So, there are a lot of product names at Coko – PubSweet, Editoria, XSweet, INK, xPub etc etc etc… so becoming tricky to track, but I wanted it seems there are quite a few people interested in xPub right now.
xPub is not really a product as such, it’s more a group of products – each of which relates to Journal workflows. The names for each product indicyae those relationships: xpub-collabra, xpub-elife, xpub-faraday (Hindawi) and xpub-epmc
Each of these is a platform, so yip, you read it right – there are actually no less than 4 journal platforms being developed in the Coko community, not including the Micropublications platforms (of which there are two – one developed with Wormbase, and the other with the Organisation for Human Brain Mapping).
So, right from the get go our ‘offer’ is not standard. We don’t offer one platform to rule them all – there are many journal platforms in production. All of these are built on top of PubSweet… PubSweet is a kind of ‘headless’ publishing platform….it’s more or less the backend brains in that it is a kind of framework that ‘thinks like a publishing system’ but has not determined a workflow for you. So, each of the xpub-* platforms are actually publishing platforms built to meet a specific workflow and built on top of PubSweet…
Here is a crappy diagram (drawn in haste) to get the basic idea across:
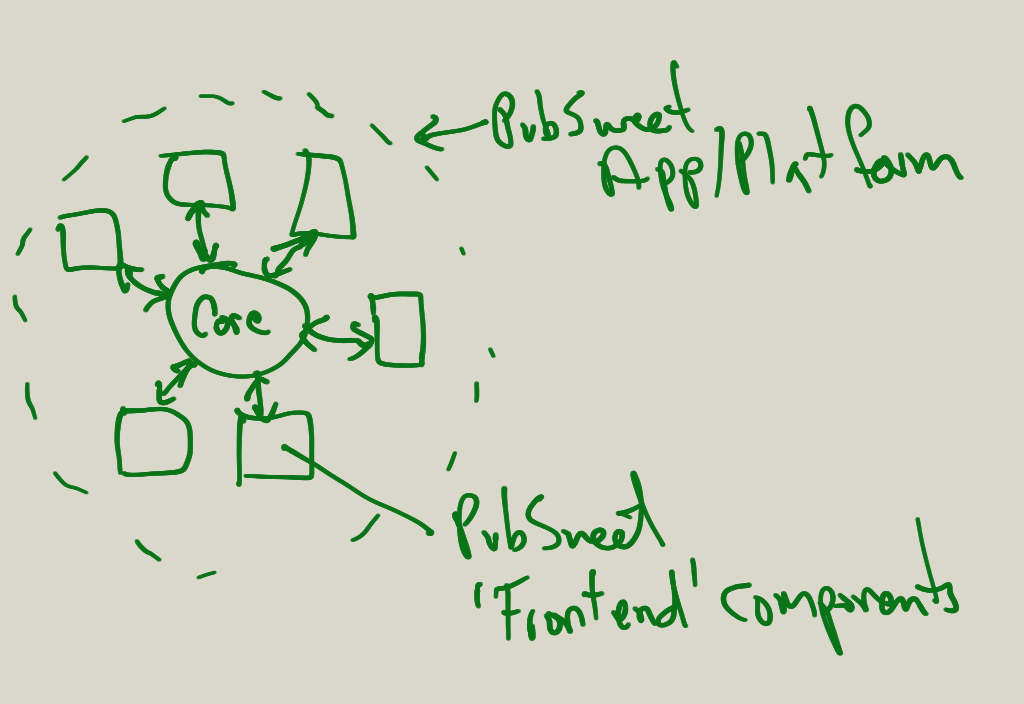
In the above, you see a PubSweet platform (eg. xpub-elife). PubSweet itself is the whole app – it sort of ‘encapsulates’ everything. Really though, you get the PubSweet core and then extend it with front-end components to meet your workflow needs. A typical front-end component might be a login screen, or a dash, a submission info page, a reviewer form etc.
You can also extend PubSweet on the back end as well (eg to enable integration with external services etc). The following is a more accurate but slightly techy architectural overview (you can skip this image and the following paragraph if you want to avoid the slightly techie part of this article).
