We are pretty close to our PubSweet 1.0 with the RFC now out for PubSweet 2.0, and a PubSweet dev site release next week.
It has been an amazing effort, particularly by Jure Triglav, the lead dev for PubSweet at Coko, but also fantastic work from Richard Smith-Unna, Alf Eaton, Yannis Barlas, and Christos Kokosias. Also more recently some great contribution from Alex Georgantas.
So, we are pretty much there and I’m presenting in San Francisco this week as part of a small Coko event to reflect on the future of the framework and discuss the RFC. For this purpose I’d thought I’d write a post to help me think through the thinking that got us here.
So…the thinking behind PubSweet started when I came back from Antarctica around 2007 or so (I was there setting up an autonomous base for artist-scientist collaborations).
I decided I wanted to give up the art world and try something new. The something new turned out to be FLOSS Manuals – a community writing free manuals about free software. I started it when I was living in Amsterdam somewhere around 2007. In order to execute on this mission I needed to get a couple of things sorted. Namely, learn how to build community, work out processes for rapid book production, and work out the tooling.
The tooling started with me scratching around with TWiki. A wiki written in Perl that happened to have the best plugins for rendering PDF. I scratched around, writing some Perl and cutting and pasting a whole lot more, and added some crazy .htaccess URL rewriting to produce a basic system for producing books. It was pretty scratchy but it actually worked. Later a buddy helped extend the system and later still I was able to pay him and others to extend it.
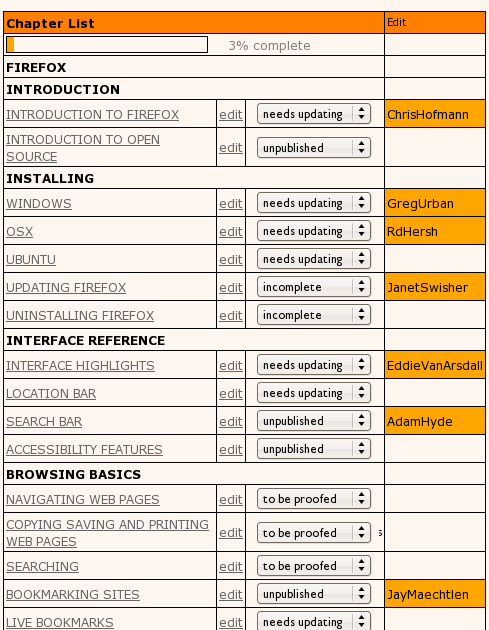
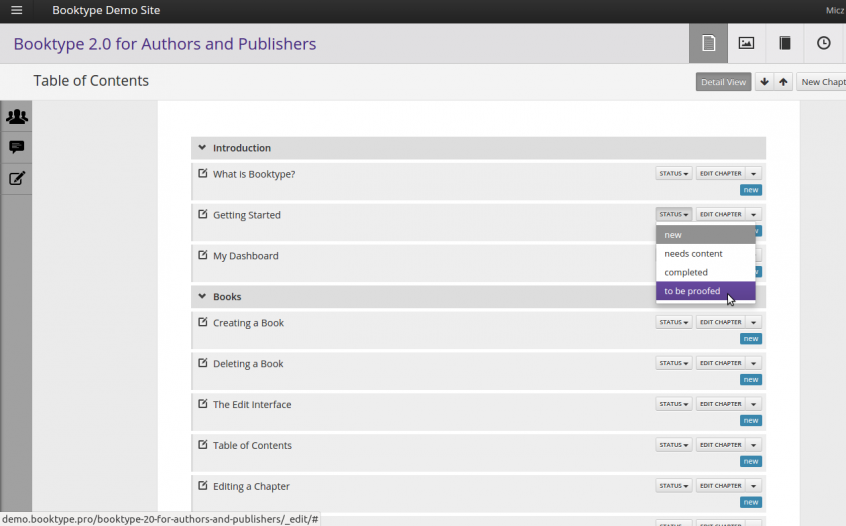
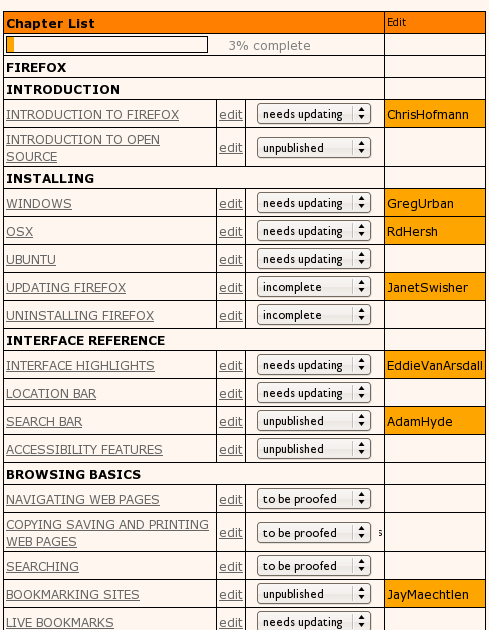
At the time it pretty much comprised a page (per book) for creating a table of contents.
