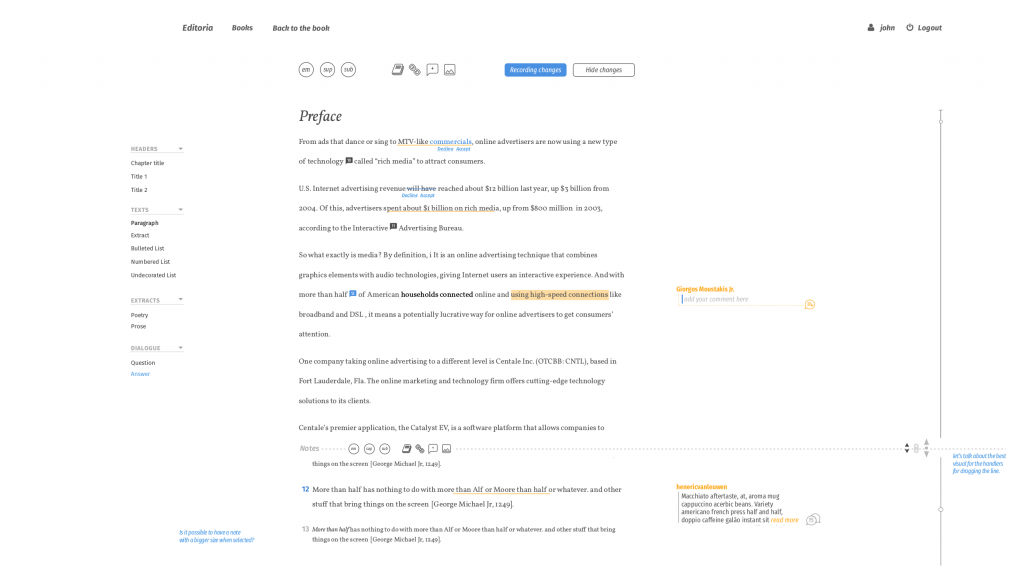
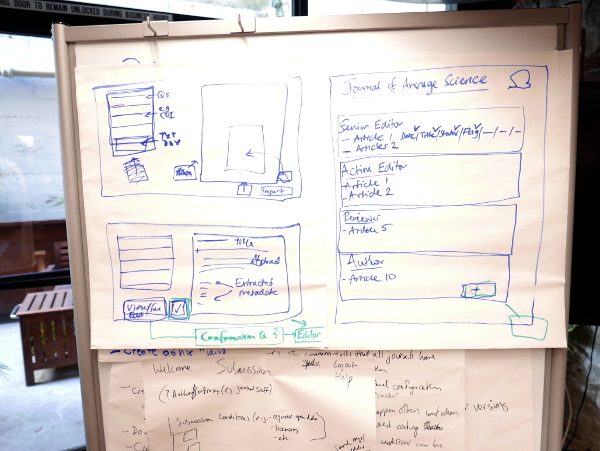
Recently we released INK 1.1, it is a great milestone to arrive at, just a few weeks after 1.0. Charlie Ablett, the lead dev for INK, has been working very hard nailing down the framework and has done an amazing job. It is well engineered and INK is a powerful application. You may wish to ink1 if you wish to learn more about where INK is now.
For the purposes of the rest of this post (and if you don’t wish to read the above PDF) I should provide a bit of background, cut directly from the PDF:
INK is intended for the automation of a lot of publishing tasks from file conversion, through to entity extraction, format validation, enrichment and more.
INK does this by enabling publishing staff to set up and manage these processes through an easy to use web interface and leveraging shared open source converters, validators, extractors etc. In the INK world these individual converters/validators (etc) are called ‘steps’. Steps can be chained together to form a ‘recipe’.
Documents can be run through steps and recipes either manually, or by connecting INK to a platform (for example, a Manuscript Submission System). In the later case files can be sent to INK from the platform, processed by INK automatically, and sent back to the original platform without the user doing anything but (perhaps) pushing a button to initiate the process.
The idea being that the development of reusable steps should be as easy as possible (it is very easy), and these can be chained together to form a chain (recipe) that can perform multiple operations on a document. If we can build out the community around step building then we believe we will be able to provide a huge amount of utility to publishers who either can’t do these things because they don’t know how or they rely on external vendors to perform these tasks which is slow and costly.
A basic step, for example, might be :
- convert a MS Word docx file to HTML
Which is pretty useful to many publishers who either prefer to work on an HTML document to improve the content, or have HTML as a final target format for publishing to the web. Another step might be :
Which is useful in a wide variety of use cases. Then consider a step like:
That would be useful for many use cases as well, for example, a journal that wishes to distribute PDF and HTML.
While these are all very useful conversions/validations in themselves, imagine if you could take any of these steps and chain them together:
- convert MS Word docx to HTML
- convert HTML to PDF
So, you now have a ‘recipe’ comprising of several steps that will take a document through each step, feeding the result of one step into another, and at the end you have PDF and HTML converted from a MS Word source file. Or you could then also add validations:
- convert MS Word docx to HTML
- convert HTML to PDF
- validate HTML
That is what INK does. It enables file conversion experts to create simple steps that can be reused and chained together. INK then manages these processes in very smart ways, taking care of error reporting, inspection of results for each individual step, logs, resource management and a whole lot more. In essence it is a very powerful way to easily create pipelines (through a web interface) and, more importantly, takes care of the execution of those pipelines in very smart ways.
