Just been in Athens, hanging out with the Coko Athens crew – Yannis, Christos, Giannis and Alexis. A thoroughly good bunch.
I think before I’ve mentioned how proud I am to work with them and what we are achieving. I mean, it’s a teamof 4 people and together they are developing 3 publishing platforms and a sophisticated web-based word processor … essentially 4 platforms – Editoria, xpub (Journals), micropubs, and Wax (editor)… I mean… talk about punching above your weight! More than that, we have fun doing it.
Every month I come to Athens and we discuss the coming month’s roadmaps. I come for a few days, we drink a lot of Freddo Espresso and sometimes (at the other end of the day) some margaritas. In between, we order some iffy delivery food and plan the future.

The roadmapping sessions involve us going through each platform together, and looking at last month’s roadmap. Discuss the next priorities and approaches, and then commit those to the next month’s roadmap for that project. It’s pretty interesting and super great to have everyone involved in the process. We get a good wide range of opinions and at the same time give everyone ownership of their own project. This is what collaboration is all about.

So some short notes here on this month’s roadmapping…
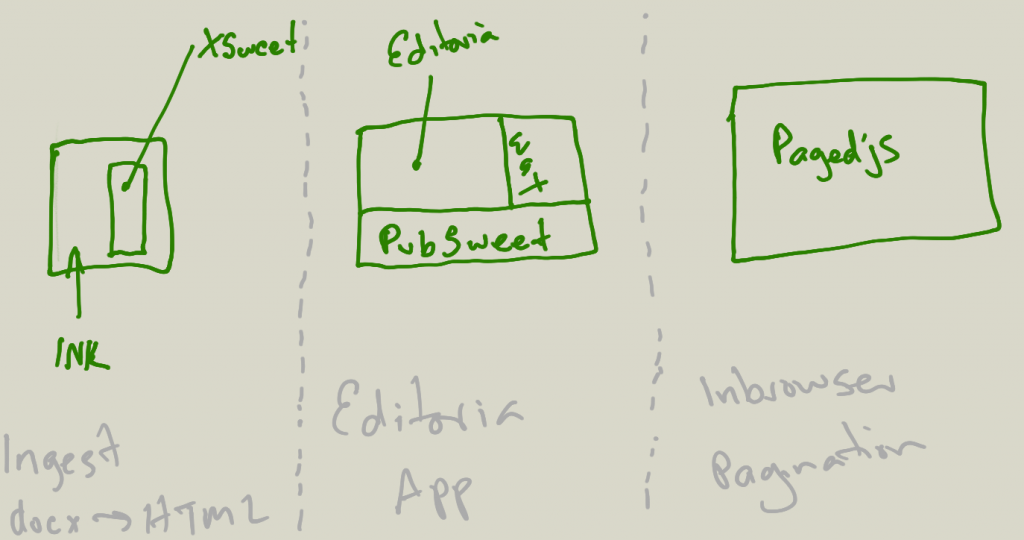
Wax – We have come very close to a fully functional web-based word processor based on the Substance libs. It is looking amazing with support for the normal editor stuff – headings, images, bold etc – plus some amazingly sophisticated features including track changes, notes management (more complex than it sounds), thread-based commenting/annotations, diacritics support … and a lot more… However, we have decided to start building a new Wax based on the ProseMirror libs, mainly because there is a lack of community around the substance.io libraries and we wish to de-risk ourselves going forward. So we’ll finish off Wax 1.0 with a Substance upgrade which will also bring us table support, nested lists, and some other issues. At the same time we will continue developing the new Wax (we already have something basic working) – first by adding some interesting widgets that the ProseMirror community have built, and then by building a simple plugin structure for editor widgets. We split Wax roadmaps up, but the important stuff for the current wax is listed in the Editoria repo – https://gitlab.coko.foundation/editoria/editoria#roadmap
xpub – we are now fixing a few bugs in the journal system and moving forward with migrating to the new shared data model that was collaboratively designed at the recent PubSweet meeting in Cambridge (UK). This will include some initial research into GraphQL (part and parcel of the migration). Part-way through August, Giannis is attending the Libero workshop at eLife and will work on that with the eLife team for 2 weeks. Libero is the open source web-delivery part of the publishing cycle that eLife has designed and is about to build. So we want to put into that effort and learn what we can. That also means the actual migration to the new data model will happen after those 2 weeks ie. We’ll start it on Sept 1. More info here – https://gitlab.coko.foundation/xpub/xpub#roadmap
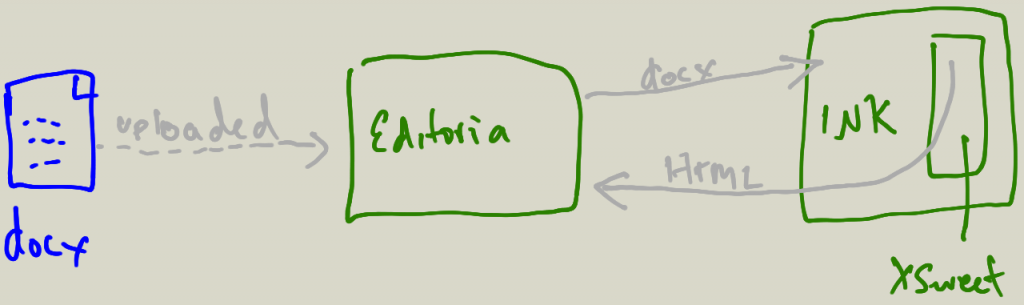
Editoria – this is coming along fast. Alexis just added EPUB export and overhauled the workflow management tool. Editoria is pretty much ‘fully fledged’ although we have many ideas for new features – however much of this will wait until the Editoria community meeting in San Francisco in October. In the meantime, we are being good open source citizens and writing a lot of under-the-hood tests. Alexis will also spend a day or so writing a new Authsome mode to match the Book Sprints workflow to show that the auth app Jure (PubSweet lead dev) built is indeed plug-and-play. More info here – https://gitlab.coko.foundation/editoria/editoria#roadmap
Micropubs – we are developing a micropublications platform with the Wormbase crew. Its early days but ison schedule with the first thin slice. It contains complex integrations and complex submission forms. But Yannis is making good speed, so more of the same! https://gitlab.coko.foundation/micropubs/wormbase#roadmap
It is, as I said above, an awesome team. I’m very proud of what we are achieving together and I like to punch above our weight. Much more information coming soon about all of this as we go!
Spending a night tomorrow in the UK, and then to San Francisco for a meet with Kristen, attending FOO camp and many other bits n pieces.