Month: June 2021

One Enormous Step at a Time – Now JATS
So, at Coko I’ve pondered, designed and delivered several major technologies. Along this road I’ve been scoffed at a lot when I’ve advocated for each of these approaches, but then we delivered them.
I’m thinking of things like a typesetting engine – Pagedjs. No one in their right mind opts to commit time and resources to building a new typesetting engine. Particularly one with a wholely speculative approach. But now we have something astonishing in Pagedjs and the results speak for themselves. We can now achieve ‘InDesign level’ output – as per this demo:
I’m also thinking of Wax – a web based word processor. We needed a word processor capable of delivering the functionality and performance publishers get from Word. And we did it. It is also an editor that works with a ‘HTML-compliant’ data structure. When I advocated for this approach 15 years + ago I was not taken seriously. To be fair, the tech at the time wasn’t up to it. But now it is and we have done it. Not only that, the extensible framework is now going in directions that are fascinating including plugins for the generation of question models for textbooks, test banks etc.
I’m also thinking of PubSweet – the framework for building publishing platforms. When we announced this approach most folks thought we had bitten off too much. We had to bet on parts of the stack that were as yet unproven bets. But it paid off. We did it. We now have a dozen or more platforms built on PubSweet – https://coko.foundation/product-suite/.
That and XSweet – a high fidelity MS Word to HTML converter. Which sounds simple, but the thinking behind it reflects an usual but effective approach.
And then there are many platforms including Editoria (shown above in the video) and the new platform Kotahi – which is a hard platform to describe because it simultaneously enables folks to pursue traditional journal workflows, while enabling whole new ways of working.
While we have been building all of this we have taken unusual approaches to everything. We have had some failures – our first version of Wax bet on the wrong third party libs. But on the whole we have taken bets and they have come in well.
One small new bet in the making is with our new product – Flax – it is a publishing front end built on an existing static file CMS called Eleventy. It is a sane approach in our opinion, but probably for many in the publishing sector it looks like an odd choice. It might seem to ‘low fi’. But we believe that technology can fulfill a need right now at low cost. It is easy to maintain and flexible. It doesn’t yet have everything we need, but that hasn’t stopped us from making successful bets before.
So… Flax is, IMHO, a small bet. I think it is low risk. A bigger bet is our intended approach for producing JATS.
JATS, Journal Article Tagging Suite, is a necessary evil. I’d actually argue it is *unnecessary* and evil. But many folks still need to produce if for various archival and data-transferal (eg migration) purposes.
The way this problem is usually solved is to either build your own XML editor, or throw the content over the wall to a publishing vendor to convert the (usually) MS Word files to JATS.
Our approach is going to be different. Essentially it will take HTML and go through what folks sometimes call ‘up conversion’ – that is a process where you try to go from a less structured document format, to a more structured document format. In this case we will go from an HTML-compliant format, to structured JATS.
How will we get there? Well, Kotahi, (as above) ingests docx into the platform via XSweet. It is then capable of being edited in the platform via Wax. In addition to this, we have all the submission data captured in known blocks through submission forms in Kotahi.
So, we know what the article structure is, in a basic hierarchical form (headings etc) and we know what blocks of data (from the submission form) are. We know what the author information is, for example, from the submission form.
So, to get to JATS, which more or less requires us to add:
- more block level structure (abstract, method etc)
- embedded/nested data (author blocks etc)
We will enable the adding of these to the ‘HTML-compliant’ document via wax. To do this we will add the ability to highlight blocks to add the block level structure, and then we will enable the drag and drop placement of the nested blocks from the submission form. This keeps the whole approach firmly within the ‘WYSIWYG’ approach. Selecting blocks and drag and drop… something any publisher can do.
Its not an approach I see advocated for. But it is very doable and we will go down this path.
The advantage is that it puts the tools for producing JATS in the hands of the publisher. So small publishers can do this themselves without knowing anything about JATS. Larger publishers with larger volumes who still work with vendors can also use this production tool as it will be integrated into Kotahi. So it will be a place where the vendor enters into the system and works with the publisher to produce the JATS. I expect this will produce greater turn around times and higher transparency.
Wendell Piez and I did some thinking about this some time ago. Now it is time to try it out. To do this we will be partnering also with Amnet Systems.
Why is this a better solution than an XML editor? Well, the approaches I have seen where folks use an XML editor is that you must already have XML to load into it. So you must get from where you are to XML, and then use the editor. The approach I’m advocating is that you just start with a HTML-compliant hierarchical structure, and add additional structure and data to it progressively – without needing to know anything about XML.
The question is, why hasn’t this approach been tried before? It might have been tried, if you know of it let me know. But essentially I think there are a few issues that have prevented this kind of approach and it all comes down to the background thinking.
Generally folks have considered the creation of XML to be a complex problem, requiring complex solutions. Need XML? Ask the XML experts how to do it. What will they say? Get a tool that manages XML. This is ‘XML thinking’. It doesn’t allow for out of the XML-box thinking. It is also overly complex.
