor based on the Substance libs. It is looking amazing with support for the normal editor stuff – headings, images, bold etc – plus some amazingly sophisticated features including track changes, notes management (more complex than it sounds), thread-based commenting/annotations, diacritics support … and a lot more… However, we have decided to start building a new Wax based on the ProseMirror libs, mainly because there is a lack of community around the substance.io libraries and we wish to de-risk ourselves going forward. So we’ll finish off Wax 1.0 with a Substance upgrade which will also bring us table support, nested lists, and some other issues. At the same time we will continue developing the new Wax (we already have something basic working) – first by adding some interesting widgets that the ProseMirror community have built, and then by building a simple plugin structure for editor widgets. We split Wax roadmaps up, but the important stuff for the current wax is listed in the Editoria repo – https://gitlab.coko.foundation/editoria/editoria#roadmap
xpub – we are now fixing a few bugs in the journal system and moving forward with migrating to the new shared data model that was collaboratively designed at the recent PubSweet meeting in Cambridge (UK). This will include some initial research into GraphQL (part and parcel of the migration). Part-way through August, Giannis is attending the Libero workshop at eLife and will work on that with the eLife team for 2 weeks. Libero is the open source web-delivery part of the publishing cycle that eLife has designed and is about to build. So we want to put into that effort and learn what we can. That also means the actual migration to the new data model will happen after those 2 weeks ie. We’ll start it on Sept 1. More info here – https://gitlab.coko.foundation/xpub/xpub#roadmap
Editoria – this is coming along fast. Alexis just added EPUB export and overhauled the workflow management tool. Editoria is pretty much ‘fully fledged’ although we have many ideas for new features – however much of this will wait until the Editoria community meeting in San Francisco in October. In the meantime, we are being good open source citizens and writing a lot of under-the-hood tests. Alexis will also spend a day or so writing a new Authsome mode to match the Book Sprints workflow to show that the auth app Jure (PubSweet lead dev) built is indeed plug-and-play. More info here – https://gitlab.coko.foundation/editoria/editoria#roadmap
Micropubs – we are developing a micropublications platform with the Wormbase crew. Its early days but ison schedule with the first thin slice. It contains complex integrations and complex submission forms. But Yannis is making good speed, so more of the same! https://gitlab.coko.foundation/micropubs/wormbase#roadmap
It is, as I said above, an awesome team. I’m very proud of what we are achieving together and I like to punch above our weight. Much more information coming soon about all of this as we go!
Spending a night tomorrow in the UK, and then to San Francisco for a meet with Kristen, attending FOO camp and many other bits n pieces.
Well… I was driving from Cambridge (UK) to Newquay and chatting to my buddy Faith about all the things I have been working on (Faith is rewriting some of my website) over the last 10 years. I was commenting on how crazy circular it all is at the moment… I found myself documenting Editoria a few weeks ago, using Editoria to document it… which is just the kind of thing I started doing when I started FLOSS Manuals 10 years ago. And then this week I was in a Book Sprint this week as a participant for the first time whereas it was the first time as a facilitator 10 years ago… and this week I was with a team of Coko people writing a book about a Coko product and at the same time with a team of Book Sprints people helping Coko to write a book…and I started both organisations… its all so recursive….
Its been a bit weird. And as I’m chattn to Faith and driving through a lovely summer’s solstice day in the UK pondering this out loud and what do I accidentally discover?….
Y’know… that place with the rocks in a circle….And I didn’t even know I was near it…I don’t know… gotta take account of things like that I reckin..
The Coko community is having a Book Sprint in Cambridge next month. It will be about 10-12 people, and facilitated by BookSprints.net and featuring folks from Hindawi, eLife, EBI and Coko! Community making docs for the community.