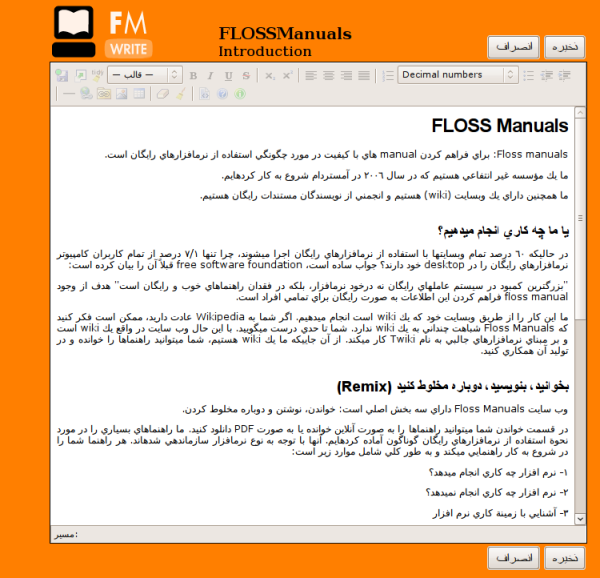
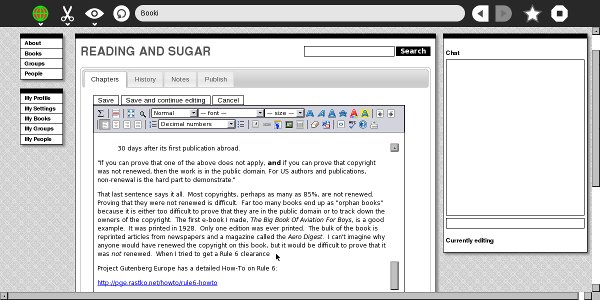
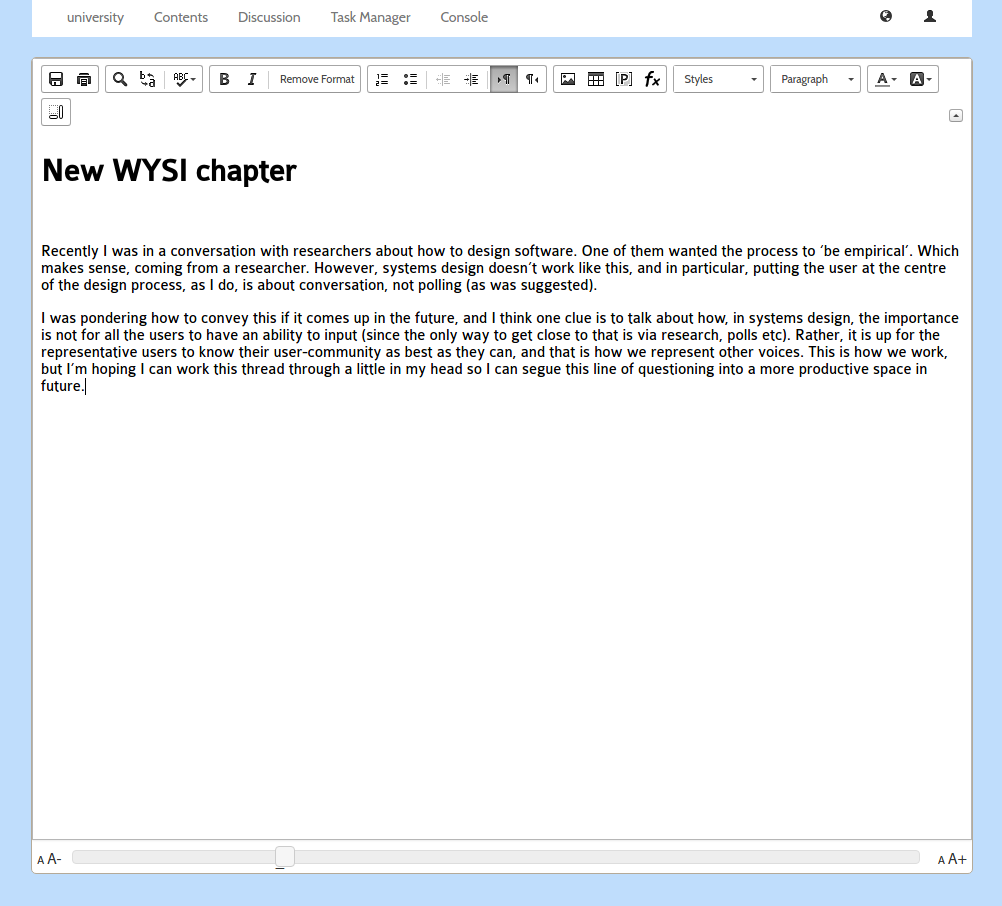
and an interface to edit the content (chapters). I ripped out the native wiki markup editor and replaced it with a WYSIWYG editor, I think it was TinyMCE…
As you can see Right-to-Left content (in this case, Farsi) was also supported. There were also some basic things in place for keeping track of the status of a chapter, the version number, side by side diffs, side by side translation interfaces, and, later, dynamic table of contents organisation and edit locks.
Coupled with some basic PDF rendering stuff and a way to push the content from the ‘draft’ to the publishing front end and we were away.
