paged.jsCheck it out! Paged.js working with MathJax to render math in PDFs.
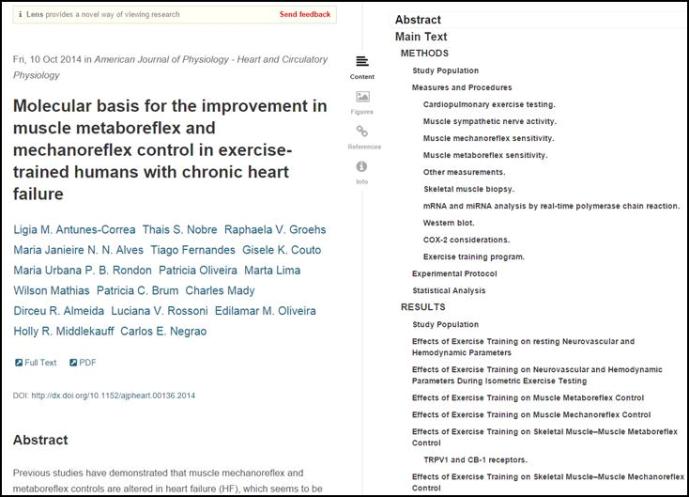
Below is a screenshot of the first page of the PDF mentioned in the article.

And you can get the PDF here… scientific-math-paper
paged.jsCheck it out! Paged.js working with MathJax to render math in PDFs.
Below is a screenshot of the first page of the PDF mentioned in the article.
And you can get the PDF here… scientific-math-paper
One from Nellie McKesson on her awesome new project Hederis.
https://www.pagedmedia.org/introducing-hederis-and-why-we-care-so-much-about-pagination/
And another from Erich van Rijn about Editoria and pagination.
https://www.pagedmedia.org/editoria-building-a-book-in-a-browser/
The past two posts I wrote on this topic looked at defining the difference between a text editor and a word processor. The posts in this series represent me ‘thinking out loud’ about what word processing needs to evolve into in the age of the web. So far, in my opinion we haven’t seen an evolution from the desktop given that Google Docs, as the premier example, looks and thinks pretty much like MS Word.
For this post I’m going to look at the first obvious visual differentiator between a text editor and a word processor. You notice this immediately when you open a word processor document, and you are skilled at manipulating its characteristics, but you might not think of it as a ‘feature’ as it is so present to almost be invisible – I’m talking about pagination. The first thing you notice when you open an existing document or start a new one is pagination, the boundaried space that makes your digital interface look like a piece of paper. Its not the sort of thing we think of when we think about a ‘feature’ but it is probably the strongest differentiating characteristic that separates the two categories of software.
Why do we need pagination in a word processor? What purpose does it serve?
There are a number of purposes. Picking them off one by one:
So, what to make of this. First, pagination is pretty essential to how many people use a Word Processor. It’s hard to think we can do without it. We might be able to achieve some of the above without a page paradigm. We could probably reasonably easily overcome the first 4 issues above – for example, we could provide word counts + ‘approximate page count’ indicators to give an idea of ‘how much’ content there is, provide a hierarchal navigation view of headings instead of page numbers for navigating around a document and as a ‘table of contents’ as Google Docs and eLife Lens (based on Substance.io) does.
In addition, there are a number of ways to indicate the reading position in a document that do not require page numbers – check out this example (thanks to Julien Taquet for this tip), and it is also possible to limit the CPL without providing page boundaries in the design as Wax Editor does.
However…the show stoppers really are the last 3 from the list above (to summarise again) –
It is difficult to argue that we could easily, or completely, throw away the page based paradigm based on these three items. So…does that mean Word Processors will be forever tied to the rather ugly page that you see floating like an existentially blank canvas every time you start a new document? Will web-based word processors forever be stuck in this paper paradigm?
My argument is no. We don’t need the page. Or at least, right now, in many use cases we can throw it away. The examples I used above provided clear cases where we need to directly correlate what you see when you create a document to the final result – whether for screen-based display, or print. But not every use case is like this. What is one of the biggest situations where you do not require a strict co-relation like this? Publishing.
