paged.jsCheck it out! Paged.js working with MathJax to render math in PDFs.
Below is a screenshot of the first page of the PDF mentioned in the article.

And you can get the PDF here… scientific-math-paper
paged.jsCheck it out! Paged.js working with MathJax to render math in PDFs.
Below is a screenshot of the first page of the PDF mentioned in the article.
And you can get the PDF here… scientific-math-paper
…and it keeps on coming…example PDF from Julien using paged.js. HTML -> PDF using CSS to design and paged.js for the rendering. First page here, full PDF linked below.

If you are a ‘editor’ geek like me, you will find this new feature Christos built into Wax pretty cool…
If you don’t know what you are looking at, essentially, you can add inline refs to notes from within a note…which means, if the note numbering changes, it all gets automatically updated…no need to manually do it…
At the moment things are happening thick and fast at Coko, its hard to keep up! Anyways… this just in:
Editoria Community grows with addition of American Theological Library Association
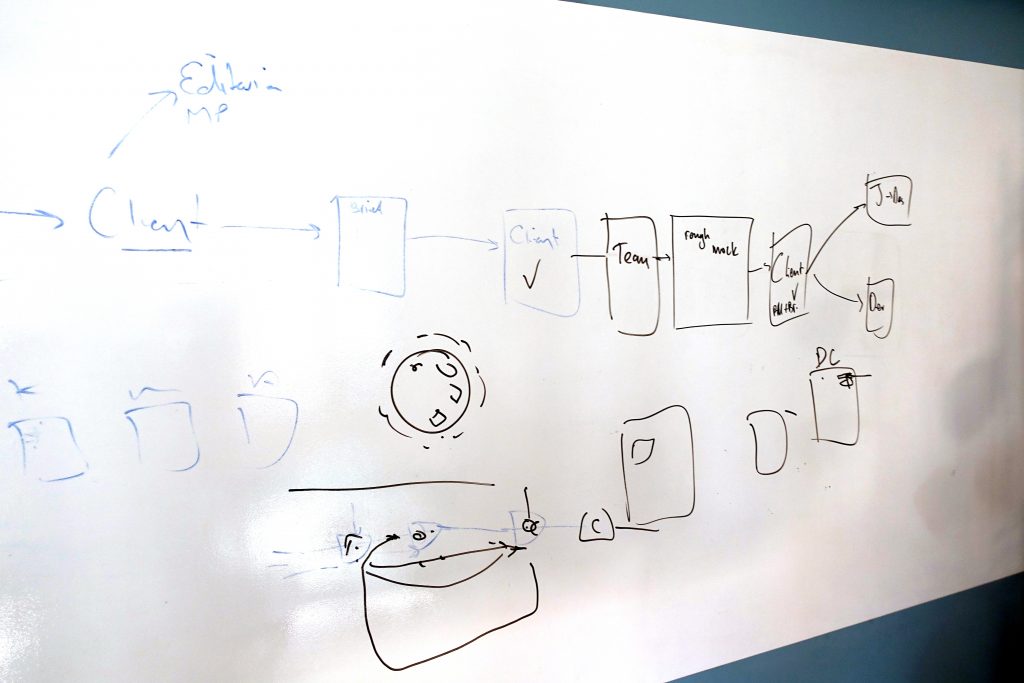
Had a great monthly roadmap meeting with the Coko Greek crew yesterday in Athens. We discussed and planned micropubs, Editoria, Wax 2, xpub-columbia/collabra, and chatted about Dan Morgan’s pizza theory for workflow, and stuff and things. Drank lots of coffee and this time had some yummy good for lunch. Always fun. Always productive. Fantastic bunch 🙂





Nice video from the Editoria crew!
I’ve been pondering some stuff in preparation for a presentation at Open Source Lisbon this week. In essence, I’m trying to understand Open Source and how it works… not to say I don’t know how Open Source works, we do it well at Coko…I mean to zoom up a level and really understand the theory and not just the mechanics. It is one thing to facilitate a bunch of people to meld into a community, it is quite another to understand why that is important, and what the upsides and downsides are on a meta level. If you take the ideals out and look purely at the mechanics from a bird’s eye view. then what, ultimately, makes Open Source a better endeavor than proprietary software? What is exactly going on?