Next, folks think of XML as a file. But XML need only be a file at export time. There is no need for all the assets that go into creating that XML to be present only as an XML file. This is ‘file’ thinking, and prevents folks from seeing the next thing…
Journal systems are exactly that – systems. They contain both the article and the submission data. So you have all the things you need to create the XML within the system. So just munge the data together at the right moment by bringing all those elements within the system together. This solution requires thinking of how to leverage a journal system NOT how to manage a separate XML editor or XML creation process.
Anyways…that is what I have observed. I am sure there are many folks that won’t take this approach seriously. Its ok, we will do it anyways.
Tally Ho!
New Pagedjs release
First ever Kotahi Community Meet!
Just finished 🙂
New XSweet site
Wax site up!
Needs a quick copy edit but here ya go!
Aperture Moving to Kotahi
New Product Announcement
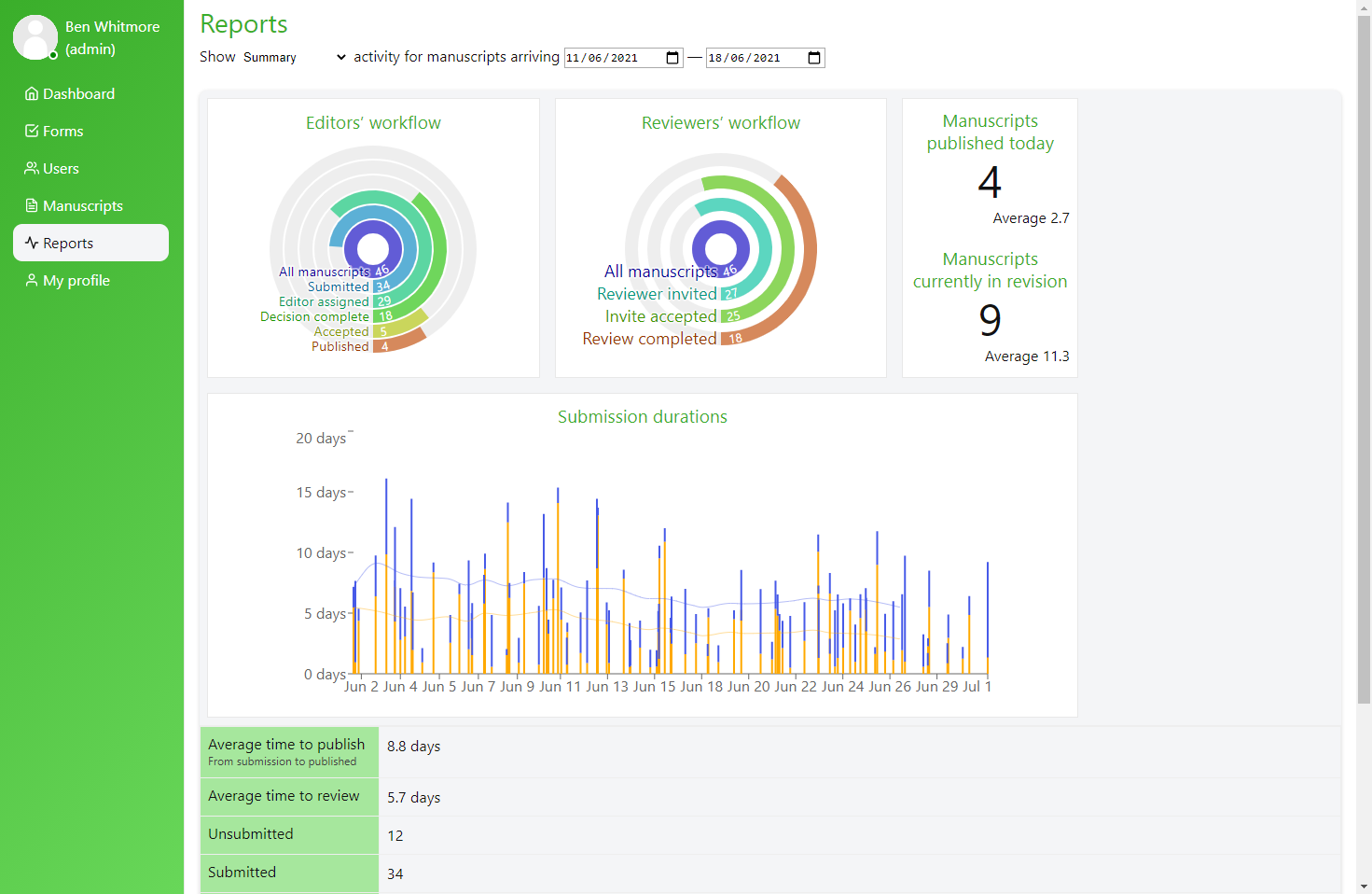
Kotahi reports
Comprehensive reports currently being built into Kotahi. Due in the next weeks.
Crazy
What Editoria can do now…