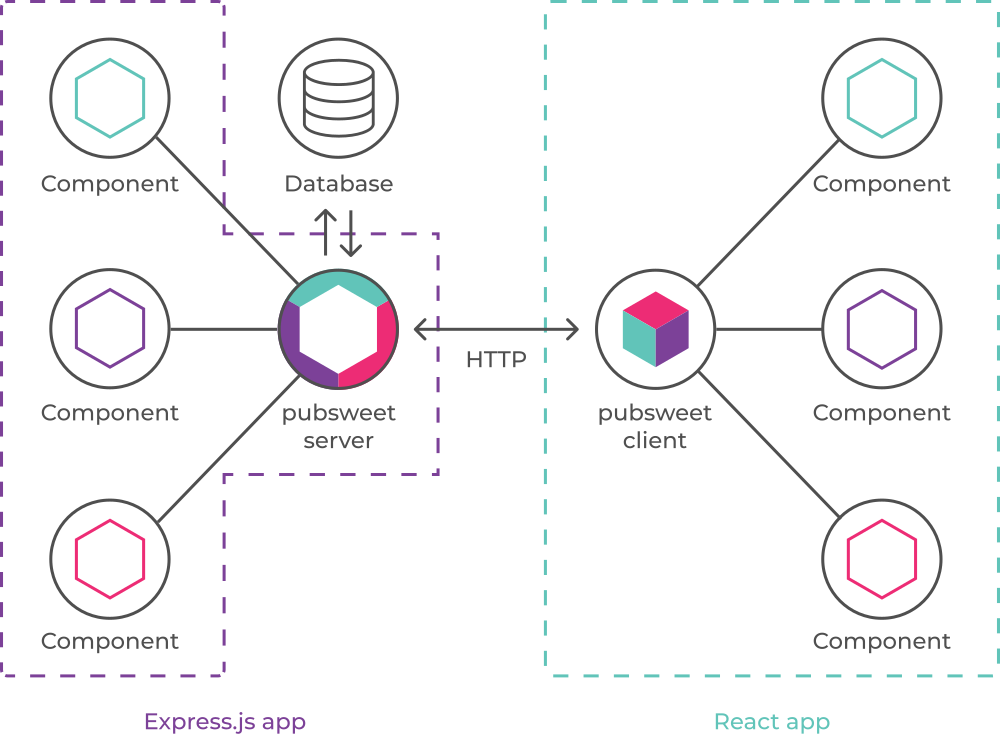
In case you are wondering – everything is written in Javascript. Why did we choose JS? It was a deliberate choice to go with a language that was prolific. Almost every dev around these days needs to know some Javascript (it’s the most popular language by far on Github), this makes finding a developer to work on your project is as easy as we could possibly make it. JS is also a phenomenal language these days. Fast, sophisticated and more than capable of supporting large-scale publishing requirements. I mean, if it’s good enough for Paypal, Netflix, Linkedin, Uber and ebay, then it is good enough for you.
So each PubSweet platform has its own collection of front and back end components to meet the workflow of someone’s dreams… the idea is that to achieve the platform of your dreams you can reuse what others have already built and then just build what isn’t already available. In a sense, you can ‘assemble’ your platform from existing parts.
The nice thing about this is that each of the organisations building Journal platforms are sharing the following:
- the same back end/framework (PubSweet)
- various front (and back) end components
- lessons learned…
Each organisation has a vision of their ideal Journal workflow. They then design and build this on top of PubSweet, but as they do, they build various components (either page-based components such as a dashboard, or smaller UI components we call atoms and molecules) and they share these components with everyone. Hence, you should check the list of components before you start building in case the component you need already exists.
We have various agreed-upon ways to build and share components (see this as an example). These best practices are continuously evolving but you can read some of the latest discussions about this approach here – https://gitlab.coko.foundation/pubsweet/pubsweet/issues/408
Of course, all code is reusable in the Coko community because it’s all open source. The best practices are there to make the code easy to reuse.