I think, interestingly, conversion vendors themselves might find this very useful to improve their services, but the primary target is publishers.
In many ways, INK is actually more powerful that what we need right now. We are using it primarily to support the conversion of MS Word to HTML in support of the Editoria platform. But INK is well ahead of that curve, with support for a few case studies that are just ahead of us. For example, INK supports the sending of parameters in requests that target specific steps in the execution chain, and it supports accounts for multiple organisations, and a few others things that we are not yet using. It is for this reason that we will change our focus to producing steps and recipes that publishers need since it doesn’t make sense to build too far ahead of ourselves (I’m not a fan of building anything for which we don’t currently have a demonstrated need).
These steps will cover a variety of use cases. In the first instance we will build some very simple ‘generic steps’ and some ‘utility steps’.
A Utility Step is something like ‘unzip file’ or ‘push result to store x’ etc…general steps that will be useful for common ‘utility operations’ (ie not file processing) across a variety of use cases.
A Generic Step is more interesting. Since there are a lot of very powerful command line apps out there for file processing we want to expose these easily for publishers to use. HTMLTidy, Pandoc, ebook-convert for example, are very powerful command line apps for performing conversions and validations etc. To get these tools to do what you want it is necessary to specify some options, otherwise known as parameters. We can currently support the sending of parameters (options) to steps and recipes to INK when requesting a conversion, so we will now make generic steps for each of these amazing command line apps.
That means we only have to build a generic ‘pandoc’ step, for example, and each time you want to use it for a different use case you can send the options to INK when requesting the conversion.
The trick is, however, that you need to know each of these tools intimately to get the best out of them. This is because they have so many options that only file conversion pros really know how to make them do what you need. You can check out, for example the list of options for HTMLTidy. They are pretty vast. To make these tools to do what you need it is necessary to send a lot of special options to them when you execute the command. So, to help with this, we will also make ‘modes’ to support a huge variety of use cases for each of these generic steps. Modes are basically shortcuts for a grouping of options to meet a specific use case. So you can send a request to run step ‘pandoc’ to convert an EPUB to ICML (for example) and instead of having to know all the options necessary to do this you just specific the shortcut ‘EPUBtoICML’…
This makes these generic steps extremely powerful and easy to use and we hope that file conversion pros will also contribute their favorite modes to the step code for others to use.
Anyway… I did intend to write about how INK got to where it was, similar to the write up I did about the road to PubSweet 1.0. I don’t think I have the energy for it right now so I will do it in detail some other time. But in short … INK has its roots in a project called Objavi that came out of FLOSS Manuals around 2008 or 2009 or so. I’ll get exact dates when I write it up properly. The need was the same, to manage conversion pipelines. It was established as a separate code base to the FLOSS Manuals book production interfaces and that was one of it’s core strengths. When booki (the 2nd gen FLOSS Manuals production tool) evolved to Booktype Objavi became Objavi2. Unfortunately after I left the conversion code was integrated into the core of Booktype which I always felt was a mistake, for many reasons of which I will leave also for a later post. So when I was asked by PLoS to develop a new Manuscript Submission System for them (Tahi/Aperta) I wanted to use Objavi for conversions but it was no longer maintained. So I initiated iHat. Unfortunately that code is not available from PLoS. Hence INK.
The good news is, this chain of events has meant INK, while conceptually related to Objavi and iHat, is an order of magnitude more sophisticated. It fulfils the use cases better, and does a better job of managing the processing of files. It also opens the door for community extensions (Steps are just a light wrapper, and they can be released and imported as Gem files into the INK framework).
At this moment we are looking at a number of steps, still deciding which to do first so if you have a use case let us know! A beginning list of possible steps is listed below:
Utility steps
- Zip/tar into an archive (or unzip/untar)
- Third-party API call
- Collect all modified files from previous steps
- Email all files
- Download a file from a URI
- SFTP files to external store
- Generic terminal command
Generic Steps
- Calibre
- Mogrify (batch image processing)
- Convert (Imagemagik command)
- HTMLTidy
- PDFTKF
- Vivliostyle
- Pandoc
- WKHTMLTOPDF
Steps
- HTML Validation
- JATS Validation
- Plagiarism checks
- Interpolation of document structure and extraction/annotation of parts (Abstract, methods, results etc)
- Subject matter taxonomy identification
- Image extraction
- DOI Assignment and registration
- EpubCheck (being written by Richard Smith-Unna)
- Natural Language Processing to identify authors, title, institution names, etc in an academic paper
- Identify place names in a document
- Identify people names in a document
- Convert HTML body to JATS
- Create valid JATS metadata
- Merge JATS body and metadata
- Syndicate content to various services
- Push to Continuum