Part 5 in the series about Single Source Publishing out now! Learn about the features of the source format and high level architecture than can make all the magic happen. https://coko.foundation/single-source-publishing-part-5-workflow-first-systems/
Category: Uncategorized
New Editoria Release

Editoria
Just writing a little ‘what is?’ text on Editoria for my own use.
Overview
Editoria is a modern book production system.
Editoria enables authoring, collaboration, proofing, copy editing, styling, formatting, reviews, author proofs, discussion, automated typesetting, and multi-format export – all within a web browser.
Why Use Editoria?
Collaboration is integral to publishing. Authors, researchers, editors, proofreaders, designers, typesetters and production staff all work together to deliver content to the world. Unfortunately legacy publishing workflows constrain collaboration with linear workflows, each stage of the publishing process is gate-kept by whoever is actively working on the documents at that time.
The web offers the unique opportunity for collaboration to take place concurrently, eliminating the gate-keeping and consequent waiting times, miscommunications and versioning madness. If everything that needs to happen to the content happens in the web all the way through to delivery, individual tasks can be done quicker and the entire process becomes lighter to manage. What this means practically is that each actor can do what they need to do when they need to do it and the status of the document is available at a glance at any point in the process.
To create this vision of optimized collaboration in publishing there are three issues to solve: getting content into the web, editing content in the web, and getting content out of the web (into print ready formats). In others words, we have to solve everything. Attempts have been made to solve these issues before but they haven’t been solved in a way that satisfies Publishers.
Enter Editoria. Editoria is designed by Publishers for Publishers to meet their needs.
Consequently, Editoria offers independence from expensive, upgrade-driven systems. You can, for example, do away with Microsoft Word and Adobe InDesigns costly licenses, and the need to update InDesign templates and custom made MS Word macros. No longer do you need to preserve that one ancient computer in your organisation that runs the right version of MS Word for the job at hand! No longer do you need to rely on external designers. You can do it all yourself, or in collaboration with a larger team.
Editoria is built to help Publishers both large and small.
How Does Editoria Do This?
Typemill now supporting Pagedjs
and the adoption just keeps on going…
EkoKonnect
I’ll be speaking on Jan 19 about a new plot we will run in Africa for Open Access publications. https://2021.eko-konnect.org.ng/session-1/

Book Sprints on Podcast
Great interview.
Book Sprints are the leaders in rapid book production. Their CEO and Lead Facilitator, Barbara Rühling, regularly leads her clients’ teams from zero to book in just five days. Arthur and Barbara talk about how she and her team work, and what other book-makers can learn from it.
https://howbooksaremade.com/episodes/how-to-make-a-book-in-five-days/
Wax 2 coming…
Screen shot of the themeable (and very customisable) Wax 2 all assembled with some nice initial features. More work to be done but it is going to be an awesome 1.0… we also recently tested Grammerly (the third party tool used by many copy editors) with Wax 2 and it works very nicely.
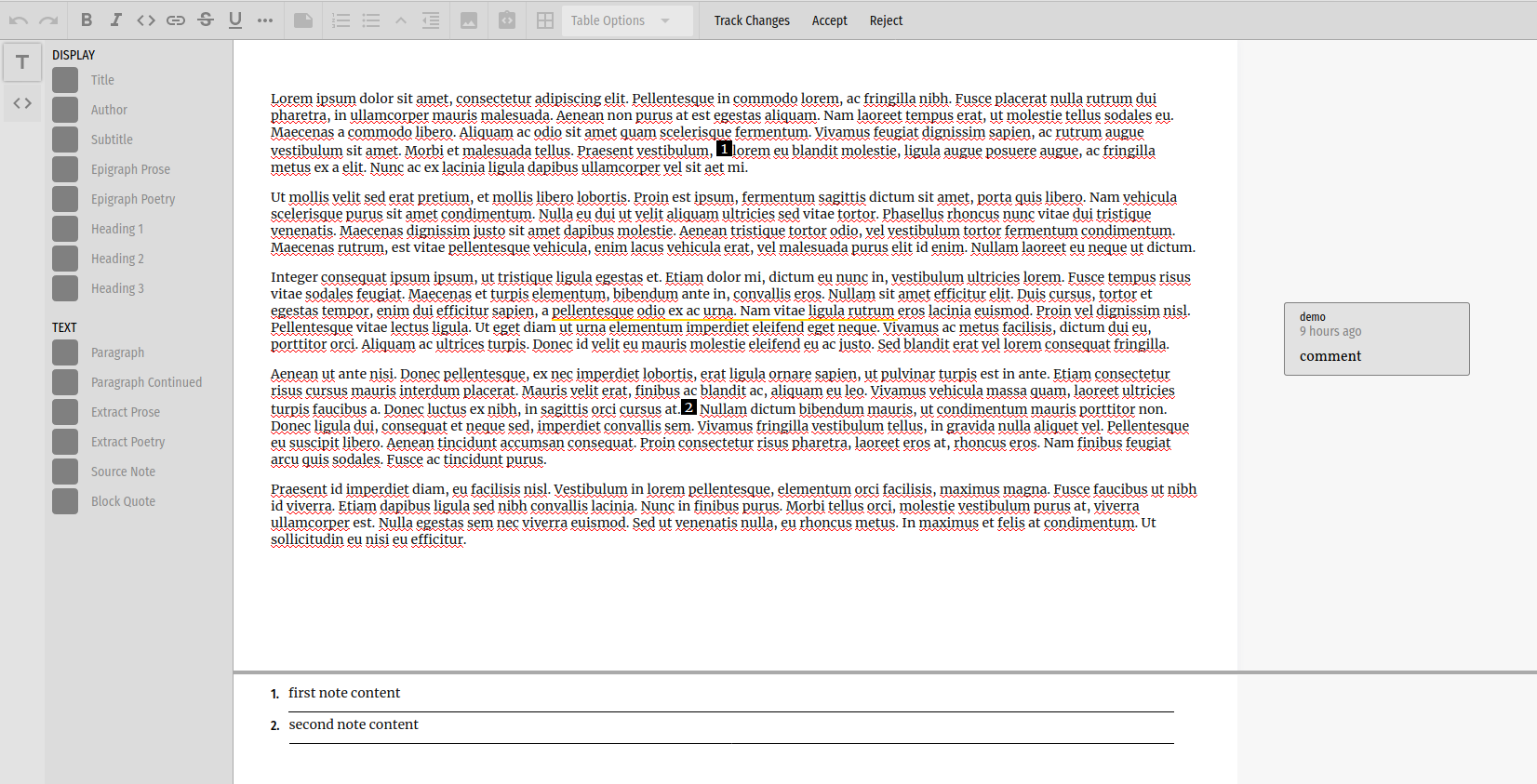
New Editoria Proposals
Working on some Editoria clean up proposals for the UI. Coming to the community proposals process very soon.
Coming soon…

Secret Squirrels
don’t tell anyone… posting this site public next week after we have tweaked it.