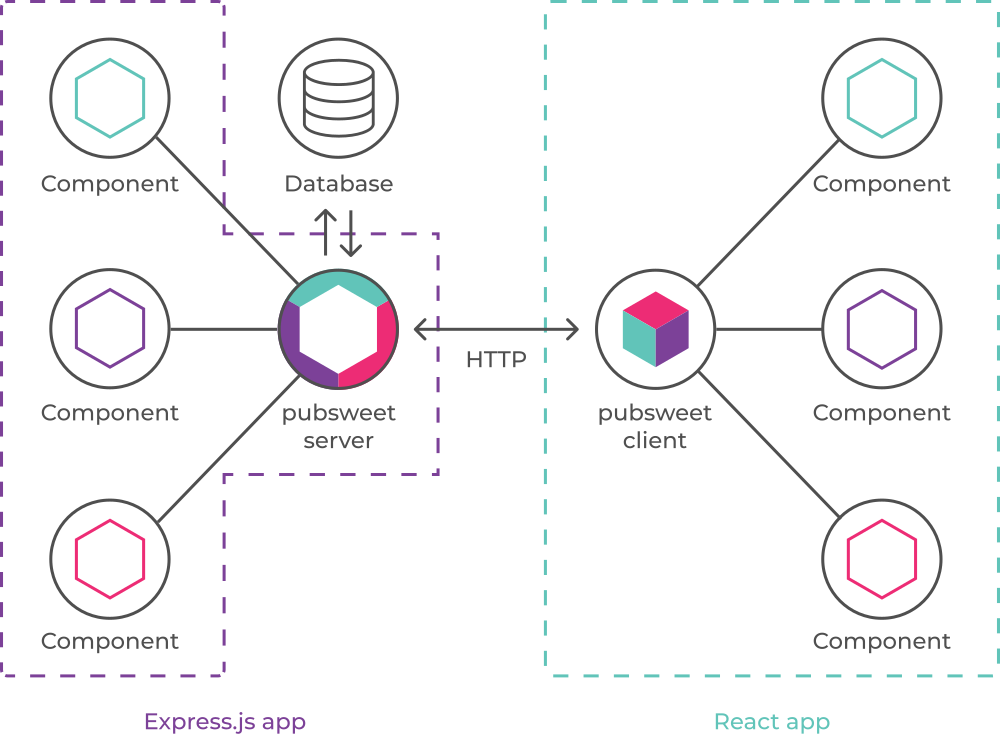
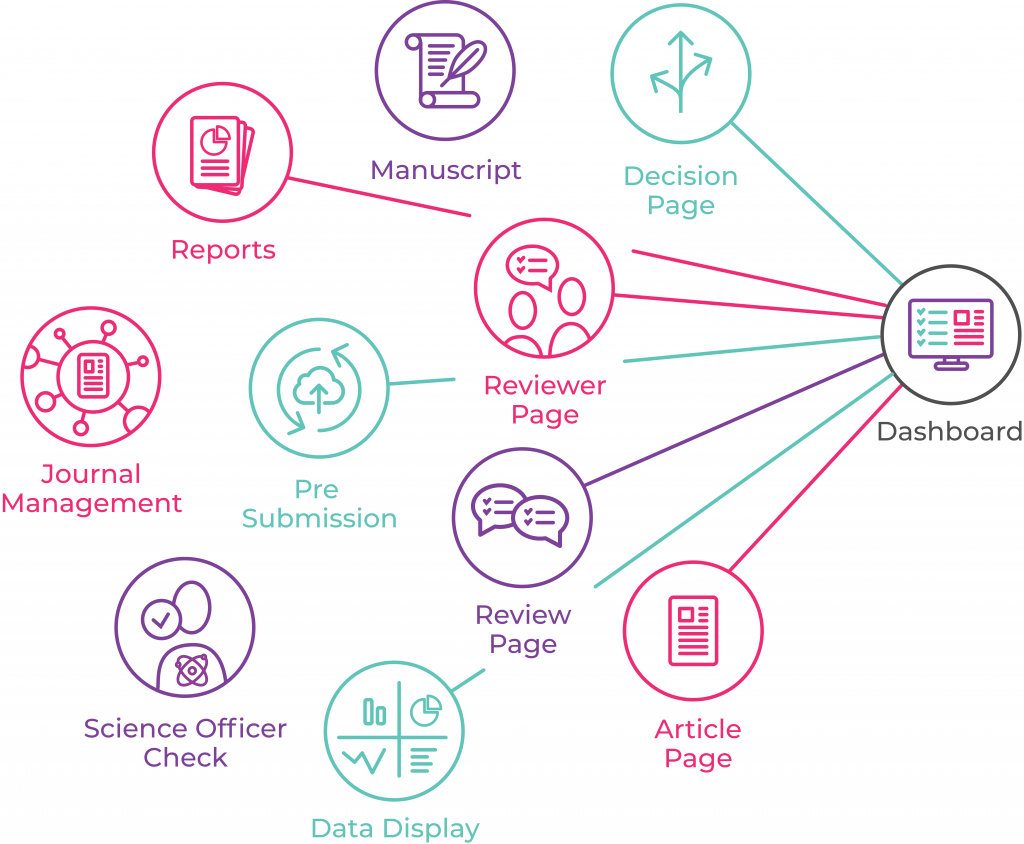
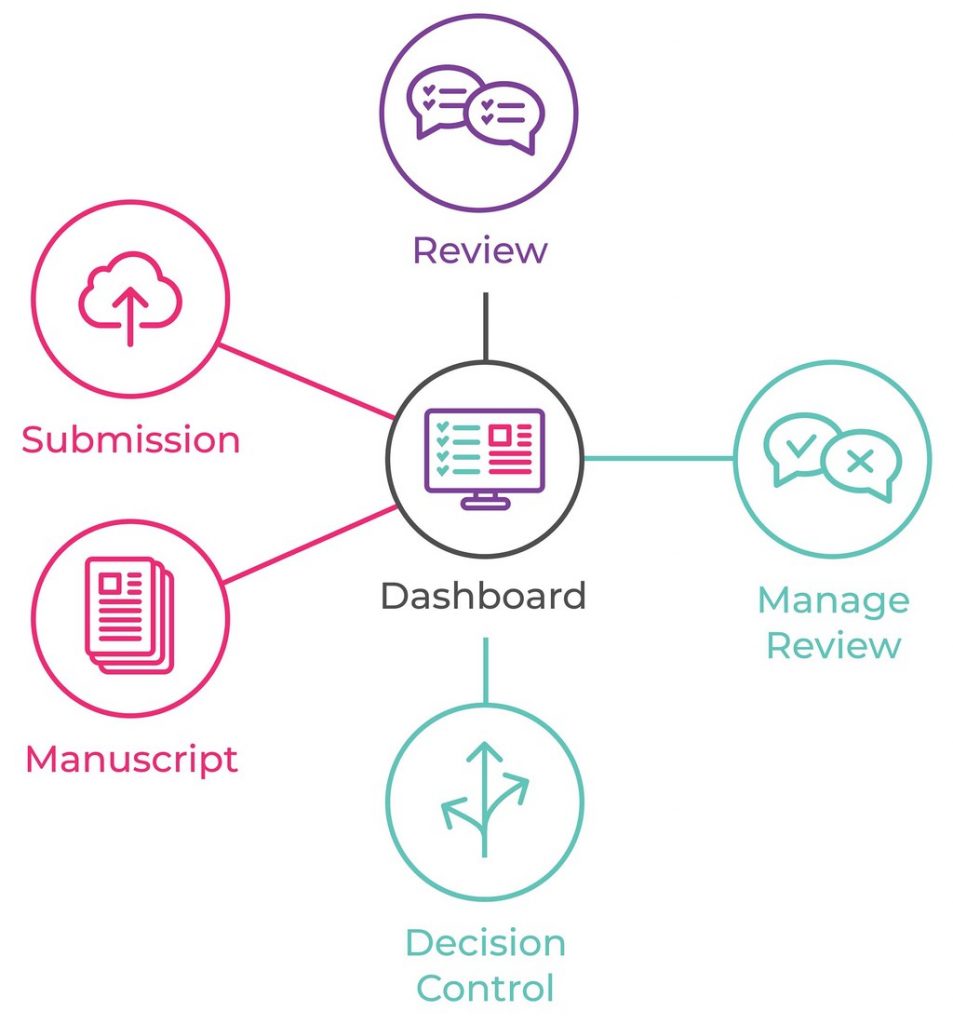
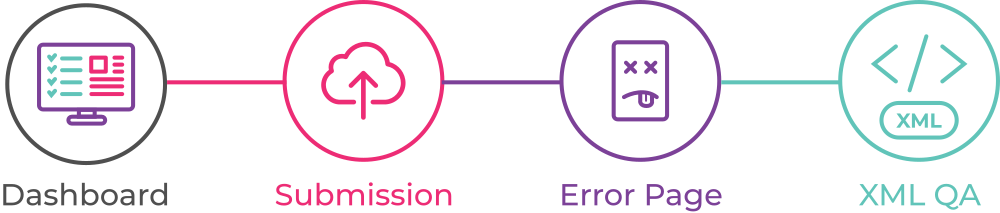
Proposals now closed. Below is the synopsis of each proposal, cut and pasted from GitLab. Titles link to the GitLab issue. I didn’t copy across any images, so where you see a reference to an image, please check the original item.
All items can be found in GitLab also of course:
https://gitlab.coko.foundation/editoria/editoria/issues
Create an account here: https://gitlab.coko.foundation/
Feature request: Please display tracked changes in different colors by user.
The request originates from UCP for Editoria, where only three users are expected to be within a given book/chapter editing at any given time.
Suggest retaining the tooltip, too, but adding this additional ‘at a glance’ feature to allow editors to quickly see who entered which tracked change within a longer book where checking each change by tool tip would become time consuming.
Org: Book Sprints
User story: As an author, I want to review a chapter while someone else is editing it.