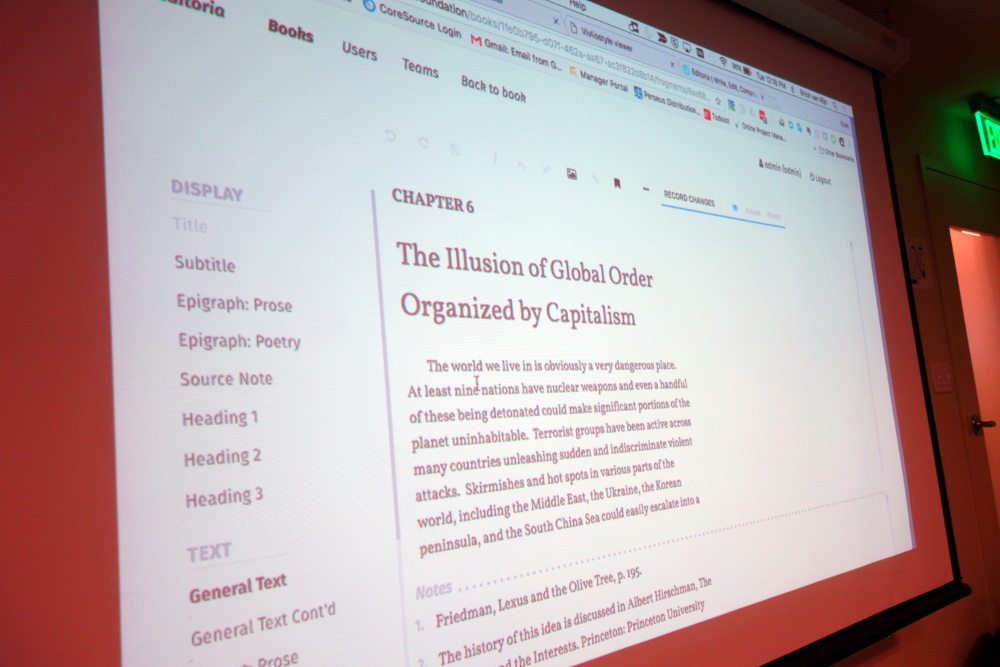
We will use Editoria in the process for writing the book, which is a classic case of dog fooding. Looking forward to it!
Yannis and the Athens crew have been tweaking our workflow for the products built on top of PubSweet. This includes (at present) Editoria (book production system) and xpub-collabra (Journal system).
Essentially, after the initial design and build process we slip into faster iterations where I step out of the way and the ‘client’ and developers work in very fast iterations to tweak features and fix bugs. We loop in Julien for UX as necessary. Then we move into a stabilization phase for landing the product.
Right now both Editoria and xpub-collabra are in the tweaks and bugs phase, and we have started adding a ‘roadmap’ to each of the READMEs to list what we are working on now. See:
Arthur Attwell presentingSlide from Arthur’s presentation showing his Electric Book workflowCSS guru Dave Cramer presentingCSS Love from D.CSlide from Julien Taquet showing BookJS in action (still!)Julien TaquetNellie McKesson presenting some of her work and experimentsOpenStax slide from Kathi FletcherKathi FletcherDan Fauxsmith (OReilly)Editoria in actionErich van Rijn presenting EditoriaHugh McGuire (PressBooks)Julie Blanc (PagedMedia) presenting an overview of strategiesSlide from JulieFred Chasen (PagedMedia) demoing his experiments
Bulk upload of MS Word files into Editoria. It takes the selected files, puts them in the right sections in the book and in the right order (at this moment this is determined by filename), converts each to HTML and populates the book with this content…all automagic! (thanks to Alex Theg for making the vid).
Much is going on in the Coko world at the moment and a lot of news coming out soon about various collaborations. Much of the attention has been around xpub, the journal system we have been working on built on top of PubSweet.
PubSweet is, of course, a component based system so you can ‘roll your own’ journal or book platform from existing components. We are making a lot of components for both Editoria and xpub and publishing them for reuse with an open source (MIT) license.
