We are pretty close to our PubSweet 1.0 with the RFC now out for PubSweet 2.0, and a PubSweet dev site release next week.

It has been an amazing effort, particularly by Jure Triglav, the lead dev for PubSweet at Coko, but also fantastic work from Richard Smith-Unna, Alf Eaton, Yannis Barlas, and Christos Kokosias. Also more recently some great contribution from Alex Georgantas.

So, we are pretty much there and I’m presenting in San Francisco this week as part of a small Coko event to reflect on the future of the framework and discuss the RFC. For this purpose I’d thought I’d write a post to help me think through the thinking that got us here.
So…the thinking behind PubSweet started when I came back from Antarctica around 2007 or so (I was there setting up an autonomous base for artist-scientist collaborations).

I decided I wanted to give up the art world and try something new. The something new turned out to be FLOSS Manuals – a community writing free manuals about free software. I started it when I was living in Amsterdam somewhere around 2007. In order to execute on this mission I needed to get a couple of things sorted. Namely, learn how to build community, work out processes for rapid book production, and work out the tooling.
The tooling started with me scratching around with TWiki. A wiki written in Perl that happened to have the best plugins for rendering PDF. I scratched around, writing some Perl and cutting and pasting a whole lot more, and added some crazy .htaccess URL rewriting to produce a basic system for producing books. It was pretty scratchy but it actually worked. Later a buddy helped extend the system and later still I was able to pay him and others to extend it.
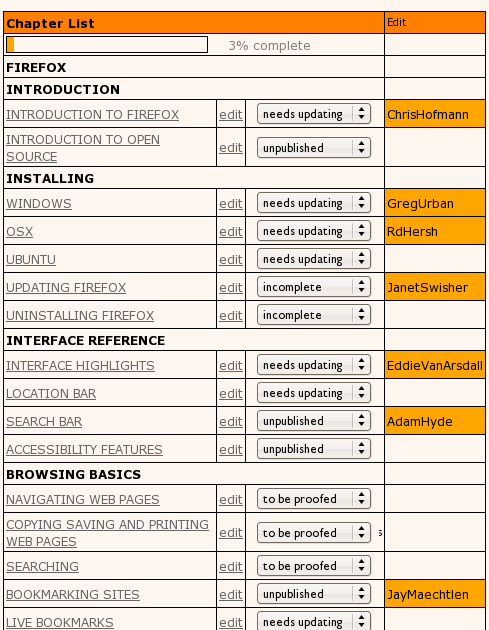
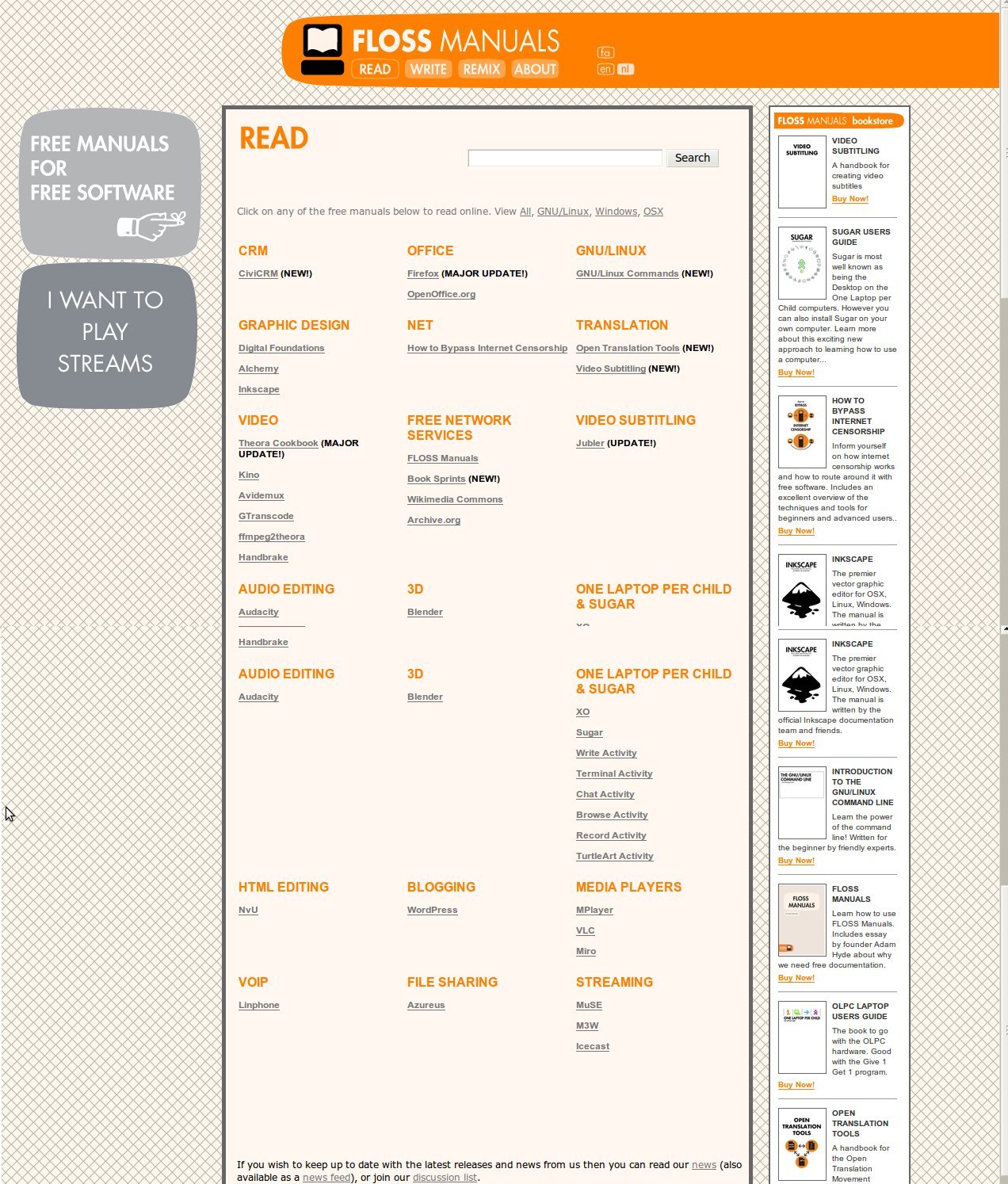
At the time it pretty much comprised a page (per book) for creating a table of contents.