To do this, I’d like to click on a read-only link for each chapter in the book builder. It doesn’t matter about the layout of the content, it just needs to be readable so that I can read it without having to render the entire book. No edit tools or comment tools are necessary, just a read-only version. As many people as needed should be able to click on the read-only view. Ideally, the read-only link should appear next to the edit button, and be permanently available (no permissions necessary).
Org: Book Sprints
User story : As an author, I want to be able to see the difference between parts and chapters at one glance.
To do that, it would be great to indent the chapters more so that the difference is more easily visible.
Org: Book Sprints
User story: As an author in a Book Sprint, I want the book builder to look as much as a table of content as possible. We do not upload word files in a Book Sprint, so we have no need for the blue buttons showing the upload status, therefore this UI element is unnecessary and distracting.
We would like to have the option to omit the blue buttons.
punctum books proposes an autocomplete feature when typing in names for book team roles (see attached image)
For example, when one of the possible users is Vincent it would be great if when I type Vinc it already suggests the rest of the name. Especially with large teams, this can be useful because you may not remember the exact spelling of each team member.
In the overview of Users under the Users menu include the different roles these users fulfill in the different Books
For example, under Username Vincent I would see Production Editor of followed by a list, Author of followed by a list, etc. This allows a quick review of which Users are involved in which Books.
punctum books proposes: an error message when you try to upload a file format that is not DOCX (such DOC) rather than XSweet trying to process it and then crashing.
punctum books proposes a toggle for invisible characters in the Wax editor.
This would allow quick discovery of double spaces, returns instead of enters, correctly inserting em/en spaces, weird tabs, and so on.
punctum books proposes: An additional Wax paragraph style “author.”
punctum books proposes that Wax automatically uses typographer’s quotes (for now, until there is proper language control).