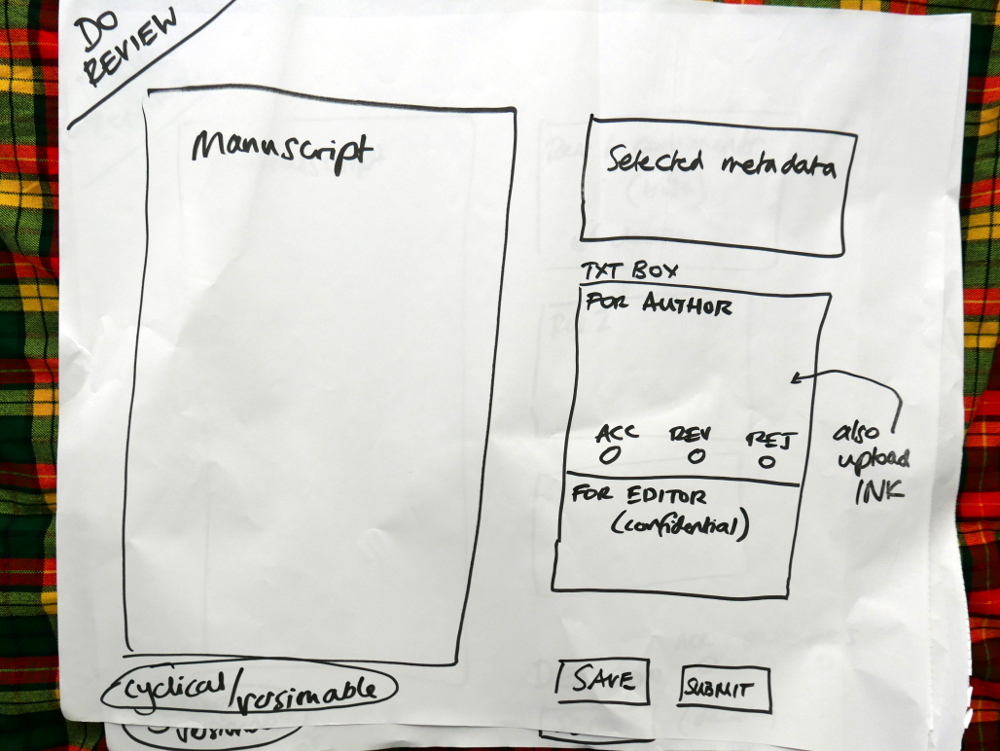
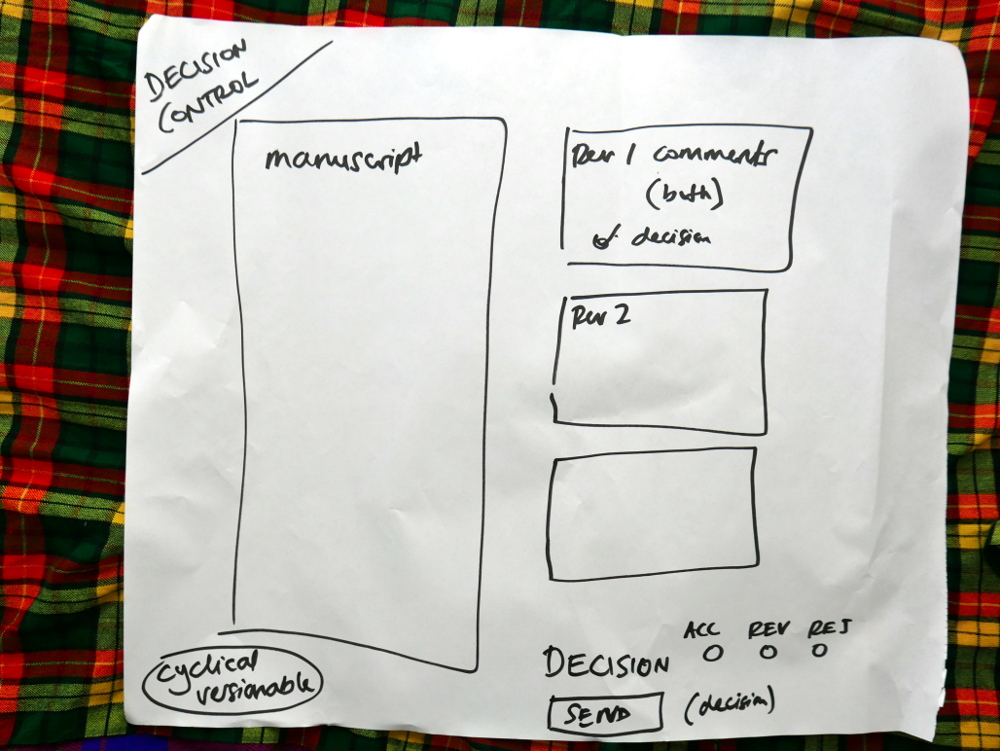
Some of the components we are generating for xpub are coming out of the work we are doing with Collabra, the UCP Psychology Journal. Today the Managing Editor, Dan Morgan, and I met for another session working out the logic of the components and how they fit together.