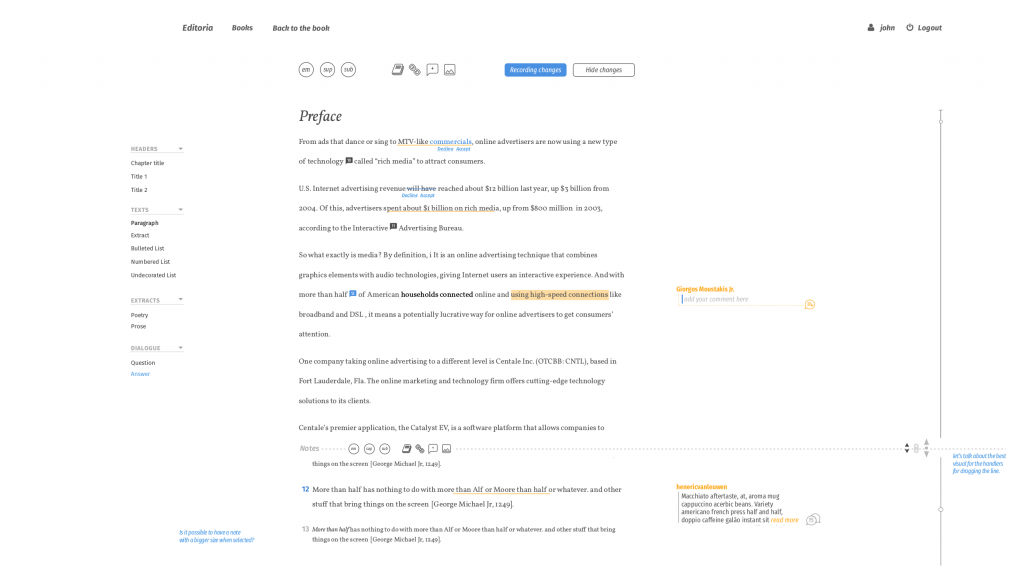
and an interface to edit the content (chapters). I ripped out the native wiki markup editor and replaced it with a WYSIWYG editor, I think it was TinyMCE…
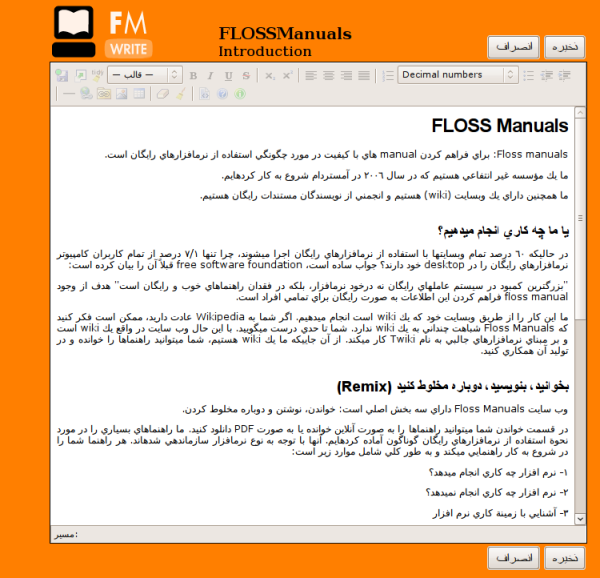
As you can see Right-to-Left content (in this case, Farsi) was also supported. There were also some basic things in place for keeping track of the status of a chapter, the version number, side by side diffs, side by side translation interfaces, and, later, dynamic table of contents organisation and edit locks.
Coupled with some basic PDF rendering stuff and a way to push the content from the ‘draft’ to the publishing front end and we were away.
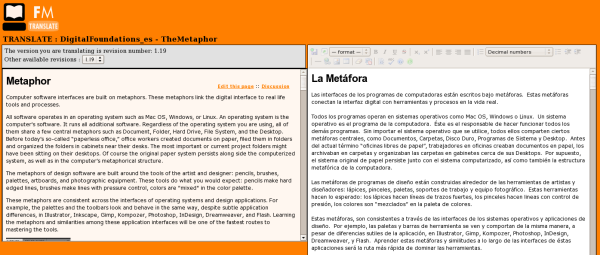
It actually had some other pretty cool stuff, such as side by side translation interfaces…
Remix…
..a built in live chat for talking with collaborators…
and even a way to send books between different instances (eg for sending a book from the FLOSS Manuals French community site to FLOSS Manuals Finnish for translation)….

We could even render book formatted PDF and push to the lulu.com print on demand services. I just now checked and some of the books are still there!
Not bad for a Perl-based system, built on top of a wiki that wasn’t supposed to do this kind of thing, and built very with very few resources. The TWiki extensions were contributed back upstream to the TWiki repo and it was all open source but it was pretty hard to rebuild and no one I knew actually had a similar use case.
After this, I embarked on a journey to replace the system with a custom built solution specifically for book production. I can’t remember exactly when this started, maybe 2008 or 2009 or something. It was originally called Booki…
…which later became Booktype. Booki (and later Booktype) replaced the FLOSS Manuals tooling, although you can still see the working old tool here. That ole Perl code is still functional with no maintenance after 10 years, I can hardly believe it. The docs on how to use it also still exist.
Booki was built with Django (python) and pretty much had all the same stuff. Although the look and feel was changed quite a bit in the transition. There aren’t too many images around of Booki although I did find these screenshots of Booki taken by someone using it on the OLPC XO! (FLOSS Manuals did all the docs for OLPC/Sugar OS etc).