When typing single or double quotes in Wax, they are not formatted as typographer’s quotes
punctum books proposes a feature that makes sure that the chapter name is always shown somewhere on the top of the page, so you know where you are.
punctum books proposes that usernames with underscores, periods, etc. are allowed.
Currently, it appears that no such usernames, such as “John_Doe” or “Paul.Smith” are allowed. When you try to create them, you get a 400 error without any further explanation.
punctum books proposes that new users are asked for first name and surname on signup.
Currently the only way to distinguish users is by username, and this becomes quickly problematic as the number of total collaborators on all book projects increases, especially if at some point users will start to make their own usernames which may not be directly comprehensible to Production Editors.
Registering first names and surnames allows for a better way of organizing users on the Users page.
Proposed by University of California Press
Adding sequential numbers to text styled as a numbered list would be helpful if one were authoring in Editoria. However, authors who want a list numbered submit it that way in .docx files, so the automatic numbering feature in this style adds a duplicate set of numbers to list items.
Proposed by University of California Press
To move to the next stage of testing and put a whole book through Editoria, we need styles for frontmatter components and a few more backmatter ones.
I’d like a separate section each for front- and backmatter styles in the vertical styling toolbar, with the former at the top and the latter at the bottom. There do not need to be too many styles in each of these lists, since the styles in the other sections (display, general text, lists) should be context-sensitive (e.g., for backmatter level-head, use Heading 1).
Because the front- and backmatter styles are rarely used in body components, it would be great if those style lists could be collapsed. They should still be available because there are instances where one might want one of those styles in a body component (e.g., in an edited volume, you might have bibliographical listings at the end of a chapter).
FRONTMATTER Here are the (most of the) styles we need that are not currently accounted for in the other lists (I am not including toc styles–that’s coming in another feature request):
Half Title Title Subtitle Author [if Barbara’s proposal of adding an author style is implemented, I assume it would be in Display, and we could just use that] Publisher
Series Title Series Editor Series List
Copyright Page
Dedication
Frontmatter Signature
For the rest of the elements in frontmatter, we could use styles in other sections (on output, the system would impose the frontmatter versions of these elements):
BEP Book Prose Epigraph —> Epigraph: Prose
BEPSN BEP Source Note —> Source Note
BEPO Book Poetry Epigraph —> Epigraph: Poetry
BEPOSN BEPO Source Note —> Source Note
FMH Frontmatter Head —> Title
FMAU Frontmatter Author —> Author
FM1 Frontmatter 1 Head —> Heading 1
FMTXT Frontmatter Text —> General Text
FIL Frontmatter Illustration List —> Numbered list
FAB Frontmatter Abbreviation List ---> Hoping we can add Abbreviations as a List style
BACKMATTER Here are the (most of the styles we need that are not currently accounted for in the other lists:
Bibliography Glossary Contributor list Index
For the rest of the elements in backmatter, we could use styles in other sections (on output, the system would impose the backmatter versions of these elements):
Appendix Number —> Number [assuming we add a number style to Display]
Appendix Title —> Title
Appendix Subtitle —> Subtitle
Backmatter Head —> Title
Backmatter 1 Head —> Heading 1
Backmatter 2 Head —> Heading 2
Backmatter 3 Head —> Heading 3
Backmatter Text —> General text
Backmatter Prose Extract —> Extract: Prose
Backmatter prose extract Source Note —> Source note
Backmatter poetry —> Extract: Poetry
Backmatter poetry Source Note —> Source note
BM Numbered List Extract —> List / Bulleted
BM Unnumbered List Extract —> List / Unnumbered
BM Bulleted List Extract —> List / bulleted
Chronology —> Hoping we can add Chronology as a List style
Backmatter Abbreviation List —> Hoping we can add Abbreviations as a List style
I realize there’s a lot here. Please let me know if clarification or rethinking is needed. Thanks!!