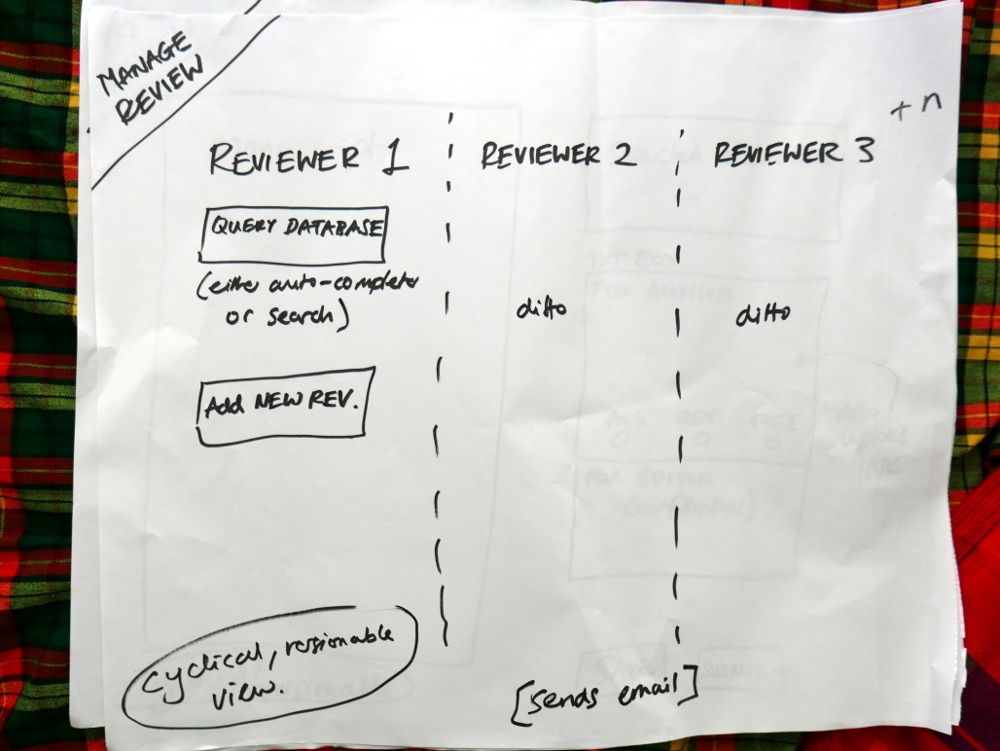
We started by working through the flow from the perspectives of each of the major stakeholders – Managing Editor, Senior Editor, Handling Editor, Author, Reviewer. We worked out what they each needed to see on the dashboard and then went through their workflow and what they needed from each component.