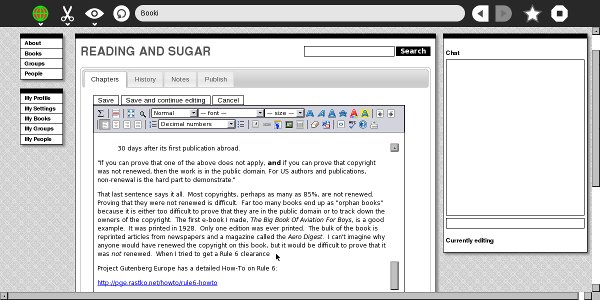
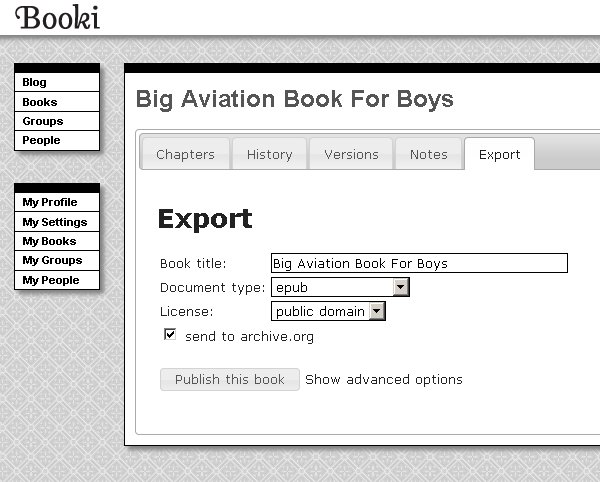
It was hard to get financial support for it. Internet Archive gave us $25,000 at the time which seemed like a fortune. The evolution of Booki to Booktype represented me taking the project to a buddy’s in Berlin (I was living there at the time) based org (Sourcefabric) and parking it there so I could get more resources to build it out.
Booki/Booktype pretty much had, and has, the same stuff as the FLOSS Manuals system, just purpose built. So it had, a table of contents manager