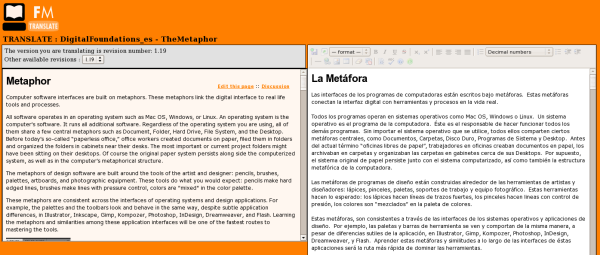
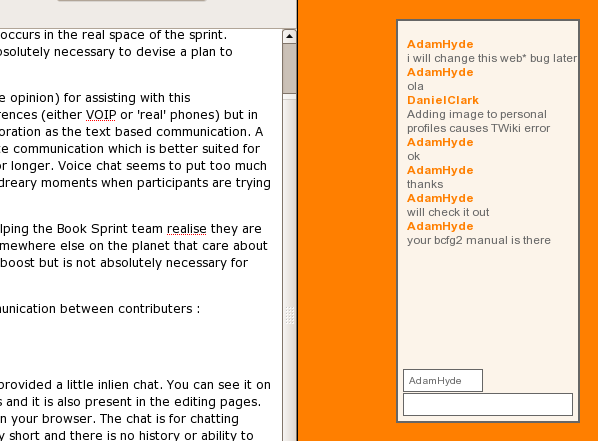
It actually had some other pretty cool stuff, such as side by side translation interfaces…
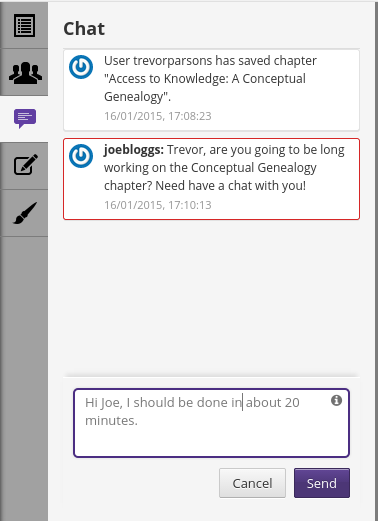
..a built in live chat for talking with collaborators…
and even a way to send books between different instances (eg for sending a book from the FLOSS Manuals French community site to FLOSS Manuals Finnish for translation)….
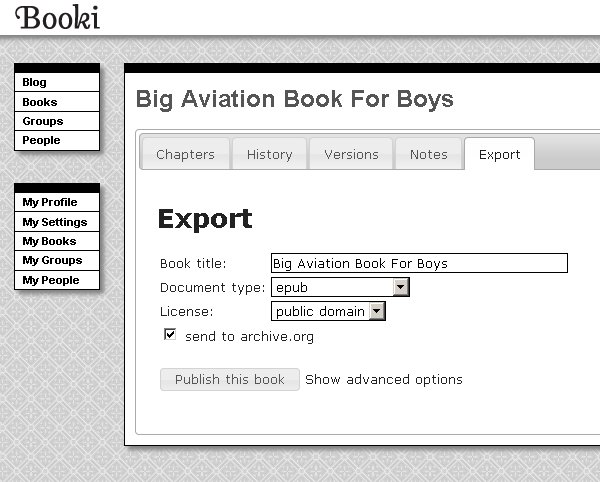
We could even render book formatted PDF and push to the lulu.com print on demand services. I just now checked and some of the books are still there!
Not bad for a Perl-based system, built on top of a wiki that wasn’t supposed to do this kind of thing, and built very with very few resources. The TWiki extensions were contributed back upstream to the TWiki repo and it was all open source but it was pretty hard to rebuild and no one I knew actually had a similar use case.
After this, I embarked on a journey to replace the system with a custom built solution specifically for book production. I can’t remember exactly when this started, maybe 2008 or 2009 or something. It was originally called Booki…
Booki was built with Django (python) and pretty much had all the same stuff. Although the look and feel was changed quite a bit in the transition. There aren’t too many images around of Booki although I did find these screenshots of Booki taken by someone using it on the OLPC XO! (FLOSS Manuals did all the docs for OLPC/Sugar OS etc).
It was hard to get financial support for it. Internet Archive gave us $25,000 at the time which seemed like a fortune. The evolution of Booki to Booktype represented me taking the project to a buddy’s in Berlin (I was living there at the time) based org (Sourcefabric) and parking it there so I could get more resources to build it out.
Booki/Booktype pretty much had, and has, the same stuff as the FLOSS Manuals system, just purpose built. So it had, a table of contents manager
And a book (chapter) editor…
…chat…
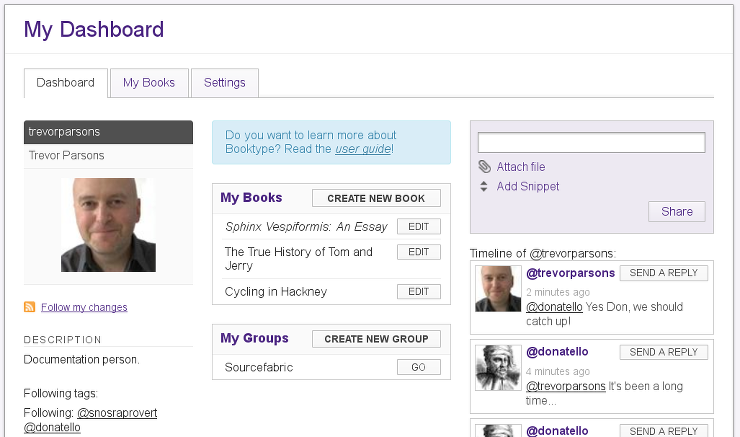
And the other stuff. Perhaps the only new features (compared to the FLOSS Manuals system) were a dashboard…
…groups…
and an interesting way to have Twitter-like messaging to pass snippets from chapters to other users.