All agreements as per above are made by consensus by the community. It is actually a pretty snappy process – don’t believe every crappy thing you read about how open source is built. Open source community processes can be elegant and fast, and the resulting code can beautiful. Coko is a good example of this – a community of professionals collaborating together to make fantastic open source software.

So… back to the xPub story. To make these decisions on how to share components etc, we have regular meetings with various workgroups (we keep the numbers in each group small so we can move fast), and we also have quite a few in-person meetings. Not only do we have PubSweet community meetings where all of these organisations meet, but we have various get-togethers on various topics if required. For example, we met in Cambridge recently to discuss Libero (the eLife delivery product), before that EBI there was an onboarding session in Athens, next month we have a special designers workgroup in-person meet, anbd so on. All this helps us keep in contact with each other, which helps build trust, but also turns out to lift energy levels and boost production. These meetings are fun.

Also at these meetings, we learn from each other. One of the big problems in this sector, and one of the reasons people ask ‘why are publishing platforms so hard to build?‘ (after a number of high profile failures), is that there has not been a focused effort to share experiences on how to build publishing platforms. So, that is what we are doing – at each meeting we talk about what we have learned, how we are thinking about things, and show each other what we have done. The last meeting, for example, each xPub platform gave a deep dive to everyone in the group in a process known as speed geeking (it wasn’t so speedy as each table had 25-30 mins to go through their platform).


So, xPub isn’t a single platform, it’s more the community that is building journal platforms on top of PubSweet and sharing learnings and components. It is a very cool thing.
As a community, we also produced a book entitled ‘PubSweet – how to build a publishing platform’. You can get this for free here – https://coko.foundation/books/
I can also send you a print copy (they look great!) if you send me a postal address.