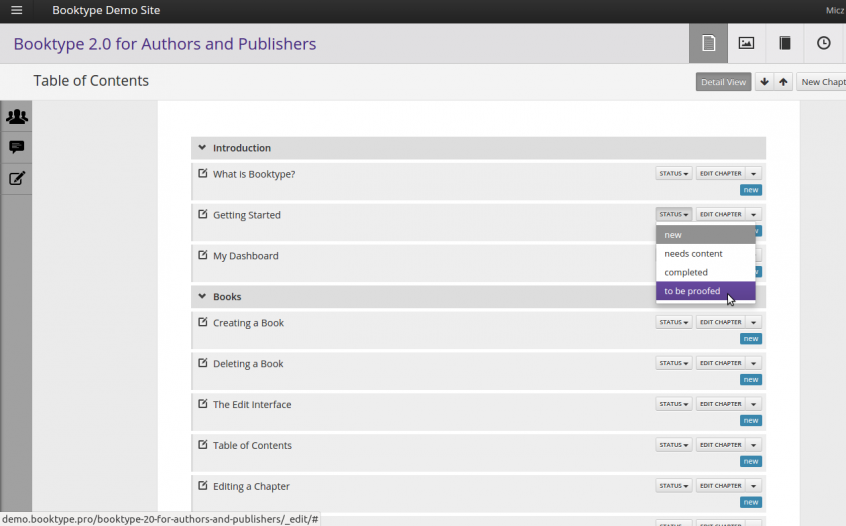
And a book (chapter) editor…
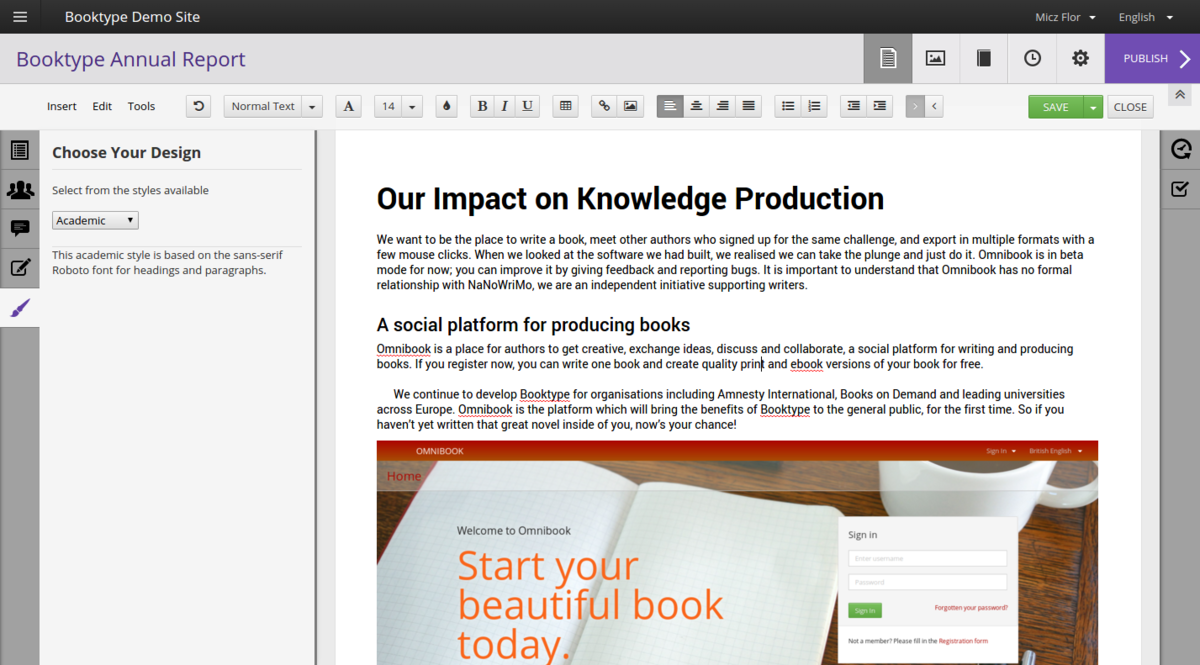
…chat…
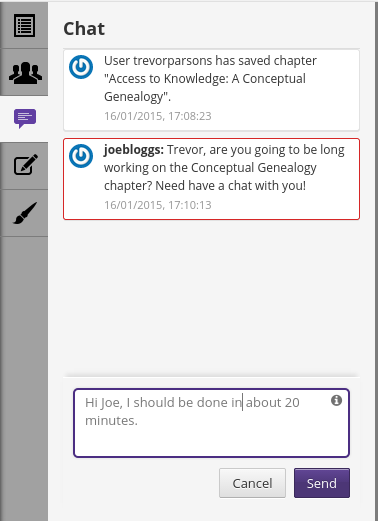
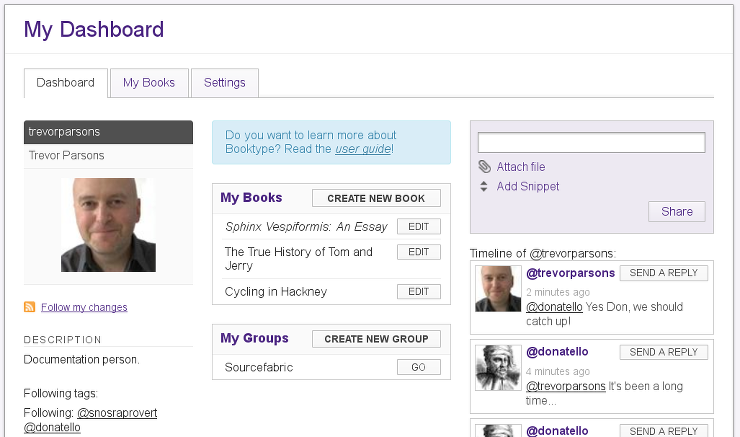
And the other stuff. Perhaps the only new features (compared to the FLOSS Manuals system) were a dashboard…
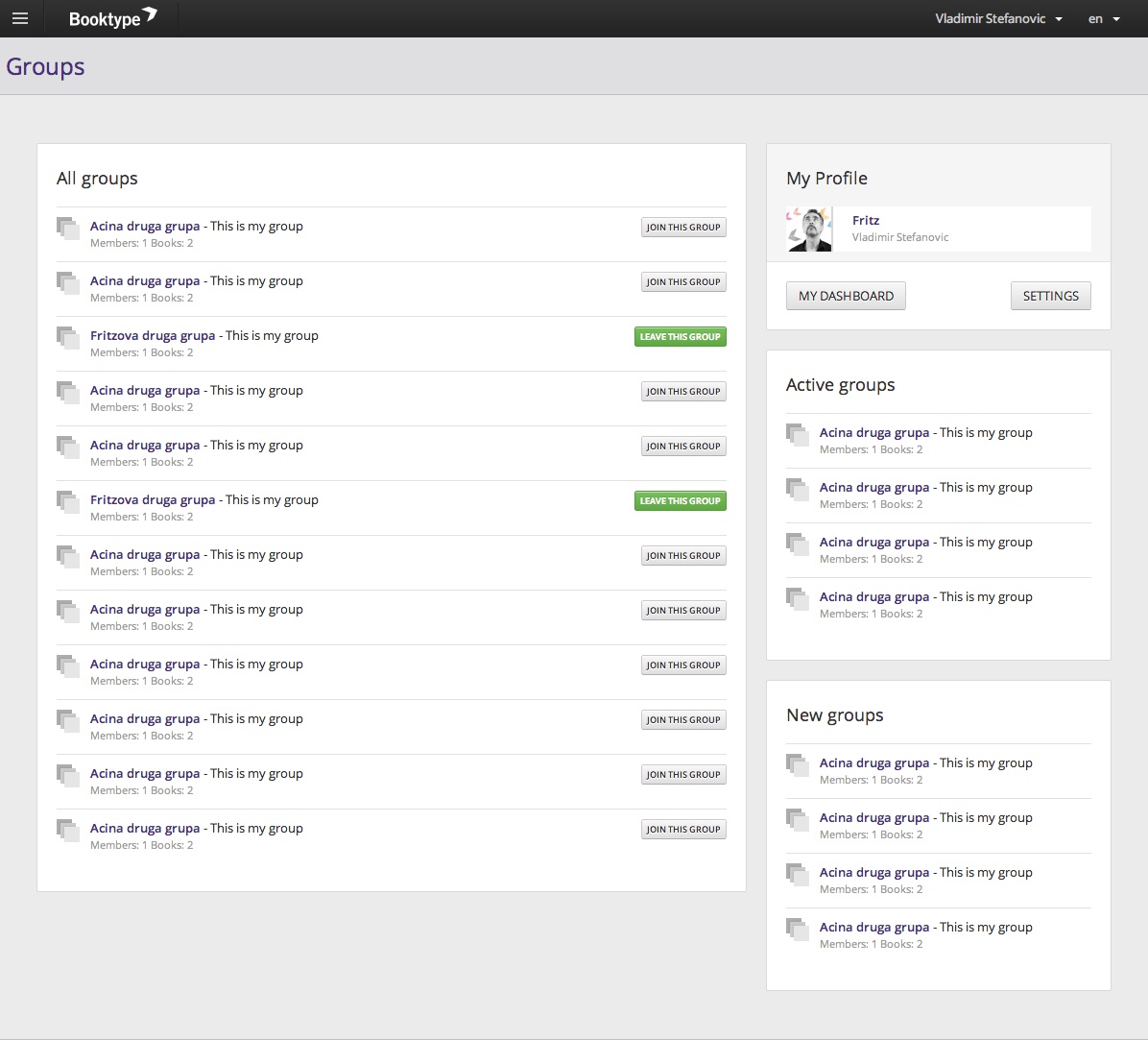
…groups…
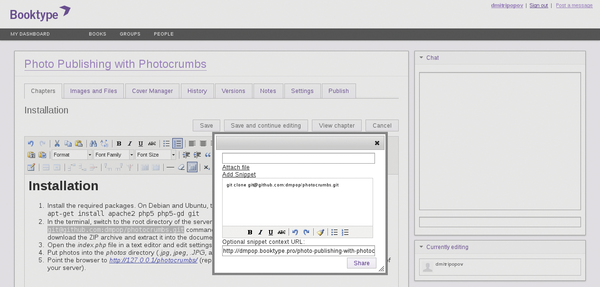
and an interesting way to have Twitter-like messaging to pass snippets from chapters to other users.