Proposed by the University of California Press
Although authors usually provide a toc with their manuscripts, we would like one to be generated from the book components. I do think a placeholder needs to be present in the book builder so it can be specified for pagination. It could say something like “Table of Contents will be generated on final output.”
For frontmatter, toc should include every component that follows the toc and use text with the style Title.
For body text, toc should list chapter number and text styled as Title, Subtitle, and (if there is one) Author.
For backmatter, toc should include every component and use text with the style Title.
When a book has backnotes (most of our titles), it is sometimes a little tricky to figure out where they go (they could be preceded in the backmatter by appendixes, abbreviation lists, etc.), so maybe the easiest thing to do is add a placeholder component to the backmatter with the heading Notes styled as Title and boilerplate language saying something like “Backnotes will be gathered here on final output.” That way, we could specify placement, pagination, and the title could pull into a generated toc.
Proposed by University of California Press
Authors often format display type in all caps. If the design specifies title case, we need to specify how letters are treated (e.g., articles and prepositions lowercased)–it is an editorial decision, not one that can be automated. Right now, the only option seems to be to retype text to remove cap formatting. It’s time-consuming and a chance for introducing errors. Word’s options are uppercase, lowercase, sentence case (first letter only capped), and title case (first letter of all words capped–gets you most of the way there).
Proposed by University of California Press
Display component names in Book Builder in roman, not italic, type (italic type really shouldn’t be used unless there is a reason). Allow italic type to be within the name. See, e.g., in UCP deployment Wickes / Bible and Poetry** chapter 1 title: Ephrem’s Madrashe on Faith in Context.
Proposed by University of California Press
The revealed spaces between words make longer sections of inserted text difficult to read. Could we have a toggle to show these or not?
This is a placeholder feature proposal. Right now, Editoria expects camera-ready artwork to be placed inline in order to become a part of the book. At the moment, a caption can be included with the inserted artwork, but no additional metadata about the image. This feature would allow a user to insert artwork from a media library. The media library would be similar to WordPress’s media library and allow for media to be uploaded and inserted inline in a book via the Wax editor, which would then become part of the media library, or to be added directly to the media library. The media library would allow for some basic media editing as well. It should be a “media” library rather than an image library because ultimately Editoria should be able to support multimedia in addition to static images.
This is a placeholder feature request for a CSS template gallery that would allow users to select from a gallery of page templates that can be rendered to PDF using Editoria’s CSS/javascript-based automated typesetting process. These templates would include the following variables:
- Page dimensions (translates to book trim size)
- Display and text fonts
- One or two-column designs
- Various other differences
This is a placeholder feature request for Editoria to validate EPUBs produced by the system using the open source Epubcheck validation tool to validate the EPUB output for adherence to the EPUB standard.
This is a placeholder feature request for a mechanism to add a book and/or chapter-level metadata data entry mechanism to Editoria. This could be achieved either by integration with an API or export-drive feed from a publisher’s existing title management system or by adding a form to Editoria that would allow for the entry of this metadata. In some cases, this metadata will need to be added to create a valid EPUB file, so an MVP could include just those metadata elements necessary to create a valid EPUB. This would also be useful for output and distribution to other systems (e.g. a publisher’s digital asset management system).
This is a placeholder feature proposal to develop tools for validating EPUB outputs against accessibility guidelines as codified by the W3C and other standards organizations. This could include anything from validating the inclusion of alt-text and alerting users to missing alt-text for images/media to validating whole book files against API-driven accessibility validation services such as those being developed by the DAISY consortium.
Longleaf Services proposes that component types be changeable. Currently, it’s possible to change the order of components within each type, but it is not possible to change the component type without deleting a file and reloading it. For example, Introductions are often moved from the main text into the front matter, and abbreviations lists are moved from front matter to the back matter. Being able to use the drag-and-drop function would be more efficient.
Longleaf Services proposes that author name(s), team member names and roles, author name, and current status be visible for each project, and that the page be sortable.