I have some clues… some threads…but while each thread makes sense when you consider it on its own, when you combine them all it doesn’t exactly make a nice neat little montage. Or if it does, I am currently not at the right zoom level to see it clearly instead I see lots of different threads criss-crossing each other,
Ok…so enough rambling… what is it I’m trying to understand…well, I think when you embark on making software there is this meta category of methods known as the Systems Development Life Cycles (SDLC). Its a broad grouping that describes the path from conception of the idea, through to design, build, implementation, maintenance and back again etc…
Under this broad umbrella are a whole lot of methods. Agile is one which you may have heard of. As is Lean. Then there are things like Joint Application Design (JAD), and Spiral, Xtreme programming, and a whole lot more. Each has its own philosophy and if you know them you can sort of see them like a bookshelf of offerings…you browse it and intentionally choose the one you want. Except these days people don’t choose really, they go with the fashion. Agile and Lean being the most fashionable right now.
The point is, these are explicit, well documented, methods. You can even get trained and certified in many of them.
But… Open Source doesn’t have that. There isn’t a bookshelf of open source software development methods. There are a few books, with a few clues, but these are largely written to explain the mechanics of things and they seldom acknowledge context. I say that because the books I have read like this make a whole lot of assumptions and those assumptions are largely based on the ‘first wave’ of Open Source – the story of the lone programmer starting off and writing some code then finding out it’s a good idea to then build community instead of purely code therefore magnifying the effect. A la Linus Torvalds.
But its very down-on-the-ground stuff. I’m thinking of Producing Open Source by Karl Fogel, and The Art of Community by Jono Bacon. Both very well known texts and I have found both very useful in the past. But they don’t provide a framework for understanding open source. I’ve also read some research articles on the matter that weren’t very good. They tend to also regurgitate first generation myths as if open source is this magic thing and they struggle to understand ‘the magic’. In other words, I miss a ‘unified theory’, a framework, for open source…
I think it is particularly important these days as we are beyond the first generation and yet our imaginations are lagging behind us. There are many more models of open source now than when Eric Raymond described a kind of cultural method which he referred to as ‘the bazaar’ in his cathedral and the bazaar. We now have a multitude of ways to make open source and so the license no longer prescribes a first generational approach, producing open source is much richer than that these days.
As it happens, Raymond’s text does attempt to provide some kind of coherent theory about why things work although it often mixes ‘the mechanical’ (do this) with an attempt to explain why these processes work. It doesn’t do a bad job, there is some good stuff in there, but it varies in level of description and explanation in a way that is uneven and sometimes unsatisfying. Also, as per above, it only addresses the first generation ‘bazaar’ model. While this model is still common today in open source circles, it needs a more thorough examination and updating to include the last 15 years of other emergent models for open source. There are, for example (and to stretch the metaphors to breaking point), many cathedral models in open source these days that seem to work, and some that look rather like bazaar-cathedral hybrids.
Recently Mozilla attempted to make some sense of these ‘new’ (-ish) models with their recent paper on ‘archetypes’
https://blog.mozilla.org/wp-content/uploads/2018/05/MZOTS_OS_Archetypes_report_ext_scr.pdf
Here they kind of describe what reads as Systems Development Life Cycle methods…indeed they even refer to them as methods
The report provides a set of open source project archetypes as a common starting point for discussions and decision-making: a conceptual framework that Mozillians can use to talk about the goals and methods appropriate for a given project.
They have even given them names such as ‘Trusted Vendor’ and ‘Bathwater’ and the descriptions of each of these ‘types’ of open source project sound to me like they are trying to make a first stab at a taxonomy of open source cultural practices – so you can choose one, just like a proprietary project would choose, or self identify as, Agile or Lean. Infact, the video on the blog promoting this study pretty much says as much. It’s Mozilla’s attempt at constructing a kind of SDLC based on project type (which is like choosing a ‘culture’ instead of a method).
However it doesn’t quite work. The paper compacts a whole lot of stuff into several categories and it is so dense that, while it is obvious a lot of thought has gone into it, it is pretty hard to parse. I couldn’t extract much value of what one model meant vs the other, or how I would identify if a project was one or the other. It was just too dense.