Before I left Sourcefabric I wanted to get some other innovations built but didn’t get there. I did build some prototypes though. There was a task editor…
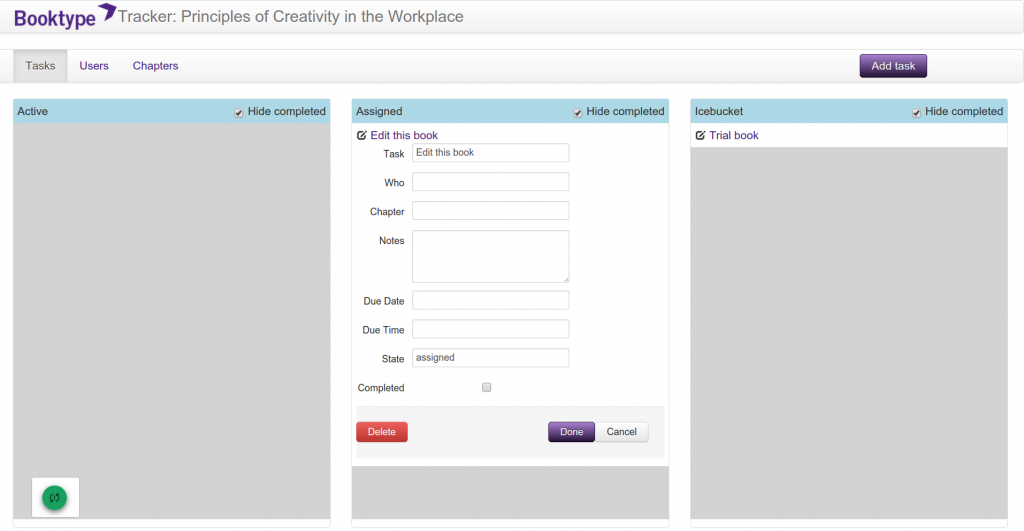
…and live in-browser book design…
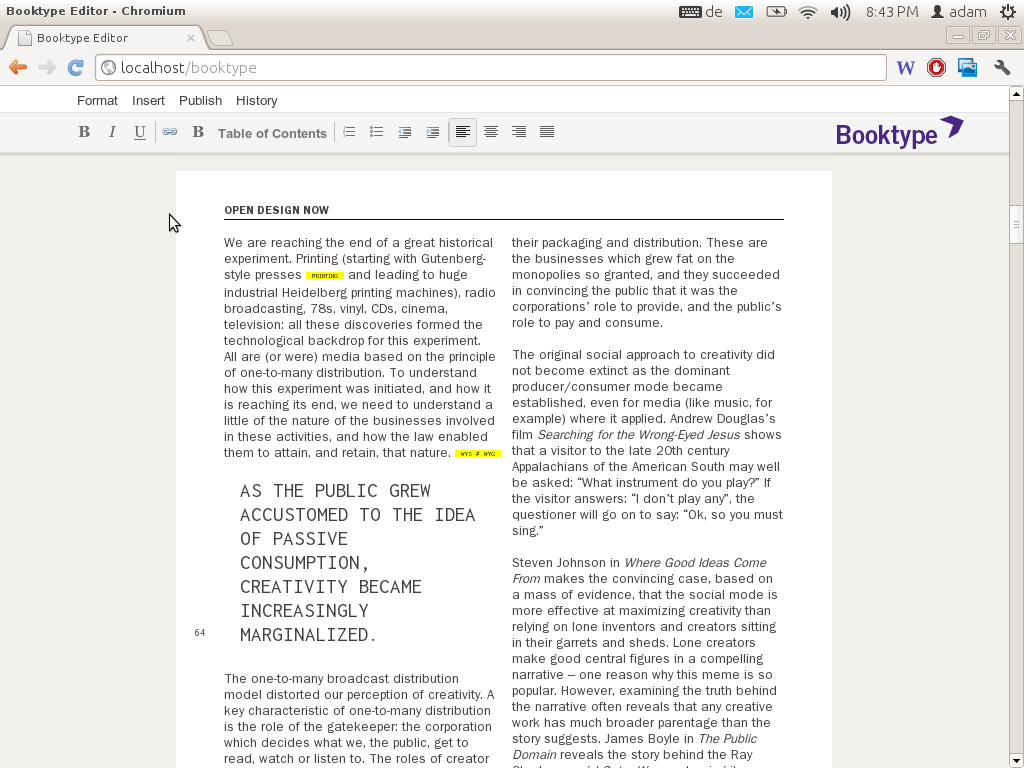
Booktype is still going strong, now it is its own company (based in Berlin) and they also run the Omnibook commercial service using the software.
I left because John Chodacki and Kristen Ratan from PLoS invited me to come work for PLoS to design a new web-based journal submission system. I agreed…
But, before I leave the book story behind for a bit..I had set up Book Sprints as a company and put a small amount of my own money into building two new book production systems somewhere between leaving Sourcefabric and starting at PLoS. These two systems were PHP-based and Juan Gutierrez built them over some months.