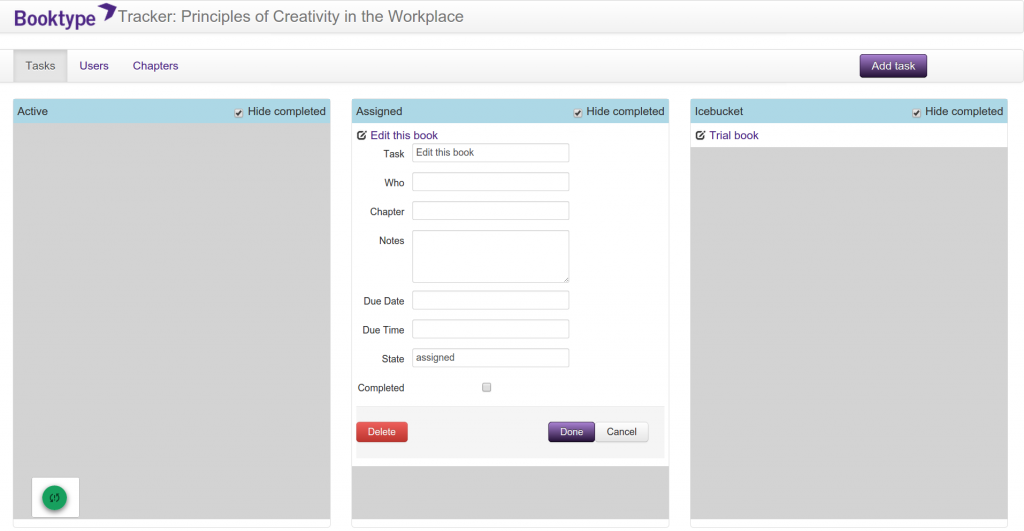
Before I left Sourcefabric I wanted to get some other innovations built but didn’t get there. I did build some prototypes though. There was a task editor…
…and live in-browser book design…
Booktype is still going strong, now it is its own company (based in Berlin) and they also run the Omnibook commercial service using the software.
I left because John Chodacki and Kristen Ratan from PLoS invited me to come work for PLoS to design a new web-based journal submission system. I agreed…
But, before I leave the book story behind for a bit..I had set up Book Sprints as a company and put a small amount of my own money into building two new book production systems somewhere between leaving Sourcefabric and starting at PLoS. These two systems were PHP-based and Juan Gutierrez built them over some months.
I wanted to do this because I was a little frustrated by Booktype not moving forward and also the platform was becoming more difficult to use. We were using it for Book Sprints but after I left the product took a new UI direction and I was finding Book Sprints participants were not enjoying using the system. So I built a Book Sprints specific system called… PubSweet… the namesake of the current Coko system which has eventually turned into something of a prototype for the new PubSweet… this new system was a lot simpler and easier to use than Booktype. It was initially meant to be modular but I think we lost that somewhere along the way. Cleanly modular systems take a lot of extra effort and time to produce so we gave in for speed of development’s sake.
The old PubSweet had a dashboard….
..table of contents manager…
and editor. Just like before!
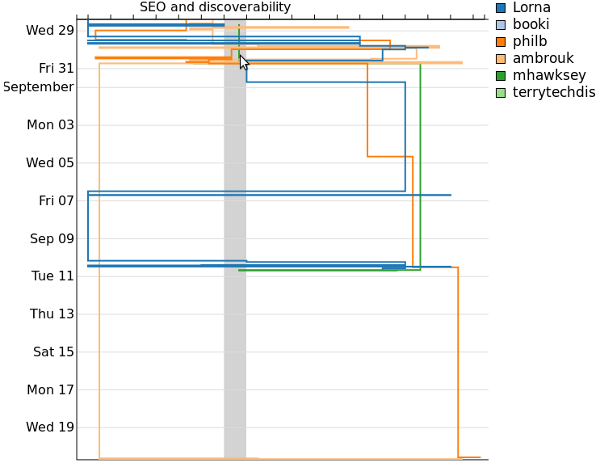
We also introduced some new innovations including visualisations of the book production process…
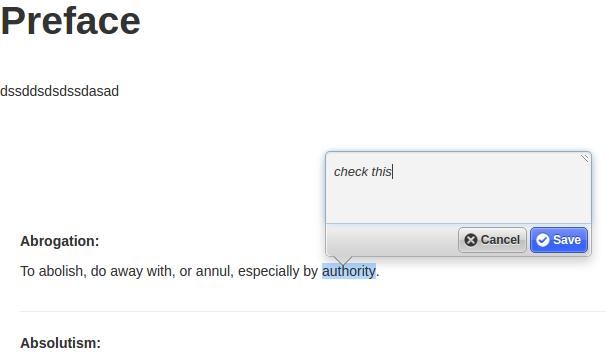
Plus annotation (using Nick Stennings annotator software)…
and other stuff…I think threaded discussions, outline views, review page, an in-browser book renderer, book stats and I can’t remember what.