List of what each actor sees on their dashboardMapping out the flow across components.Sketches of components
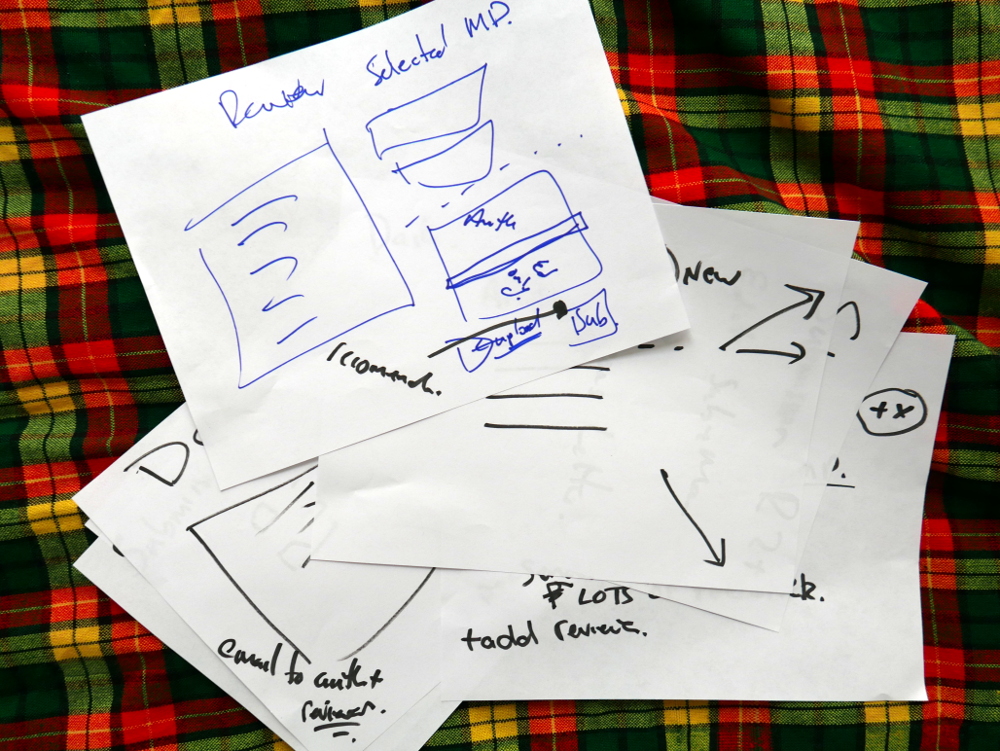
We then took each of these small mappings and transferred them to larger pieces of paper. Drawing the interfaces in basic form.
Drawing out the components in detail
Each of the diagrams are detailed below.
We had already worked out this structure. Today was about running through the logic from each actor’s point of view. Good news is, the logic held up and validated the architecture. Good news! So, what you see in these pics is more or less what we will build. It is a thin horizontal slice that covers the complete lifecycle of a manuscript going through the Collabra process. We’ll build it and test it, and then layer on additional functionality.
Next I’ll recreate these in digital graphics and add a page of bullet points for explanation. We will then meet with the Coko team and talk it through and start building! It’s a good way to design systems, way better than endless months gathering pages and pages of product requirements. It’s a lightweight and fun process. Software is a conversation after all!
The past two posts I wrote on this topic looked at defining the difference between a text editor and a word processor. The posts in this series represent me ‘thinking out loud’ about what word processing needs to evolve into in the age of the web. So far, in my opinion we haven’t seen an evolution from the desktop given that Google Docs, as the premier example, looks and thinks pretty much like MS Word.
For this post I’m going to look at the first obvious visual differentiator between a text editor and a word processor. You notice this immediately when you open a word processor document, and you are skilled at manipulating its characteristics, but you might not think of it as a ‘feature’ as it is so present to almost be invisible – I’m talking about pagination. The first thing you notice when you open an existing document or start a new one is pagination, the boundaried space that makes your digital interface look like a piece of paper. Its not the sort of thing we think of when we think about a ‘feature’ but it is probably the strongest differentiating characteristic that separates the two categories of software.
Pagination
Why do we need pagination in a word processor? What purpose does it serve?
There are a number of purposes. Picking them off one by one:
navigation. We can generate navigational schemas if the content is paginated. These can either be inline references to page numbers or it might be in the form of a table of contents.
position in document. Related to (1) above – knowing what page number you are on, and the total number of pages, is an important function of pagination.
boundaried read/write space. In the print world it has long been considered a best practice to have between 45-75 characters per line (commonly abbreviated as CPL). Various arguments have been made that this number is optimum for speed of reading and comprehension (although I haven’t found any research about this, if you know of any please let me know!). Robert Bringhurst, the author of The Elements of Typographic Style (a goto for many book designers), goes even further to suggest the ideal number of characters for optimum legibility is 66. That is pretty specific. As it happens writing environments have always been around this range. Typewriters, for example, were generally around 80-90 CPL, teletype around 70-72 CPL, and this WordPress editor in which I am writing this has 72 CPL. Bounded spaces in Word Processors generally limit the CPL to around the same amount. Google docs is somewhere around 70-80 CPL, and LibreOffice is around 80. The area of 70-80 seems to be quite standard for Word Processors but laptops and larger screens can easily accommodate hundreds of characters per line so we need a bounded space to limit the CPL. Pages are a handy, and familiar, way to boundary the text area to limit CPL.