I think I might hear you thinking ‘huh’? Afterall, if there is one industry that actually does require pagination it is the publishing industry (thinking in terms of the book and journal publishing sector for now, excluding newspapers, magazines etc).
That is true. However, the publishing industry doesn’t distribute to their readers a journal article as an MS Word file, or a book as a directory of MS Word files. They distribute unpaginated (usually) HTML files on the web, paginated PDF, EPUB files with various approaches to pagination, or paper. They generate these files by sending their source files (often MS Word) to an external vendor or in-house designer, who imports them into any number of design environments and converts this into the required formats.
Pagination comes ‘at the end of the line’ so to speak. Hence, unlike the typical home or office environment, there is no 1:1 correlation between what you see in word processors and what is finally distributed. So the needs of a word processor for a general user might be different to the needs of publisher. That, in itself, is pretty interesting. What if we could imagine specific word processors for specific use cases….
However, you will notice that word processors take a one-size-fits-all approach. We don’t have one word processor for book authors, one for publishers, one for lawyers (etc etc etc)…that is not to say we don’t need to differentiate these use cases and look at the specific needs of each. Interestingly, developing web based environments takes a lot less work that developing desktop applications and things have moved on since MS Word first hit the shelves. The web gives us substantially more room for modularity and customisation. With web-based word processors, every feature can be a configurable option. Don’t want or need track changes? That’s ok… remove it… Need a Diacritics interface? Easy… add it. Don’t want pagination? Remove it.
The point is, we can start building web based word processors that are highly customisable and can be configured to meet individual use cases. We haven’t seen that so far in word processing, Google Docs has also chosen a one size fits all – the only real difference here between GDocs and MS Word is that their ‘all’ is a smaller group. But that doesn’t mean we can’t do it if it makes sense. Technically it is very feasible and, as it happens, it’s the approach we are taking with the Wax Editor.
So, let’s imagine we have our own word processor made specifically for publishers. Do we need pagination? What role does it play in publisher workflows?
It is true that relative to the total number of publishers out there I’ve seen inside a small % of publishers’ workflows. However, interestingly, with each new publisher I work with I am seeing, more or less, the same workflows and from what I have seen so far, MS Word files are used widely to support a kind of early page-prep workflow. Publishers check and improve the content of course, but they also make sure certain elements are in place that will affect the final design. They check, for example, if all paragraphs are correctly indented. They check if images are in the right place, they check if headings are marked correctly and that no levels have been jumped etc. These all affect the final paginated outcomes, but none of this requires working within, or manipulating, pagination as it appears in the word processor. Checking the results of pagination (including page numbers, running heads, widows and orphans etc) comes when publishers do their page proofs ie. when they check the PDF before print or distribution (sadly, many publishers don’t check EPUB very thoroughly but just accept that it ‘is what it is’). Publishers don’t currently check the results of pagination, as it will appear in their final distributable form, in the word processor. So pagination in the word processor, at least on this point, is a little redundant.
So… my point is, if we get down to it, pagination features in a word processor are not required when you are working inside a publisher to prepare a document for publishing. We could instead use an unpaginated environment with a navigation based on document structure (not pages), word count as a metric for how much content there is, and simple constraints on CPL that do not look like a boxed, bounded, page.
But…what about the need to print on your office or home printer? Interestingly, I think this gets to the crux of the matter. Unbounded, flowable text, in a word processor does not mean you can’t print. It only means what you see in the word processor won’t have a one-to-one co-relation, with regard to pagination, to what is printed. But the big question is – is this acceptable to publishing staff? Can we get them to let go of thinking, a product of many years of legacy word processing user experience design, that the pagination in the browser ‘must’ correlate to the pagination that comes out of their home or office printer. My experience designing such systems alongside publishing staff leads me to believe his is possible. In fact, the University of California staff designed the Editoria system which features the Wax Editor which displays content sans pagination. The challenge is – it is up to us to show them that throwing pagination out works in their favour.