I wanted to do this because I was a little frustrated by Booktype not moving forward and also the platform was becoming more difficult to use. We were using it for Book Sprints but after I left the product took a new UI direction and I was finding Book Sprints participants were not enjoying using the system. So I built a Book Sprints specific system called… PubSweet… the namesake of the current Coko system which has eventually turned into something of a prototype for the new PubSweet… this new system was a lot simpler and easier to use than Booktype. It was initially meant to be modular but I think we lost that somewhere along the way. Cleanly modular systems take a lot of extra effort and time to produce so we gave in for speed of development’s sake.
The old PubSweet had a dashboard….
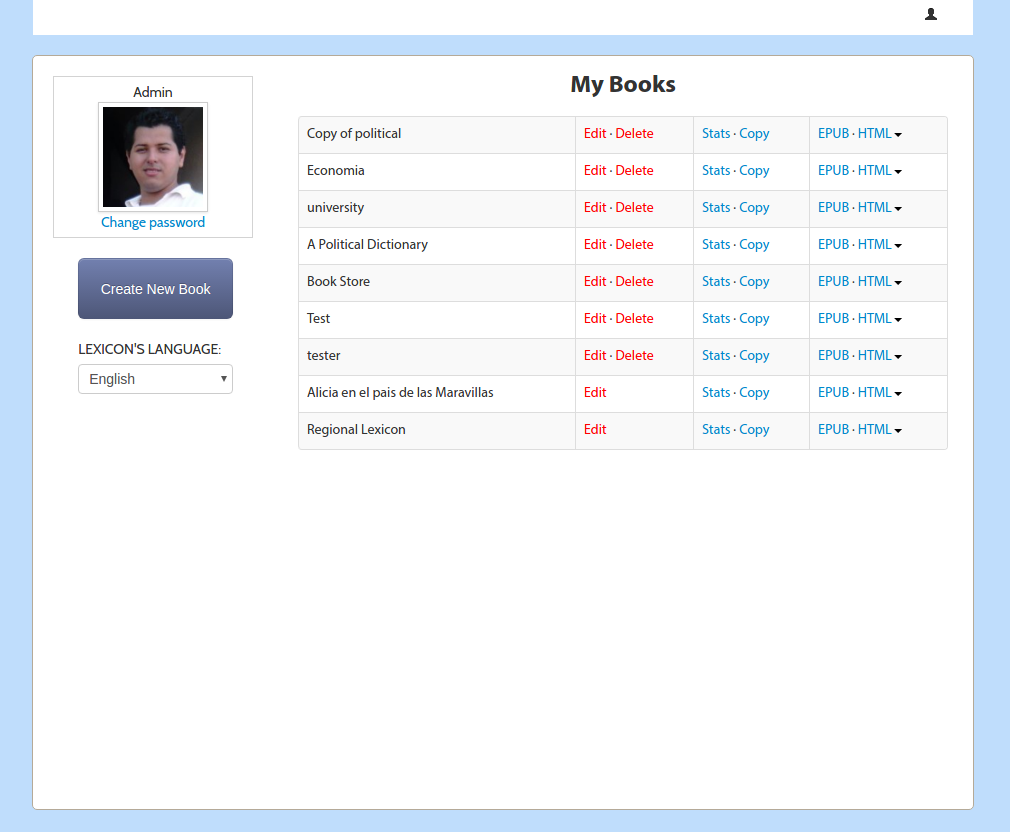
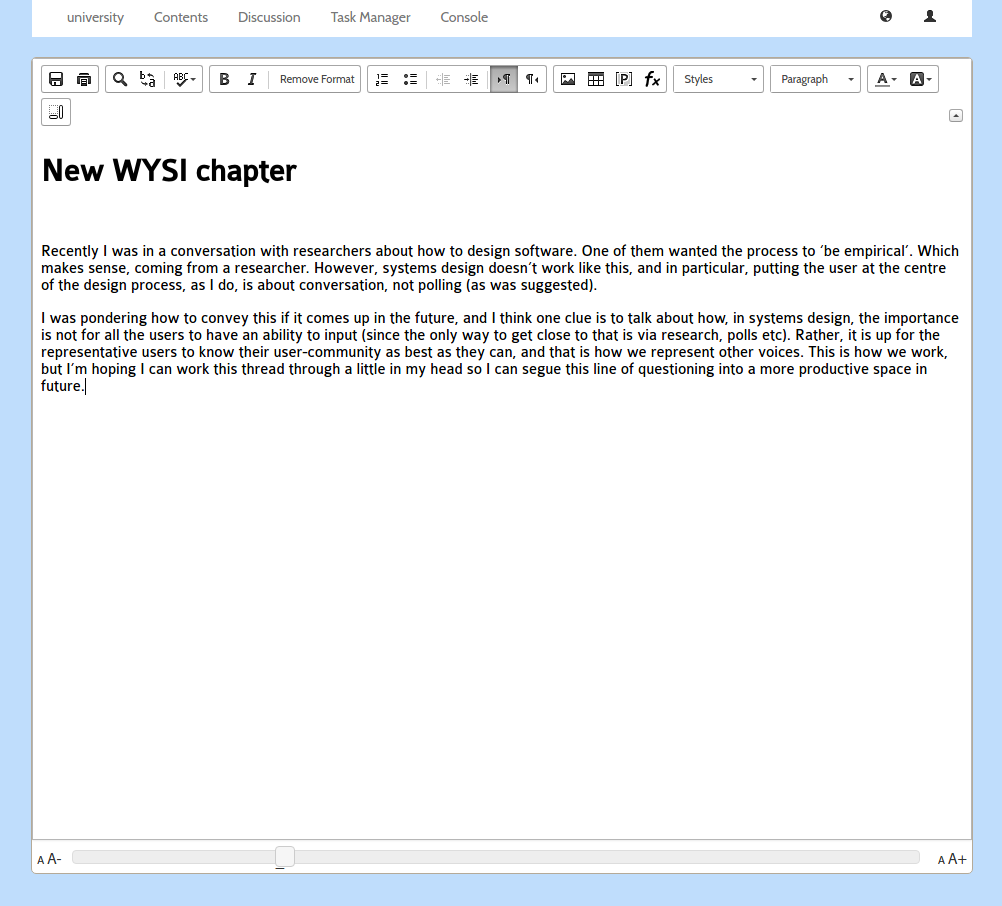
..table of contents manager…

and editor. Just like before!
