So, I think I’m formulating something of a design strategy for publishing workflows. I’ll call it, for now, the 1+1 Method. It is not a facilitation methodology like the Cabbage Tree Method, but more of an approach for encapsulating workflows within the simplest and most flexible system possible.
This is very much a work in progress.
The basic idea comes down to this – workflows seem complex when you map them out. There are many forks and eddies and cul de sacs, as well as seemingly ad hoc tasks and unique circumstances. When you map out a workflow like this, you tend to get a complex route with many optional routes determined by a variety of variables and dependencies.
If you build a system that ‘hard codes’ that logic, then you face a number of problems, the most important being:
- you tend to create a system that reflects the present with only slight optimisation
- the system is prescriptive and inflexible and does not provide a path to future optimisation or, even possibly, radicalisation of workflow
So, how to avoid this? The answer is to design a system that is simple and can be optimised easily. I’m guessing you are thinking this is not really a very helpful answer! True enough… so let me attempt to break this down a little. What we need to do is first understand the organisational workflow, and then design a system that will enable this using the concept of ‘workflow spaces’. We need to create as few of these spaces as possible, and reuse as many of these spaces as possible. Further, we need to move people into these spaces at the moment that something is required of them.
I’ll get better at explaining this over the next months, I’m sure…I’m still working out a language and conceptual framing of this that is easy to communicate and understand….
But let’s look at a simple example… say, a Journal publishing workflow. In this example the workflow looks like this (keeping it relatively simple):
- an Author creates a new submission
- they fill out the required information and submit
- an Editor checks the submission and rejects the submission or assigns a Handler
- the Handler checks the submission and invites reviewers
- Reviewers accept or reject the invitation
- the Handler invites new Reviewers if necessary
- Reviewers write reviews and submit
- the Handler reviews the reviews and writes a decision to accept (goto (11)), reject (falls out of system), or ask for a revision
- the Author reads the decision and changes information if necessary and resubmits
- the Handler checks the revision, if all is ok it passes to production, else go to (4).
- Production
- Publishing
This is relatively a relatively simplified and generic Journal workflow, but you can see some forks in the paths… In my experience, most Journals have the above but with additional organisation-specific forkings and nuances. So the above is very much an ideal simplified state.
So… if you were to develop a system that takes the object, in this case a journal article, through this process, then you have a pretty complex conditional system. For example, there is two-fold circularity at play. First, there may be more than one round of reviews so the system has to be able to cope with this, second more than one round of reviews requires the same amount of decisions. That’s pretty complex already. The mistake most systems make is to try and program this path into the system in a very prescriptive and linear manner – which is difficult to do and, more importantly, hard to change once done.
So… how to get around this? Well… the answer is to use this emerging 1+1 Method I’m trying to articulate here. It is a simple way to encapsulate workflow, leaving the door open for further optimisation and innovation. To achieve this, you must walk an article (or whatever object it is) through all the steps of the workflow, but while doing so keep in mind the following:
- for each step, you are only allowed a maximum of 2 spaces. A common Dashboard, and one other space.
- push all light, single issue, tasks to the common Dashboard (space 1)
- if necessary, push the other tasks for that step to another space (space +1)
- reuse as many +1 spaces as possible, merge as many +1 spaces as possible
- indicate to each player/role they have something to do through Dashboard status/notifications, providing links to +1 spaces only at the appropriate moment (when they have a reason to use that space)
That’s pretty much it. What we are doing is telling a story to each participant (those that have something they need to do at a certain time), that there is something they need to do now and they have to go here (Dashboard or +1 space) to do it. When they have completed that task, the next participant gets their notification that something needs to be done and they are provided with the means to do it (an action provided on the Dashboard, or access to a +1 space).
So the journey of the article is managed through notifications at the appropriate time to the right people. This means that if we need to optimise the workflow, by either collapsing some steps or adding some steps, we don’t need to redevelop the whole prescriptive, linear workflow logic of the system. We simply need to tweak the order of notifications. Additionally, if we decide that some new innovative process should be introduced, we can do so by either tweaking an existing +1 space, or adding a new one (introducing it to the relevant participant at the relevant time through Dashboard notifications).
That keeps the system intact, and allows us to tweak and optimise/radicalise, as we go.
