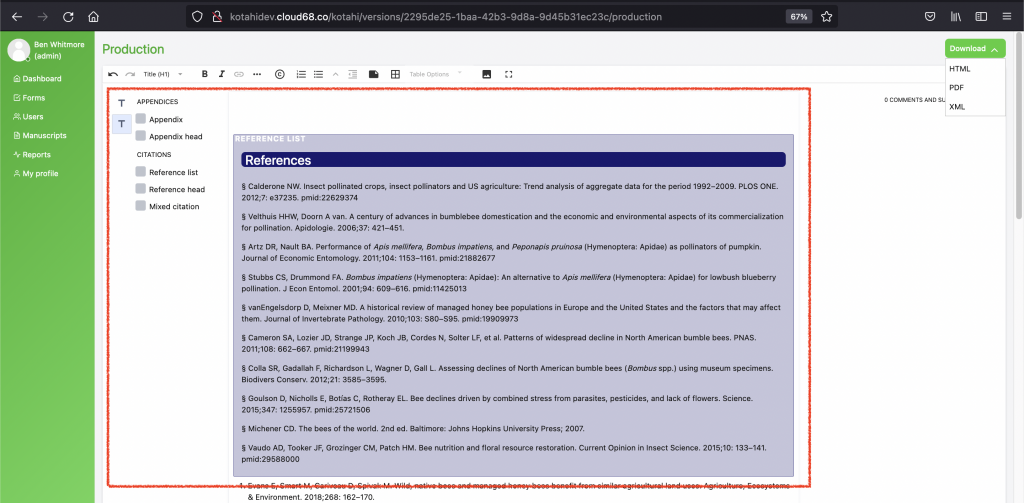
so folks… this is sorta big news… we have a very simple mechanism to export JATS from Kotahi. It means either of these scenarios are possible: 1. small DIY journals can use this very simple tool to create JATS themselves without any knowledge of JATS 2. larger journals with internal production staff can use this tool and be part of the entire flow as the tool is integrated into Kotahi (and not separate external tooling) 3. vendors can use this tool and be ‘in the system’ as opposed to being outside of the system…this offers more transparency into the process
The tool also offers some other interesting possibilities… given that Kotahi can be configured in a myriad of ways it is very possible to configure Kotahi so that it could be a production management tool for journals with *existing manuscript submission technology*. It could, for example, be used for production management in conjunction with OJS, Janeway etc
Coko designed this approach to creating JATS and it was built by Coko in collaboration with our friends from Amnet.
Still some work to be done (always!) but it is pretty cool…If you would like to know more drop me a line
Book Sprints crew (Juliana and Faith) in Mozambique at the moment to do a Book Sprint. The crew doing amazing work (working with CARE) despite insurgencies and a pandemic.
One of the few Book Sprints we have also done in Portuguese!