‘how much’ metrics. Word count is one indicator of how long a work is, but page count is often used both formally (ie. funding applications or job applications require a fixed number of pages) and intuitively by the writer to get a sense of how long their work is as they create it. Academics, in particular, often think of a works length in terms of page count.
expected ‘look’. Placement of headers and footers, page numbers etc are added to a document to make it conform to an expected look and feel. A letter of application for a job, for example, needs these elements as they are generally considered to add an air of formality to the document. This is obviously inherited from the age of paper but interestingly we still do this regardless of whether the content is printed, distributed as a word processor file, or rendered to paginated PDF.
design canvas. Interestingly, word processors are used as design environments. Think of the times you have played with fonts, tried to get the right spacing between a heading and the following paragraphs, added images and tweaked with the text flow to make the image sit well in the page etc. A boundaried ‘page’ presents a known canvas within which we can apply our implicit document design skills honed over many years of using word processors.
to print, or the possibility of print. There always is the possibility that the documents we create will be printed. If not by us, then those we share the documents with. We implicitly understand that if it looks fine on the screen then anyone printing it ‘sometime later’ will get a tidy outcome. In many cases we don’t think about it much, it’s more of an implicit assumption that covers us ‘just in case’ it is printed.
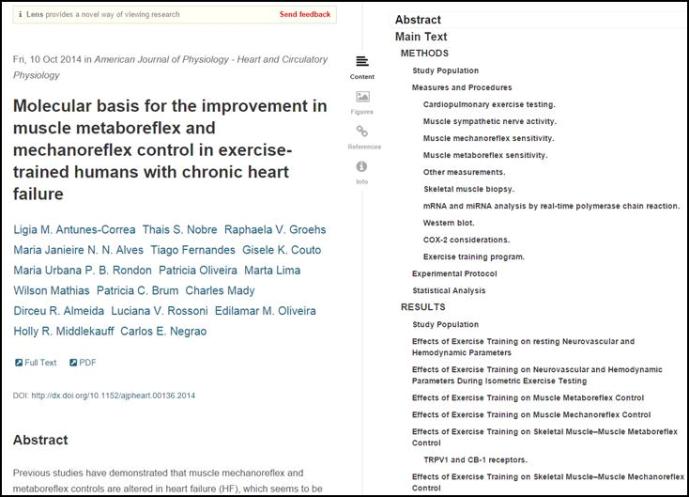
So, what to make of this. First, pagination is pretty essential to how many people use a Word Processor. It’s hard to think we can do without it. We might be able to achieve some of the above without a page paradigm. We could probably reasonably easily overcome the first 4 issues above – for example, we could provide word counts + ‘approximate page count’ indicators to give an idea of ‘how much’ content there is, provide a hierarchal navigation view of headings instead of page numbers for navigating around a document and as a ‘table of contents’ as Google Docs and eLife Lens (based on Substance.io) does.
eLife Lens. Table of Contents on right
In addition, there are a number of ways to indicate the reading position in a document that do not require page numbers – check out this example (thanks to Julien Taquet for this tip), and it is also possible to limit the CPL without providing page boundaries in the design as Wax Editor does.
Wax Editor
However…the show stoppers really are the last 3 from the list above (to summarise again) –
expected look – many documents are expected to have page-based design elements regardless of whether we actually print them
design canvas – we know how (from years of banging around on ugly Word Processors) how to design documents using Word Processors, and
to print, or the possibility of print – we never know when something might be printed so knowing it looks ok on a ‘virtual page’ is a nice guarantee that it will look fine if printed.
Are we stuck with pagination?
It is difficult to argue that we could easily, or completely, throw away the page based paradigm based on these three items. So…does that mean Word Processors will be forever tied to the rather ugly page that you see floating like an existentially blank canvas every time you start a new document? Will web-based word processors forever be stuck in this paper paradigm?
My argument is no. We don’t need the page. Or at least, right now, in many use cases we can throw it away. The examples I used above provided clear cases where we need to directly correlate what you see when you create a document to the final result – whether for screen-based display, or print. But not every use case is like this. What is one of the biggest situations where you do not require a strict co-relation like this? Publishing.