Before I go on to why throwing out pagination can be a convincing argument, I want to indulge in a rather lengthy aside and state that throwing out pagination is not the same as ‘not printing’. The results of printing from an ‘unpaginated’ form in a web-based word processor can be beautiful and a more consistent experience than printing off ‘any old’ word file. This is because we can use CSS print styles to make beautiful looking results that come out of your home printer. The point is only that the pagination will not correlate to what you see in the word processor. But you can have other things – for example, you could render pages for printing at any time that look like your final output. Quite probably this statement is news, or confusing, to you. It needs extensive explanation. But the idea, in basic form, is that content in HTML based word processors can be shaped by CSS into paginated form in the browser. This process allows you to automatically format the content into book or article form including running heads, page numbers, widow and orphan control, multiple columns (if desired) while also generating the table of contents and even indexes. This can be achieved, for example, by platforms that leverage tools like Vivliostyle. I’ll get to this in subsequent posts, maybe even the next one (in the meantime, you may wish to read this). For now, I want to leave this issue to the side but make the simple point that content that is not bounded by a page in the word processor can still be printed and, further, the results can be more beautiful and consistent than what you get by printing from Google Docs or MS Word today. However, the process of printing will feel slightly different because ‘how you print’ will be to first render a view that is conformant with your printer and then print. It’s not much different to how it is done now because this is how print-preview works in word processors today. When we print, we commonly choose the page format at print time, although most of the time we leave it at its defaults because we know that what we have seen in the word processor is the same as what will come out of the printer. ‘The new way’ would mean you will need to pay more attention to the second step – checking the formating in print preview before printing. Which is why I emphasise that the process will feel slightly different, the actual change in behaviour is minimal, if anything at all. But it would be a mistake to conflate user experience with user behaviour. The experience of the software is nothing to be brushed lightly aside, it can be a very strong impediment to new ways of working. So how things feel need to be taken into account. Which is why I think, ultimately, we will need other arguments to help many (not all) ‘get across the line’.
Which brings us back to the question – what is the advantage of not having pagination? If we can do away with it we have far more options for making beautiful experiences. The bounded page that all word processors commonly present is, in my opinion, hideous. It constrains how you construct a user interface, how people feel about that interface, and how people work. If we can free ourselves from it I think we open the door for much better experiences and innovations on what a word processor can do and be which also means, in the publishing industry, we can start innovating around word processor workflow.
Additionally, removing pagination from the word processor in publishing workflows is better aligned with how publishing works. Publishing formats do not share the same pagination. An EPUB page is not going to be the same page as the content displayed on the net, in a Kindle, in a PDF, or in a book. Might as well let that one go. If we need pagination at all, it needs to look like the final output and we need to get it earlier in the workflow than what currently occurs. Currently, publishers only see this after the content has been through their workflow and gets ingested and output to various formats by a designer, production staff, or external vendor. However…. HTML based word processors that leverage tools like Vivliostyle (mentioned above) enable the content to be paginated to all these formats on the fly. That means you can have ‘page proofs’ anytime you want in the process. So, letting go of pagination in the word processor, coupled with the ability to create these various paginated forms at any time, is an advantage to publishers. Publishers don’t need to wait for page proofs from a designer before they can tweak elements in the content (eg placement of images) to make the pages flow better in the final output. They can render, check, and tweak at any moment. From this point of view seeing one kind of pagination in the browser, especially one that conforms to a generic printed page coming out of the office printer, as it does now, is counter intuitive. But, I don’t expect many publishing staff to accept this by argument alone. We have to first get most people to experience this, and other benefits of a pagination free experience in a word processor, before they can start moving the way they work forward.
My conclusions? Well, I think it will be a while before we can convince the general user to drop pagination. But web based web processors allow us to build much more customisable experiences and avoid the ‘one size fits all’ approach. We can build to meet publishers’ specific needs and it is because of this that I believe we can produce software that will convince publishers to make the conversion sooner. This is because we can make the experience for them better if we drop pagination. The pages, which they look at for hours on end, can be cleaner, easier to read, and less tiring over long periods of time. We can also start using space more effectively by removing borders around pages (with their attendant inner and outer margins). And lastly, I think it is important to remove pagination from word processors for publishing workflows because it helps disambiguate what you see in the word processor from the final, designed and paginated, results. This latter point has positive knock-on effects that I will come to in other posts. Couple all this with the ability to ‘paginate on the fly’ (so to speak) at print time (for domestic/office printers) or to generate ‘page proofs’ of many target formats, and we have a winner.
More thoughts coming in later posts!