The book covers many things – a whole lot of technical documentation for how to build and share components etc, as well as some information about to think about workflow and how to map this into a PubSweet system. Personally, I don’t think the technology is very hard when it comes to building platforms – we knew what we wanted from the beginning with PubSweet and went about and built it (not to downplay the extraordinary job Jure Triglav has done in leading this effort). But the real hard stuff is actually thinking about workflow – not many publishing orgs have had the opportunity to think about designing their workflow to meet exactly what they want (rather than shoe-horning it into an existing system), and so we have had to beat this track for other to follow. It has been quite a journey but the book pretty effectively outlines how to think about workflow (which of course is a process that can be accelerated using Workflow Sprints which is a process I designed to facilitate a publisher to design their own workflow and PubSweet platform in one day).

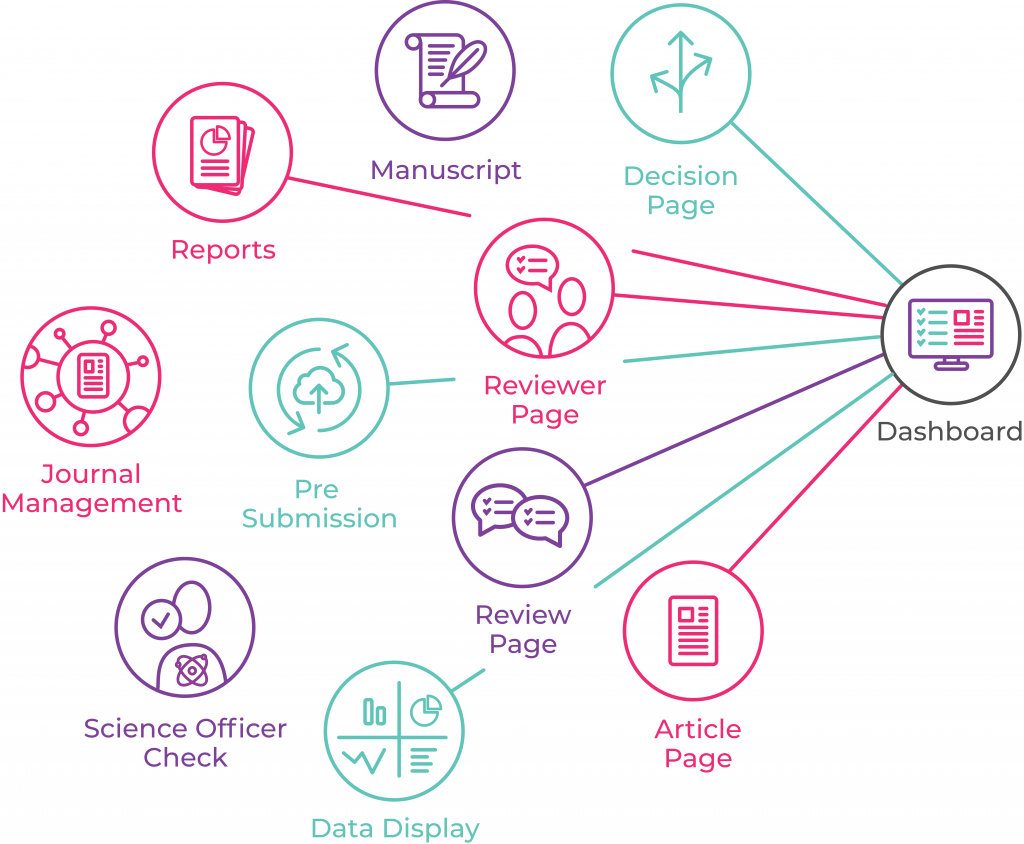
In that book you can see some high level ‘architectures’ of each of the xPub platforms such as the following (xpub-collabora):
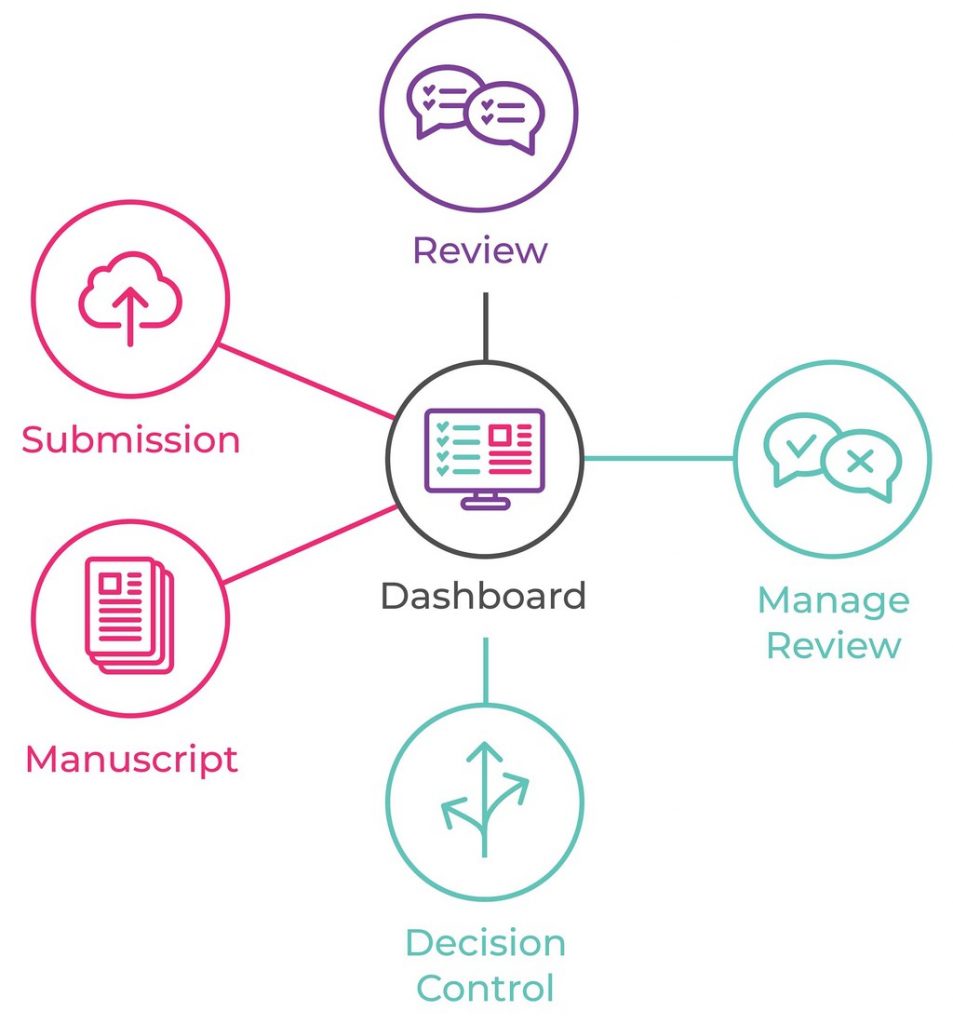
Or this (xpub-epmc):
So, you might be asking…. at what stage of development are each of these platforms? … I’ll leave it to each of the teams to say exactly, but it has been shocking to see how fast things have come along. I mean, the xPub community only really got together for the first time mid-last year, and building started for most late last year and early this year. It looks like we will have a lot of platforms landing by the end of this year. In this sector that is lightning fast. EBI are particularly impressive – they started two months ago and are almost ready to go – if it weren’t for the fact we are all replacing the under-the-hood data model we designed together at the last PubSweet meet, they would be good to go already. They can achieve such speed because they are reusing a lot of the components that the other teams built before them (and because EBI are just very good 🙂 ).
I can speak a little more about xpub-collabra since that is the platform Coko is building for and with the Collabra Psychology Journal. It’s looking pretty nice. We have some work tidying up the UI, replacing the data model and a few other things, but it’s looking rather good. We are also putting some time into making it a generic platform since the Collabra workflow follows a fairly ‘plain vanilla’ model. So we are building in some management interfaces and various bits and pieces to make it more widely useful – for example, Giannis just built in a Submission Info builder – enabling a Journal admin to build their own submission forms. It requires some hand-holding to use right now, but we’ll shape it to be very usable by your general journal adminy-type. We also have to integrate ORCID and DOIs, extend the range of submission file types etc… but it’s pretty close.