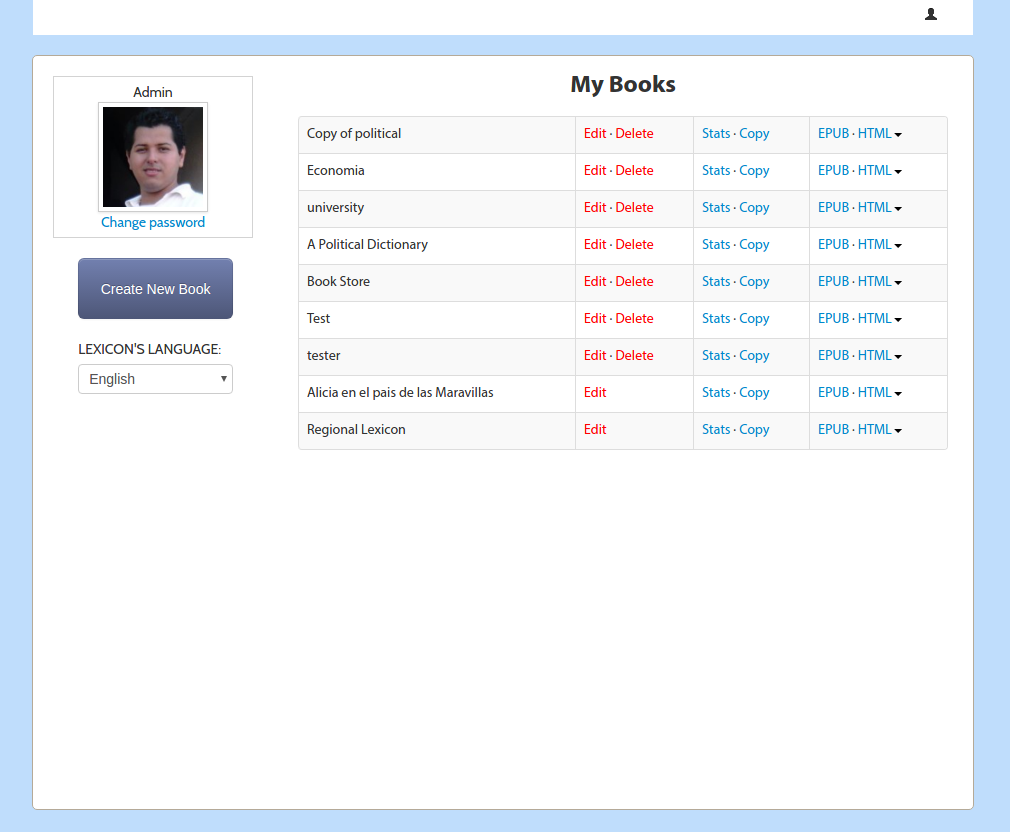
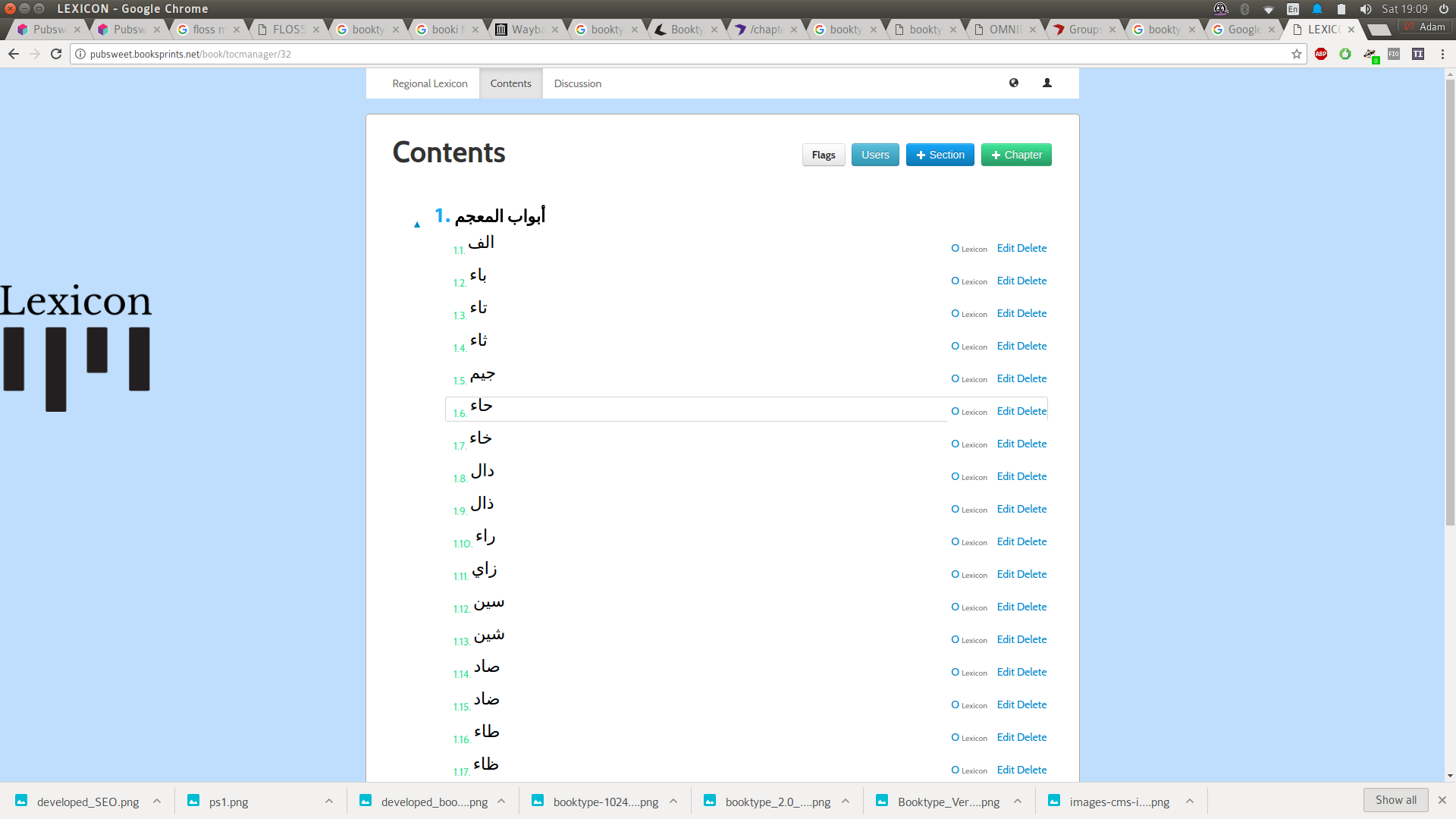
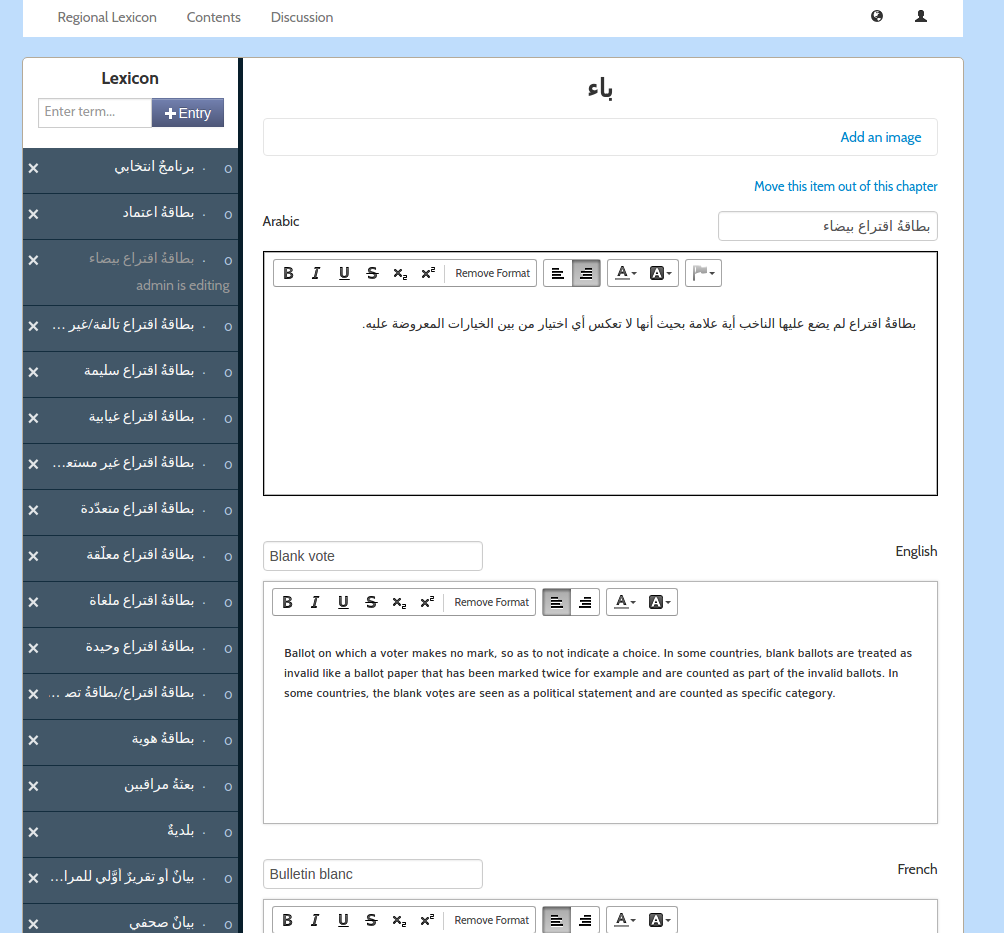
Anyway …I also built a platform on top of this old PubSweet for the United Nations Development Project. It was called Lexicon. Lexicon was pretty interesting as it opened my mind for the first time to the idea that an editor is not an editor is not an editor. Different content types (in a book) may require different editors or production environments.
Lexicon was produced to collaboratively produce a tri-lingual (Arabic, French, English) lexicon of electoral terms for distribution in Arabic regions.
Lexicon had all the same stuff as the old PubSweet but with one major innovation, you could create chapters that were WYSIWYG based, or you could create a chapter which enabled you to add and sort individual terms and provide translations.
It was a pretty interesting idea and we were able to make a really cool book which the UNDP printed and distributed across many Arabic-speaking countries. I still have the book on my bookshelf.
The other interesting thing was that the total cost for building this on top of the old PubSweet was $10,000 USD. This was mostly because we could leverage all the existing stuff and just build the difference…interesting idea!
Ok, so then I dropped book production systems around 2013 or so for a while and went to work for PLoS on a system that was called Tahi and then became Aperta. The name Tahi came from the name of the street I was living on in New Zealand before I had a US work visa and was designing the system – Reotahi Road (cool road). Reotahi means ‘one voice’ and ‘tahi’ means ‘one’ in Maori. It was built on Rails with Ember. Essentially the front end and backend were decoupled although it was really pushing the technology at the time to do this. I designed the system and moved to San Francisco to manage the team to build it.