Mozilla has effectively written a text that describes a number of different types of bazaars, and also some cathedrals, without actually explaining why they work – except in a few pages that sort of off-handedly comment on some reasons why Open Source works. I’m referring to the section that provides some light assertions as to why Open Source is good to:
But this is the important stuff… if these things, and the other items listed in that section are true (I believe they are), they why are they true? Why do they work? Under what conditions do they work and when do they fail?
In other words, I think the Mozilla doc is interesting, but it is cross cutting at the wrong angle. I think a definition of archetypes is probably going to yield as many archetypes as there are open source projects – so choosing one archetype is a hopeful thought. Also the boundaries seem a little arbitrary. While the doc is interesting, I think it is the characteristics listed in the ‘Benefits of Open Source’ section of the Moz doc that are the important things to understand – this is where a framework could be built that would describe the elements that make open source work…..allowing us to understand in our own contexts what things we may be doing well at, what we could improve, what we should avoid, useful tools etc
The sort of thing I’m asking for is a structured piece of knowledge that can take each of the pieces of the puzzle and put them together with an explanation of why they work…not just that they exist and, at times, do work, or are sometimes/often grouped together in certain ways. An explanation of why things work would provide a useful framework for understanding what we are doing so we can improvise, improve our game, and avoid repeating errors that many have made before us.
With this a project could understand why open source works, and then drill down to design the operational mechanics for their context. They could design / choose how to implement an open source framework to meet their needs.
Such texts do exist in other sectors. Some of these actually could contribute to such a model. I think, for example, the Diffusion of Innovations by Everett Rogers is such a text, as is Open Innovations by Henry Chesbrough. These texts, while focused on other sectors, do explain some crucial reasons why open source works. Rogers explains why ‘open source can spread so quickly’ (as referenced in one line in the Moz doc), and Chesbrough provides substantial insights into why innovation can flourish in a healthy open source culture, and how system architecture might play a role in that.
Also the work of John Abele is important to look at and his ideas of collaborative leadership. As well as Eric Raymond’s text…but it all needs to be tied together in a cohesive framework…
This post isn’t meant to be a review of the Moz article. It reflects the enjoyment I have gained from understanding elements of open source by reading comprehensive analysis and explanation of phenomenon like diffusion and open innovation. These texts are compelling and I have learned a lot from them which have helped when developing the model for Coko because at the end of the day, there is no archetype that exactly fits – it is better to construct your own framework, your own theory of open source, to guide how you put things together, than to try and second guess and copy another project from a distance. Its for this reason that I would love to have a unified framework for open source that takes a stab at explaining why all these benefits of open source work so I can decide for myself which ones fit or how they fit with the projects I am involved with.
I have a Kobo ereader (Kobo H2O). I’ve been using it to make annotations but by default it only allows you to export the annotations to Facebook (eeek!). I found a wonderful posting that described how to export to a text file. Whoot! Here if you need it.
Reading Open Innovation – a thesis evolved by Henry Chesbrough in 2003. I have also the follow-up book published in 2006 which is a collaboration with other researchers going through his earlier thesis.
I’m researching this as I’m interested in what current literature exists that explains Open Source and why / how it works which is not from the Open Source domain. Books that emanate from the Open Source domain tend to be religious in nature and it is also true that most attacks against Open Source take it from the religious angle… so having literature that endorses the model which is not open source evangelicalism is very useful.
Previous to this I found a lot of value in The Diffusion of Innovations (originally published in 1962) by Everett Rogers.
Open Innovation and the Diffusion of Innovations separately explain quite a bit about why Open Source works, and I think I’ll post more about this as it becomes clearer in my head.
Chesbrough’s thesis can be summed up in one quote
The Open Innovation paradigm treats R&D as an open system. Open Innovation suggests that valuable ideas can come from inside or outside the company and can go to market from inside or outside the company
Essentially it is the admission that any one company doesn’t have all the smart teams/people/ideas. So how about re-imagining innovation and release it from a so-called ‘vertical innovation’ model, where all the R&D is done inhouse and where IP (Intellectual Property) is jealously guarded, to a open model where innovation essentially comes through collaboration with orgs and individuals outside the company.