Below is a video showing xpub-collabra in action. It is a a version from some months ago, but you can see the workflow pretty well in this demo.
I think most of the xpub community is going to offer their new platforms to the market in various ways. This will be interesting as there are very different approaches at play. Hindawi, for example, is looking to make their platform a multi-tenant platform, eLife will put JATS at the centre of the workflow etc… So look for more news on that also. For our part, Coko will offer xPub through a partnership with a hosting provider – probably with the same organisations we will work with for Editoria hosting services. Since everything we do is open source, we will also be supplying all the Docker, Helm and Kubernetes scripts so that you can set up your own commercial hosting service if that is your cup of tea (or you can extend your offering should you already be a hosting provider). Coko is pretty close to getting our first hosting partnership set up, so look for news of that soon!
One last thing – because of the modular nature of any platform built on top of PubSweet, it is possible to take any of the xPub platforms and customise it to meet your needs. No need to start building from zero. Additionally, the modularity means you can extend the systems with your own interesting new innovation – finally a place for innovation to call home in the publishing platform world….
So… there is a lot going on in the xPub world….we look quite different to the rest of the market because we are not building one platform – we have instead focused on building a community to support the development of multiple platform solutions for journal workflows. You can pick and choose which one you want, or build something else, reusing as much of the other systems as you can to reduce your development costs (we also spend a lot of time onboarding new folks and supporting them as much as we can).
But it’s not just about improving the game today – supporting the optimisation of workflows is one part of what we are trying to do, the other is to support future innovations.
If you want to know more, feel free to jump into the Coko community channel and chat – https://mattermost.coko.foundation
Come and join the party. We are happy to support you and happy to learn from you…. not-for-profit or commercial we don’t care, build a better journal platform on PubSweet than the rest of us and we’d be happy! We are in it for the mission – come to talk to us! no preciousness here 🙂