We also introduced some new innovations including visualisations of the book production process…
Plus annotation (using Nick Stennings annotator software)…
and other stuff…I think threaded discussions, outline views, review page, an in-browser book renderer, book stats and I can’t remember what.
Anyway …I also built a platform on top of this old PubSweet for the United Nations Development Project. It was called Lexicon. Lexicon was pretty interesting as it opened my mind for the first time to the idea that an editor is not an editor is not an editor. Different content types (in a book) may require different editors or production environments.
Lexicon was produced to collaboratively produce a tri-lingual (Arabic, French, English) lexicon of electoral terms for distribution in Arabic regions.
Lexicon had all the same stuff as the old PubSweet but with one major innovation, you could create chapters that were WYSIWYG based, or you could create a chapter which enabled you to add and sort individual terms and provide translations.
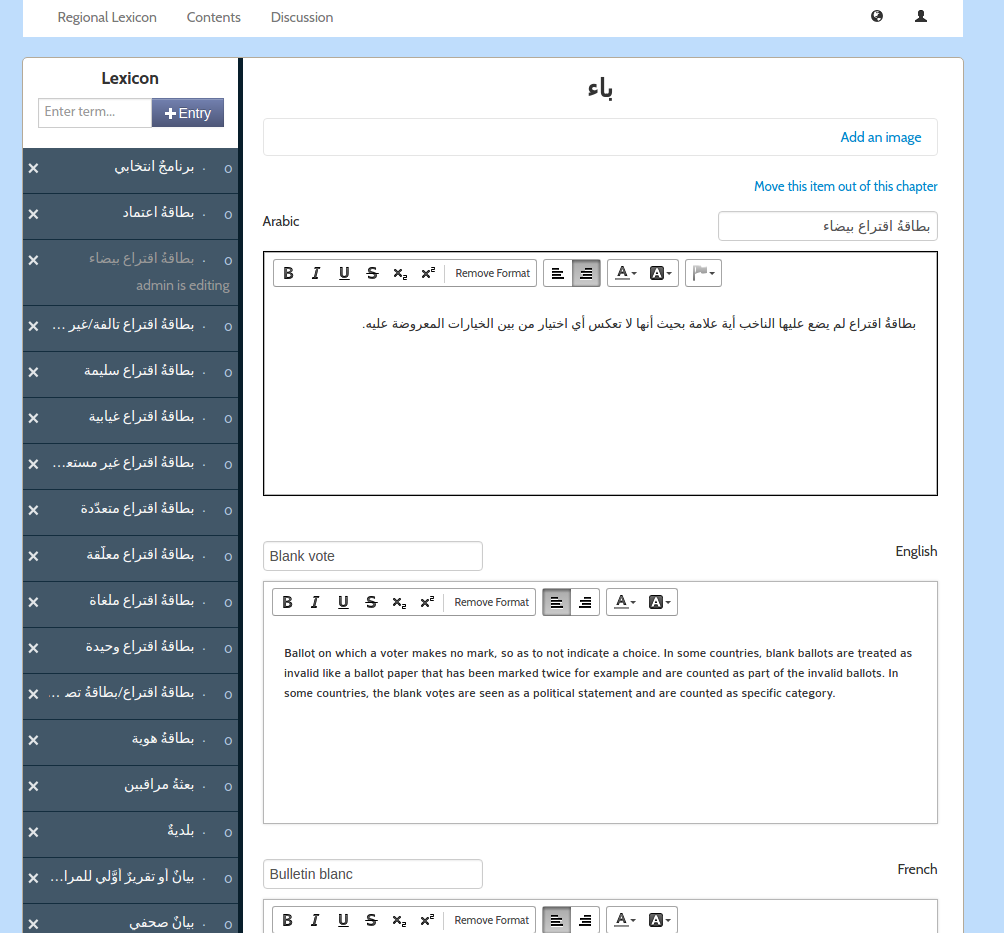
It was a pretty interesting idea and we were able to make a really cool book which the UNDP printed and distributed across many Arabic-speaking countries. I still have the book on my bookshelf.
The other interesting thing was that the total cost for building this on top of the old PubSweet was $10,000 USD. This was mostly because we could leverage all the existing stuff and just build the difference…interesting idea!
Ok, so then I dropped book production systems around 2013 or so for a while and went to work for PLoS on a system that was called Tahi and then became Aperta. The name Tahi came from the name of the street I was living on in New Zealand before I had a US work visa and was designing the system – Reotahi Road (cool road). Reotahi means ‘one voice’ and ‘tahi’ means ‘one’ in Maori. It was built on Rails with Ember. Essentially the front end and backend were decoupled although it was really pushing the technology at the time to do this. I designed the system and moved to San Francisco to manage the team to build it.
Tahi (Aperta) had a dashboard (surprise!) and editor, just like the book production systems but I introduced two major innovations – Cards, and card-based workflow management interfaces. Unfortunately, while I was asked to come and build an open source system, things went a little weird at PLoS and they closed the repos, effectively making it a closed platform. So I quit. That also means I don’t have any screenshots to show you. Pity. If you sign an NDA with PLoS I believe they might show it to you.
However, you can picture it a little – imagine something like Trello, or Wekan – these are card based kanban systems. But imagine if you could custom make cards to do anything. Effectively cards were first class citizens of the platform and could access the db, perform system operations, make external calls, do validations, whatever you wanted. In hindsight, I think they were as close to an idea of an ‘app’ that you could have in a browser platform, although that wasn’t the way I thought about them at the time. Additionally, cards were imported into the system since each card was actually a gem file. This meant any publisher could custom make their own cards to do whatever they wanted and place them within the kanban-like workflow space (task manager). Pretty neat.