Tahi (Aperta) had a dashboard (surprise!) and editor, just like the book production systems but I introduced two major innovations – Cards, and card-based workflow management interfaces. Unfortunately, while I was asked to come and build an open source system, things went a little weird at PLoS and they closed the repos, effectively making it a closed platform. So I quit. That also means I don’t have any screenshots to show you. Pity. If you sign an NDA with PLoS I believe they might show it to you.
However, you can picture it a little – imagine something like Trello, or Wekan – these are card based kanban systems. But imagine if you could custom make cards to do anything. Effectively cards were first class citizens of the platform and could access the db, perform system operations, make external calls, do validations, whatever you wanted. In hindsight, I think they were as close to an idea of an ‘app’ that you could have in a browser platform, although that wasn’t the way I thought about them at the time. Additionally, cards were imported into the system since each card was actually a gem file. This meant any publisher could custom make their own cards to do whatever they wanted and place them within the kanban-like workflow space (task manager). Pretty neat.
So, cards could be surfaced and used anywhere in the system. We used them for authors to enter submission data, but also for production staff to perform operations, for reviewers etc etc etc. They could also be placed on a kanban board to make a workflow. Cards could be moved around the workflow and deleted or new ones added at any time.
To manage all this my other idea was to let these cards flow through a TweetDeck-like interface. So you could sort cards, per role, per user, at volume.