I think I might hear you thinking ‘huh’? Afterall, if there is one industry that actually does require pagination it is the publishing industry (thinking in terms of the book and journal publishing sector for now, excluding newspapers, magazines etc).
That is true. However, the publishing industry doesn’t distribute to their readers a journal article as an MS Word file, or a book as a directory of MS Word files. They distribute unpaginated (usually) HTML files on the web, paginated PDF, EPUB files with various approaches to pagination, or paper. They generate these files by sending their source files (often MS Word) to an external vendor or in-house designer, who imports them into any number of design environments and converts this into the required formats.
Pagination comes ‘at the end of the line’ so to speak. Hence, unlike the typical home or office environment, there is no 1:1 correlation between what you see in word processors and what is finally distributed. So the needs of a word processor for a general user might be different to the needs of publisher. That, in itself, is pretty interesting. What if we could imagine specific word processors for specific use cases….
However, you will notice that word processors take a one-size-fits-all approach. We don’t have one word processor for book authors, one for publishers, one for lawyers (etc etc etc)…that is not to say we don’t need to differentiate these use cases and look at the specific needs of each. Interestingly, developing web based environments takes a lot less work that developing desktop applications and things have moved on since MS Word first hit the shelves. The web gives us substantially more room for modularity and customisation. With web-based word processors, every feature can be a configurable option. Don’t want or need track changes? That’s ok… remove it… Need a Diacritics interface? Easy… add it. Don’t want pagination? Remove it.
The point is, we can start building web based word processors that are highly customisable and can be configured to meet individual use cases. We haven’t seen that so far in word processing, Google Docs has also chosen a one size fits all – the only real difference here between GDocs and MS Word is that their ‘all’ is a smaller group. But that doesn’t mean we can’t do it if it makes sense. Technically it is very feasible and, as it happens, it’s the approach we are taking with the Wax Editor.
So, let’s imagine we have our own word processor made specifically for publishers. Do we need pagination? What role does it play in publisher workflows?
It is true that relative to the total number of publishers out there I’ve seen inside a small % of publishers’ workflows. However, interestingly, with each new publisher I work with I am seeing, more or less, the same workflows and from what I have seen so far, MS Word files are used widely to support a kind of early page-prep workflow. Publishers check and improve the content of course, but they also make sure certain elements are in place that will affect the final design. They check, for example, if all paragraphs are correctly indented. They check if images are in the right place, they check if headings are marked correctly and that no levels have been jumped etc. These all affect the final paginated outcomes, but none of this requires working within, or manipulating, pagination as it appears in the word processor. Checking the results of pagination (including page numbers, running heads, widows and orphans etc) comes when publishers do their page proofs ie. when they check the PDF before print or distribution (sadly, many publishers don’t check EPUB very thoroughly but just accept that it ‘is what it is’). Publishers don’t currently check the results of pagination, as it will appear in their final distributable form, in the word processor. So pagination in the word processor, at least on this point, is a little redundant.
So… my point is, if we get down to it, pagination features in a word processor are not required when you are working inside a publisher to prepare a document for publishing. We could instead use an unpaginated environment with a navigation based on document structure (not pages), word count as a metric for how much content there is, and simple constraints on CPL that do not look like a boxed, bounded, page.
But…what about the need to print on your office or home printer? Interestingly, I think this gets to the crux of the matter. Unbounded, flowable text, in a word processor does not mean you can’t print. It only means what you see in the word processor won’t have a one-to-one co-relation, with regard to pagination, to what is printed. But the big question is – is this acceptable to publishing staff? Can we get them to let go of thinking, a product of many years of legacy word processing user experience design, that the pagination in the browser ‘must’ correlate to the pagination that comes out of their home or office printer. My experience designing such systems alongside publishing staff leads me to believe his is possible. In fact, the University of California staff designed the Editoria system which features the Wax Editor which displays content sans pagination. The challenge is – it is up to us to show them that throwing pagination out works in their favour.