Currently only the title of a project is visible, and projects are listed alphabetically. Team members tend to think of projects by author, not title, so being able to see the author will be helpful. Being able to see the other team members for each project, and what stage the project is in, will help in managing the work. Finally, as the number of projects increases, it’ll be useful to be able to sort out those that are complete from those still in progress. Being able to sort on other attributes, such as series or imprint for example, will also be helpful.
In the interest of conserving space, a user could click on the project title and the list of team members could appear, as it does when one clicks on “Team Manager” on the individual page for each project.
Longleaf Services proposes the caption text box be enlarged. Currently only a limited amount of the caption text is visible; a larger text box would make reviewing/editing the text easier. If there is a total character count limit, it would be helpful to provide the number of characters remaining.
Additionally, perhaps we could encourage accessibility/alt-friendly caption or descriptive entry? Maybe above the text box there could be a suggestion such as, “Consider providing a caption that is accessibility/alt-text friendly.”
punctum books proposed the option to export only parts of a book.
Currently, only an entire book can be exported through paged.js. It would be great if you could select on or more chapters for export, which again would be very useful for edited collections.
punctum books proposes an additional special character: a discretionary hyphen.
Foreign names such as Nietzsche are often broken off erroneously by automatic hyphenation, for example Niet-zsche. A discretionary hyphen is an invisible character that shows paged.js where to properly hyphenate a word or name.
punctum books proposes inline semantic markup in Wax.
Currently, there is an asymmetry between paragraph styles, which have semantic values (Title, etc.), and character styles, which have typographical values (italic). Especially with an eye on future export to InDesign formats, it’s important that italics for emphasis and italics for book title, for example, are separated.
At the same time, authors are usually not familiar with this type markup and it might cause confusion. I’m not entirely sure how to solve this practicality.
punctum proposes a language control feature.
I guess this is a big one, and not an enormous priority for us, but something that needs to exist in the future because we often work with multilingual books. There needs to be a way to signal that an entire chapter of part of a chapter is written in a certain language in order to properly control hyphenation (upon export) and interpunction, such as the type of quote marks (curly, fishhook), non-breaking spaces before colons/semicolons (in French etc.), writing direction (Arabic/Hebrew), etc.
punctum books proposes a features that allows you to “tag what you want” in Wax.
This proposal is in line with (and expansion of) our proposal on inline semantic markup. The current number of standard paragraph and character styles is limited, and should remain so. However, there are frequently books that require custom definitions.
I suggest that in Wax you can add a new paragraph or character style by means of (+) button, prompting you to give the style a name (New Fancy Style), from which a slug is generated (new_fancy_style) that you can then define in CSS, and a simple display format in Wax (italic, bold, indent, etc.). The display format doesn’t have even to be matching or fancy, as long you can then control the tagged words/paragraphs in CSS.
This is a proposal for an indexing tool, written from the perspective of an indexer, not a production editor. It would be great to have some feedback from the production side. I do not know what happens to an index after it is submitted to a press.
Ideally, Editoria should accommodate, or improve on, the two most common professional back of the book indexing methods:
- Writing and editing an index using the final page proofs. This method has multiple approaches, which includes a) marking the page proofs, then entering the headings and page numbers into an editor, and b) displaying the page proofs on a monitor, and entering the headings and page numbers directly into the indexing software/editor, which simplifies many aspects of the editing process and automates all of the formatting specifications, which can vary by publisher and or text.
- Embedded indexing, where an indexer can create an interactive/XML index by marking up/tagging the text during the production process for exporting with the final page proofs. While I’m not as familiar with embedded indexing, I am aware that there is a general sentiment among indexers that they do not produce the quality well-structured analyzed indexes desired for scholarly monographs. However, publishers cite benefits to the workflow. For example, first page proofs will be of the entire book, including a fully set index in page form; overall schedule time should be shorter; they have a fully usable index in whatever form the content is published in, now and in the future. Few indexers are trained in this method. If Editoria could simplify (GUI interface required) the process of compiling and editing a quality index during the production process, rather than as the final task before the book goes to press, it would be adopted widely. I’ve discovered a new commercial effort that claims to do this, but I haven’t used or seen it demonstrated, Index Manager.