So, cards could be surfaced and used anywhere in the system. We used them for authors to enter submission data, but also for production staff to perform operations, for reviewers etc etc etc. They could also be placed on a kanban board to make a workflow. Cards could be moved around the workflow and deleted or new ones added at any time.
To manage all this my other idea was to let these cards flow through a TweetDeck-like interface. So you could sort cards, per role, per user, at volume.
Tahi essentially had four spaces – a dashboard, a submission page (which displayed the manuscript in an editor, and submission data could be entered through cards), a task manager (workflow for the article, using cards as tasks), and a ‘flow manager’ (the TweetDeck-like interface for sorting all your cards across all your articles). While the FLOSS Manuals, Booki and Booktype platforms were pretty much monolithic systems, the old PubSweet was sort of modular. However, Tahi did decouple the front end and back end but I wanted to also break these four spaces into discreet components. That would have given the system enormous flexibility but unfortunately I wasn’t able to do this before I left.
Anyways, Tahi/Aperta is a little old now but it was pretty cool. I don’t know what happened to Aperta but I believe it is now being used for PLoS Biology.
After I left PLoS I was offered a Fellowship by the Shuttleworth Foundation to continue on the mission to reform publishing. So I started Coko with Kristen Ratan (who was the publisher at PLoS)….

So there are some themes from building the past 7 or 8 publishing systems (depending on how you count it… there were also some other interesting experiments in between). First, the next system you build is always better. That is for sure. It’s an important thing to realise because when I developed the FLOSS Manuals system I thought that was it. Nothing could be better! But I was wrong. Then Booki/Booktype and I felt the same thing. I was so proud of it and nothing could be better! haha… you get the picture. The reason why it’s important to understand this is because I think it gives someone like me a bit of freedom. I can take some risks with systems knowing you get some stuff right, you get some stuff wrong. But the next system will get that bit you got wrong, right. Taking this attitude also takes the pressure off and you can have more fun which is good for your health, the team you are working with, and the system.
As far as technical lessons learned… well… after looking back at all these systems when we started Coko, I realised that the idea of independent ‘spaces’ for publishing workflows had a heap of currency. How many systems did I have to build with baked in dashboards, task managers, editors, table of content managers, etc etc etc before I could realise it doesn’t make sense to do this over and over. I wanted to take the idea of these kinds of spaces forward and not have to build them again and again… so some kind of system where you could include whatever spaces/components you wanted would be ideal… This would have two very important side benefits:
- I could learn so much because if the next system you build is always better, what about a framework that would allow you to easily build a whole lot of systems at once! Or build a lot quickly over a short amount of time… just imagine how much you could learn…
- It would open the door for others to innovate. I have since given up the idea that my system (so to speak) was the best ever and no one could top it. That’s just the testosterone talking. I’m kinda over it (sorta). I want other people to be able to make better stuff than what I have produced so far, to bring in innovations I never thought of. I want to make that easy for them and now I understand a whole lot better how publishing workflows actually work I’m in a very good position to do that.
That was a lot of the thinking behind the new PubSweet – PubSweet 1.0. But there is some other stuff too. Through my time at PLoS, I came to understand just how many variables affect workflow choices in journal publishing and that each publisher has slightly different conditions and roles that affect this. That means that the access control is complex. We might think there are various roles – author, editor, reviewer etc that shepherd an article through a process but it’s not that simple. Any number of conditions can affect who gets to see or do what and when. So we need to have a very sophisticated way to set and manage this.
There was a lot of other stuff to take into account to but I mention these two specifically because recently when I was talking to Jure (lead PubSweet dev) about PubSweet 1.0 and reflecting on how far we came he nailed it, he identified the two major innovations of the system being:
- reusable/sharable components (spaces)
- attribute-based access control
I agree entirely. I think I might add another:
It is pretty easy, and getting easier, for developers to develop publishing platforms/workflows (call them what you will) with PubSweet. I think it is pretty astonishing and I think these 3 characteristics put together enable us to build multiple publishing systems fast and in parallel (with small teams) as well opening the door for other to do the same and huge opportunities for innovation.
If we are successful at building community this will be a huge contribution to the publishing sector.
In a future post, I’ll break PubSweet spaces / components down in more detail. There were also a lot of other similar stories regarding technical innovations on the way (eg Objavi->iHat->INK), but I’ll break them down into posts on another day.
I meant to also talk about Editoria here, the monograph production system built on top of PubSweet, and xpub – the PubSweet-based Journal system.

They are both pretty amazing and leverage so much more than the previous systems identified above.

I think the main thing with them is that we are working extremely closely with publishers using the method I developed – the Cabbage Tree Method.

This means that I am no longer involved in building, what I would call, naive publishing systems. Naive in the sense that publishers could use, for example, Booktype, but it’s not really built for publishers. It’s a general book production system built by someone who didn’t know much about publishing at the time. That’s great of course, there is a place for it. However, Editoria is not a naive system. It is designed by publishers for publishers and the difference is enormous.
But I will leave a longer rant about this for another post.
I do however, want to say that I didn’t, of course, build any of the above systems by myself. There were many people involved and I have credited them elsewhere in this blog. I’m not going to do another roll call here except for Jure Triglav.
Jure and I sat down just over 18 months ago to discuss some of the lessons I learned as explained above. We jammed it out over post-its, whiteboards, coffee, and food in Slovenia and you can read a little more about that process in the PubSweet 2.0 RFC. But Jure trusted me, and I trusted him, and he took these ideas and, with a small team in very good speed, made them a reality. As a result, I think PubSweet is an exciting system and will only get better. Congratulations Jure, you deserve special thanks and recognition for the absolutely amazing job you have done.