Before I go on to why throwing out pagination can be a convincing argument, I want to indulge in a rather lengthy aside and state that throwing out pagination is not the same as ‘not printing’. The results of printing from an ‘unpaginated’ form in a web-based word processor can be beautiful and a more consistent experience than printing off ‘any old’ word file. This is because we can use CSS print styles to make beautiful looking results that come out of your home printer. The point is only that the pagination will not correlate to what you see in the word processor. But you can have other things – for example, you could render pages for printing at any time that look like your final output. Quite probably this statement is news, or confusing, to you. It needs extensive explanation. But the idea, in basic form, is that content in HTML based word processors can be shaped by CSS into paginated form in the browser. This process allows you to automatically format the content into book or article form including running heads, page numbers, widow and orphan control, multiple columns (if desired) while also generating the table of contents and even indexes. This can be achieved, for example, by platforms that leverage tools like Vivliostyle. I’ll get to this in subsequent posts, maybe even the next one (in the meantime, you may wish to read this). For now, I want to leave this issue to the side but make the simple point that content that is not bounded by a page in the word processor can still be printed and, further, the results can be more beautiful and consistent than what you get by printing from Google Docs or MS Word today. However, the process of printing will feel slightly different because ‘how you print’ will be to first render a view that is conformant with your printer and then print. It’s not much different to how it is done now because this is how print-preview works in word processors today. When we print, we commonly choose the page format at print time, although most of the time we leave it at its defaults because we know that what we have seen in the word processor is the same as what will come out of the printer. ‘The new way’ would mean you will need to pay more attention to the second step – checking the formating in print preview before printing. Which is why I emphasise that the process will feel slightly different, the actual change in behaviour is minimal, if anything at all. But it would be a mistake to conflate user experience with user behaviour. The experience of the software is nothing to be brushed lightly aside, it can be a very strong impediment to new ways of working. So how things feel need to be taken into account. Which is why I think, ultimately, we will need other arguments to help many (not all) ‘get across the line’.
Which brings us back to the question – what is the advantage of not having pagination? If we can do away with it we have far more options for making beautiful experiences. The bounded page that all word processors commonly present is, in my opinion, hideous. It constrains how you construct a user interface, how people feel about that interface, and how people work. If we can free ourselves from it I think we open the door for much better experiences and innovations on what a word processor can do and be which also means, in the publishing industry, we can start innovating around word processor workflow.
Additionally, removing pagination from the word processor in publishing workflows is better aligned with how publishing works. Publishing formats do not share the same pagination. An EPUB page is not going to be the same page as the content displayed on the net, in a Kindle, in a PDF, or in a book. Might as well let that one go. If we need pagination at all, it needs to look like the final output and we need to get it earlier in the workflow than what currently occurs. Currently, publishers only see this after the content has been through their workflow and gets ingested and output to various formats by a designer, production staff, or external vendor. However…. HTML based word processors that leverage tools like Vivliostyle (mentioned above) enable the content to be paginated to all these formats on the fly. That means you can have ‘page proofs’ anytime you want in the process. So, letting go of pagination in the word processor, coupled with the ability to create these various paginated forms at any time, is an advantage to publishers. Publishers don’t need to wait for page proofs from a designer before they can tweak elements in the content (eg placement of images) to make the pages flow better in the final output. They can render, check, and tweak at any moment. From this point of view seeing one kind of pagination in the browser, especially one that conforms to a generic printed page coming out of the office printer, as it does now, is counter intuitive. But, I don’t expect many publishing staff to accept this by argument alone. We have to first get most people to experience this, and other benefits of a pagination free experience in a word processor, before they can start moving the way they work forward.
My conclusions? Well, I think it will be a while before we can convince the general user to drop pagination. But web based web processors allow us to build much more customisable experiences and avoid the ‘one size fits all’ approach. We can build to meet publishers’ specific needs and it is because of this that I believe we can produce software that will convince publishers to make the conversion sooner. This is because we can make the experience for them better if we drop pagination. The pages, which they look at for hours on end, can be cleaner, easier to read, and less tiring over long periods of time. We can also start using space more effectively by removing borders around pages (with their attendant inner and outer margins). And lastly, I think it is important to remove pagination from word processors for publishing workflows because it helps disambiguate what you see in the word processor from the final, designed and paginated, results. This latter point has positive knock-on effects that I will come to in other posts. Couple all this with the ability to ‘paginate on the fly’ (so to speak) at print time (for domestic/office printers) or to generate ‘page proofs’ of many target formats, and we have a winner.