METHOD 1, TRADITIONAL INDEXES Most indexes are created by professional freelance indexers (using one of the three highly sophisticated indexing software programs, Sky, Cindex and Macrex), who are hired by the authors. Freelancers may submit the final index file to the author or the production editor. Indexes are generally submitted to the press/author as a double-spaced single column file, with the requisite detailed formatting Feature_proposal-indexing_tool.docxSample_Index.RTF requirements. I do not know what production editors do with the index once it is received from the indexer, or how that process could be simplified for them.
- Editoria should allow for an indexer to write and edit an index within Editoria using the final page proofs AND allow an indexer, or team manager, to submit into Editoria an RTF file of an index generated from the final page proofs
METHOD 2, EMBEDDED/XML INDEXES Any automated XML indexing tool should be able to handle these very basic and common indexing practices:
- To create multiple index styles automatically – indented and run-on (examples can be supplied if necessary).
- To create main headings and subheadings, including words and phrases that do not appear in the text.
- To alphabetize all headings and subheadings and choose between letter-by-letter and word-by-word alphabetizing order.
- To designate stop/ignored words in alphabetizing.
- To create and auto-format cross reference style and placement, See and See also.
- To indicate how page ranges should be handled (e.g., simple, aggressive, aggressive 2, Chicago, Chicago 2; examples of effects can be supplied if necessary).
- To indicate the character to use between page numbers, hyphen or en dash.
- Punctuation placement (commas, semicolons, colons) should be automated.
- To indicate how many columns the index will be.
- To generate an introductory note to describe special features of the index.
As mentioned above these are basic practices. Fine tuning some of the more complex aspects of constructing and editing an index would be an ongoing effort. They concern what occurs after completing the rough index, when an indexer edits it for structure, clarity and consistency, formats it to specifications, and proofreads it. Anything to simplify the XML-index editing and output process in Editoria would be an improvement over the current complex and time-consuming options that indexers currently have for XML-indexing that is not compatible with their indexing software programs.
I’ve attached a Word file of the proposal and a sample index, submitted to Cambridge.
Longleaf Services proposes a function that allows team members to be notified when the status of a project changes—For example, “File _____ is available for editing”
I’d think an email alert would be best, as it doesn’t require the person to be logged into Editoria to see the notification: An author, for example, wouldn’t necessarily bother logging in unless they knew the file was ready for them.
If feasible, development-wise, it would be useful to let the Production Editor decide who (that is, which team member) should get the notifications for a project. There are instances in which one user (generally the PE) performs multiple functions, such as also being the copyeditor, and wouldn’t want/need the notification that a file is ready to edit.
Attaching our sketch and some notes from the community meeting:
Completed / abandoned books need a long-term archiving solution, and users probably won’t want these titles cluttering up their Books Dashboard, so we propose a new ‘archive’ option on the Books Dashboard that would spawn a modal with options for where to send the archive and what to do with the dashboard entry. These options could be configured by an admin to connect to various preservation solutions (e.g. LOCKSS, Portico, FTP).
There was also some debate regarding whether this functionality made more sense at the Book Dashboard level, or at the final export step; though export is something that – at least while it’s functioning as a preview, which it is now – is used repeatedly, while archiving likely happens once.
… of course there might be cases where an archived book comes back to life, so there would need to be a way to enabled that, and / or perhaps a clone / fork feature (e.g. for a future edition).
Longleaf Services proposes that the option to print be available.
Our pilot project requires that a print version of the final file be available to participating authors/presses to satisfy tenure committees, reviewers, and awards committees that don’t yet accept digital versions. Would it be possible to provide the option to download a project’s pdf version, next to the option to download the epub?