In the case of the Journal workflow above…. a 1+1 solution might look something like this:
- an Author creates a new submission – Dashboard
- they fill out the required information and submit – Submission Page
- an Editor checks the submission and rejects the submission or assigns a Handler – Dashboard (notification) + Submission Page (to check the Submission) + Dashboard (to accept or reject an assign Handler)
- the Handler checks the submission and invites reviewers – Dashboard (notification) + Submission (to check submission) + Reviewer Assignment Page (to manage Reviewer Assignment)
- Reviewers accept or reject the invitation – Dashboard
- the Handler invites new Reviewers if necessary – Dashboard + Reviewer Assignment Page
- Reviewers write reviews and submit – Dashboard + Review Page (includes submission)
- the Handler reviews the reviews and writes a decision to accept (goto (11)), reject (falls out of system), or ask for a revision – Dashboard + Decision Page (includes Submission and Reviews)
- the Author reads the decision and changes information if necessary and resubmits – Dashboard + Submission Page
- the Handler checks the revision, if all is ok it passes to production, else go to (4) – Dashboard + Submission Page
- Production
- Publishing
Of course, the above could be simplified still, or you could move some elements around. The reviewer assignment could, in some workflows, occur from the Submission Page. Or, perhaps, the reviews could be placed on the Submission Page…. these decisions are dependent on your organisational needs, what information needs to be shown to who etc…
The point is, the entire workflow above, with all its loops and eddies, has been created with just the following spaces:
- Dashboard (primary space for everyone)
- Submission Page
- Reviewer Assignment Page
- Review Page
- Decision Page
Just 5 spaces.
Now, the above is still in need of a better explanation. If you want to get a feel for how it works, I suggest you think of a workflow that you are involved in. Simplify it a little, since this is just a first exercise, and then write down all the steps in order. Now… work through this 1+1 method. Start with the Dashboard, rely on notifications to keep everyone in the flow (exposing to them to the right Dashboard action or space at the right time), and conservatively add a new space only when you are sure that:
- that action couldn’t easily be handled in the Dashboard
- there isn’t another space that could ‘house’ this action sensibly
Walk through it once. You could even do it with Post-it notes representing the spaces if you like. Then sit back, look at it and ask yourself could it be simpler?
Then play with it a little. When you have a good system you could even play with some innovative new spaces – put them into the steps and ask yourself what that space would look like and who should it appear to and when…. you’ll see how easy it is to innovate with a system that enables this kind of workflow….
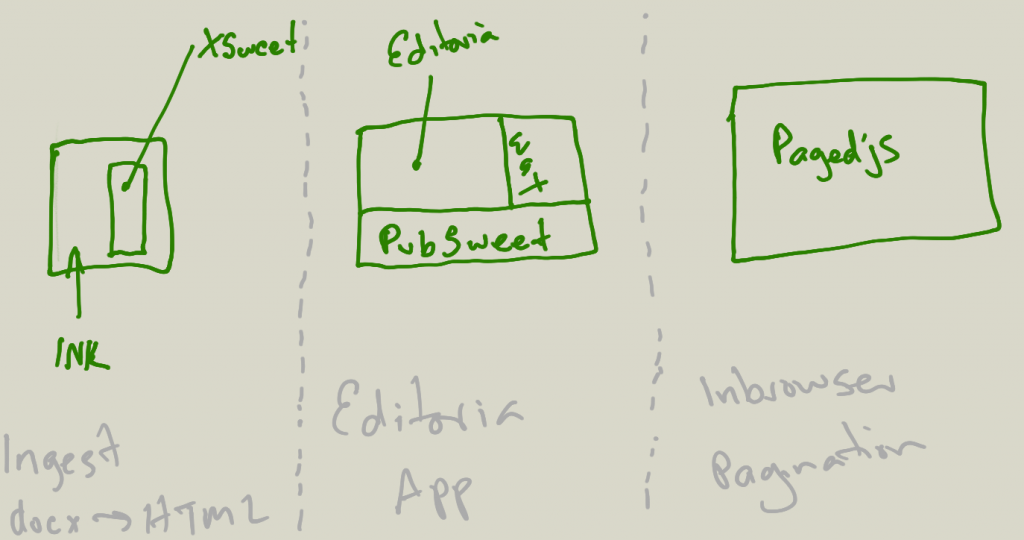
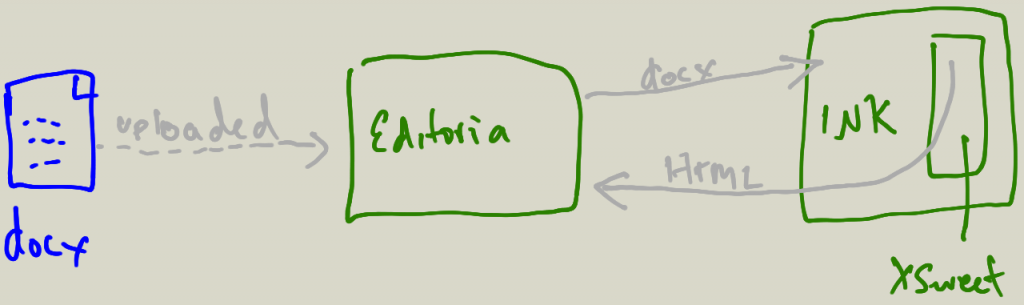
Needless to say…. that is why we created PubSweet… There might be more technologies like it, but if there are I’m not aware of them (let me know if you know of any). Also, if you have any feedback or thoughts on the above, especially on how to improve the explanation, then please let me know!