Tahi essentially had four spaces – a dashboard, a submission page (which displayed the manuscript in an editor, and submission data could be entered through cards), a task manager (workflow for the article, using cards as tasks), and a ‘flow manager’ (the TweetDeck-like interface for sorting all your cards across all your articles). While the FLOSS Manuals, Booki and Booktype platforms were pretty much monolithic systems, the old PubSweet was sort of modular. However, Tahi did decouple the front end and back end but I wanted to also break these four spaces into discreet components. That would have given the system enormous flexibility but unfortunately I wasn’t able to do this before I left.
Anyways, Tahi/Aperta is a little old now but it was pretty cool. I don’t know what happened to Aperta but I believe it is now being used for PLoS Biology.
After I left PLoS I was offered a Fellowship by the Shuttleworth Foundation to continue on the mission to reform publishing. So I started Coko with Kristen Ratan (who was the publisher at PLoS)….
So there are some themes from building the past 7 or 8 publishing systems (depending on how you count it… there were also some other interesting experiments in between). First, the next system you build is always better. That is for sure. It’s an important thing to realise because when I developed the FLOSS Manuals system I thought that was it. Nothing could be better! But I was wrong. Then Booki/Booktype and I felt the same thing. I was so proud of it and nothing could be better! haha… you get the picture. The reason why it’s important to understand this is because I think it gives someone like me a bit of freedom. I can take some risks with systems knowing you get some stuff right, you get some stuff wrong. But the next system will get that bit you got wrong, right. Taking this attitude also takes the pressure off and you can have more fun which is good for your health, the team you are working with, and the system.
As far as technical lessons learned… well… after looking back at all these systems when we started Coko, I realised that the idea of independent ‘spaces’ for publishing workflows had a heap of currency. How many systems did I have to build with baked in dashboards, task managers, editors, table of content managers, etc etc etc before I could realise it doesn’t make sense to do this over and over. I wanted to take the idea of these kinds of spaces forward and not have to build them again and again… so some kind of system where you could include whatever spaces/components you wanted would be ideal… This would have two very important side benefits:
I could learn so much because if the next system you build is always better, what about a framework that would allow you to easily build a whole lot of systems at once! Or build a lot quickly over a short amount of time… just imagine how much you could learn…
It would open the door for others to innovate. I have since given up the idea that my system (so to speak) was the best ever and no one could top it. That’s just the testosterone talking. I’m kinda over it (sorta). I want other people to be able to make better stuff than what I have produced so far, to bring in innovations I never thought of. I want to make that easy for them and now I understand a whole lot better how publishing workflows actually work I’m in a very good position to do that.
That was a lot of the thinking behind the new PubSweet – PubSweet 1.0. But there is some other stuff too. Through my time at PLoS, I came to understand just how many variables affect workflow choices in journal publishing and that each publisher has slightly different conditions and roles that affect this. That means that the access control is complex. We might think there are various roles – author, editor, reviewer etc that shepherd an article through a process but it’s not that simple. Any number of conditions can affect who gets to see or do what and when. So we need to have a very sophisticated way to set and manage this.
There was a lot of other stuff to take into account to but I mention these two specifically because recently when I was talking to Jure (lead PubSweet dev) about PubSweet 1.0 and reflecting on how far we came he nailed it, he identified the two major innovations of the system being:
reusable/sharable components (spaces)
attribute-based access control
I agree entirely. I think I might add another:
developer experience
It is pretty easy, and getting easier, for developers to develop publishing platforms/workflows (call them what you will) with PubSweet. I think it is pretty astonishing and I think these 3 characteristics put together enable us to build multiple publishing systems fast and in parallel (with small teams) as well opening the door for other to do the same and huge opportunities for innovation.
If we are successful at building community this will be a huge contribution to the publishing sector.
In a future post, I’ll break PubSweet spaces / components down in more detail. There were also a lot of other similar stories regarding technical innovations on the way (eg Objavi->iHat->INK), but I’ll break them down into posts on another day.
I meant to also talk about Editoria here, the monograph production system built on top of PubSweet, and xpub – the PubSweet-based Journal system.
They are both pretty amazing and leverage so much more than the previous systems identified above.
I think the main thing with them is that we are working extremely closely with publishers using the method I developed – the Cabbage Tree Method.
This means that I am no longer involved in building, what I would call, naive publishing systems. Naive in the sense that publishers could use, for example, Booktype, but it’s not really built for publishers. It’s a general book production system built by someone who didn’t know much about publishing at the time. That’s great of course, there is a place for it. However,Editoria is not a naive system. It is designed by publishers for publishers and the difference is enormous.
But I will leave a longer rant about this for another post.
I do however, want to say that I didn’t, of course, build any of the above systems by myself. There were many people involved and I have credited them elsewhere in this blog. I’m not going to do another roll call here except for Jure Triglav.
Jure and I sat down just over 18 months ago to discuss some of the lessons I learned as explained above. We jammed it out over post-its, whiteboards, coffee, and food in Slovenia and you can read a little more about that process in the PubSweet 2.0 RFC. But Jure trusted me, and I trusted him, and he took these ideas and, with a small team in very good speed, made them a reality. As a result, I think PubSweet is an exciting system and will only get better. Congratulations Jure, you deserve special thanks and recognition for the absolutely amazing job you have done.