From an Open Source point of view this is a ‘duh’ moment… Open Source has long expounded this approach. But…I have never found it well explained…
So it is good to find this argument made elsewhere and in clearer terms…but unfortunately the Chesborough thesis was published in 2003 when Open Source was still very young. Consequently Chesbrough reads Open Source as a idealistic and altruistic movement… he doesn’t really consider open source projects to have a business model and a business model is central to his thesis. Its a pity as Open Source has moved on since then and there are a lot of very successful and interesting examples of Open Source business models. But if you sorta squint while you are reading, and blur out the dated-ness then there is a lot of stuff that could just be quoted verbatim that makes a strong argument for Open Source as seen through the lens of the Open Innovation thesis.
Thats pretty interesting as, combined with the Diffusion of Innovations, these two bodies of work explain the value (and consequently provide a rationale which does not come from the open source sector directly) of open source. Open Innovation explains why open source is a good idea if you are a company whose business requires software to function in its core offerings, and the Diffusion of Innovation theory helps us understand why open source can beat closed source software in the arena of adoption.
The point is, if you can combine the two you have a winner – a model that enables rapid adoption and innovates faster than closed alternatives/competitors. If you can marry successful commercial activity to this you have something very powerful that can potentially wipe out the existing proprietary offerings – which is what we need in the publishing sector. The aim of what we are now doing in Coko, in this post-foundational stage, is to seed the commercial activity around the very healthy core of community technologies we have built.
Anyways… here are some quotes I liked from some of the chapters….Some of the quotes come from this chapter by Joel West and Scott Gallagher http://web.simmons.edu/~weigle/INNOVATION/Patterns%20of%20Open%20Innovation.pdf
Open Innovation is the use of purposive inflows and outflows of knowledge to accelerate internal innovation, and expand the markets for external use of innovation, respectively. Open Innovation is a paradigm that assumes that firms can and should use external ideas as well as internal ideas, and internal and external paths to market, as they look to advance their technology. Open Innovation processes combine internal and external ideas into architectures and systems. They utilize business models to define the requirements for these architectures and systems. The business model utilizes both external and internal ideas to create value, while defining internal mechanisms to claim some portion of that value. Open Innovation assumes that internal ideas can also be taken to market through external channels, outside the current businesses of the firm, to generate additional value
…useful knowledge is scarce, hard to find, and hazardous to rely upon (a root cause of the NIH syndrome). In Open Innovation, useful knowledge is generally believed to be widely distributed, and of generally high quality
IP becomes a critical element of innovation, since IP flows in and out of the firm on a regular basis, and can facilitate the use of markets to exchange valuable knowledge. IP can sometimes even be given away through publication, or donation.
Recently, open source software has emerged as an important phenomenon that utilizes external knowledge in a network structure (Lerner and Tirole 2002; O’Mahoney 2003; Dedrick and West 2004; von Hippel 2005)
Most software users would face significant switching costs in using some other software package, due to some combination of retraining user skills and converting data stored in proprietary file formats. As Arthur (1996) observes, software thus has tremendous positive returns to scale, generally allowing only one (or a small number) of winners to emerge.
These winners are tempted to extract rents from their customers by increasing prices and creating additional switching costs to protect those rents (Shapiro and Varian 1999). From these production economics, commercial software firms seek to build complete systems to meet a broad range of needs, in hopes of forestalling potential competitors and protecting high gross profit margins
In other cases, a system architecture will consist of various components. Some mature (or highly competitive) components may be highly commoditized, while other pieces are more rapidly changing or otherwise difficult to imitate and thus offer opportunities for capturing economic value. Two open source examples are the IBM’s WebSphere and Apple’s Safari browser…
…Customers access the WebSphere e-commerce software using standard web browsers, so IBM originally developed a proprietary httpd (web page) server. IBM later abandoned its server for the Apache httpd server, recognizing that it would be wasting resources trying to catch up to the better quality and larger market share enjoyed by Apache (West 2003). Today, IBM engineers are involved in the ongoing Apache innovation, both for the httpd server and also related projects hosted by the Apache Software Foundation (Apache.org website)