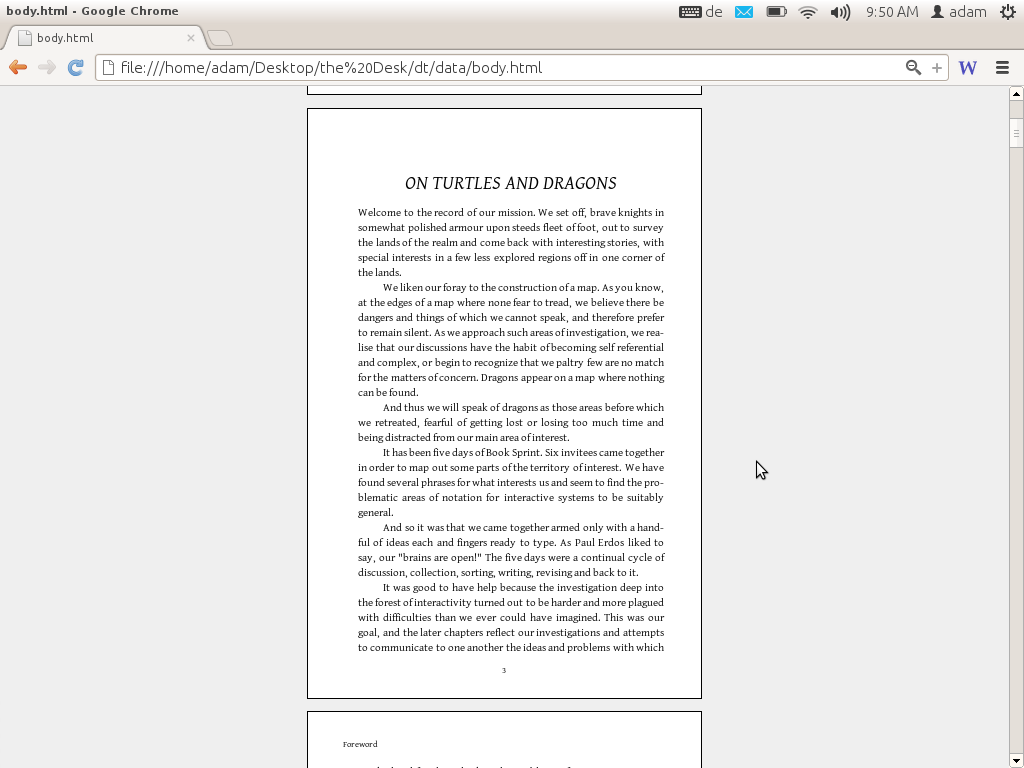
Booktype is still going very well and has also spawned the very interesting Omnibook service. Due to the recent interest in this project, I revisited this old video which documents some of the exploratory thinking I had when leading the Booktype team at Sourcefabric. It was recorded May 2012 at #dev8ed in Birmingham, UK. At the time I was leading a small team, having just migrated Booki (FLOSS Manuals) to Booktype (at Sourcefabric).
I found the video really interesting as it covers my thinking at the time, (developed over many years of experimenting in this area) over many issues, including rendering books in the browser and using the browser as a design environment for books. There are some nice quotes which accurately reflect how I was thinking then which are interesting:
“there is no one taking responsibility for designing environments where you can target both flowable text as an output like Kindle or EPUBS, and at the same time, target fixed page outputs like paper books. So we are trying to work this out at the moment. How do you deal with this? .[…] We are trying to work out how can you possibly find a paradigm that fits both flow-based, and fixed page, design” [36min 25s]
and
“what we want to see [in the browser] is when you are outputting to book-formatted PDF, we want to see like you see in Google Docs – exactly the page dimensions that you are going to get when you output the PDF. Google Docs does some sort of magic where that is possible, we haven’t yet cracked it ourselves, but for fixed page design we think it is quite important that what you see in the HTML page is what you would eventually get in the PDF. [41min 37s]
…
“…how do you actually render one to one representation of a book-formatted PDF in a browser?” [49min 49s]
…
“…we can have JavaScript playing a role in rendering elements of pages for book-formatted PDF.” [16min 58s]
…
“…we take the Booktype content as HTML, HTML as the base format, and Objavi formats that into one long HTML page for which we have specific CSS rules to structure the book in a specific way. Then we run WKHTML over the top of it, and a number of other tools, and we assemble a book out of it, book-formatted PDF” [18min 38s]
…
“Thats because WKHTMLTOPDF is webkit, the browsing engine behind Chrome and Safari, … so you can use CSS, and JavaScript and everything from webkit, and turn it into a PDF” [19min 50s]
…
“…the advantage of using webkit as part of the rendering environment, as webkit is a browser, [is that] if you design in the browser you have a one to one co-relation between content creation environment and output environment” [33 min 49sec]
To be clear, we were already using browser engines to make books for quite some time, and Douglas Bagnall, a friend who also worked with me at FLOSS Manuals, even investigated collaborating with the Gecko (Mozilla layout engine) developers to add widows and orphans controls and the CSS page-break control (which we needed for books), in 2010 or so. Actually, it was pretty cool because Douglas, myself and Robert O’Callahan (Mozilla layout engine dev) were all New Zealanders. But FLOSS Manuals had been making books for many years with browser engines since Behdad Esfahbod advised me to explore this, many years earlier. We knew browsers could be used for producing book-formatted PDF and we had been doing it for years.
However, as I have learned over the years, there is an important role for vision, experimentation, and theoretical exploration prior to developing good software. Hence, I was now exploring how you could take these positions further to design books in the browser client. Rendering PDF was one part of the story, the other was working out the tools to take book design to the browser. This was what Adobe was also after, I believe, when they implemented CSS Regions in webkit and started on their Adobe Edge Reflow line of products that leveraged the browser as a ‘design surface’. They were interesting times.
While BookJS didn’t quite get to be the design environment I was (and still am) after, it was still a good tool. In an attempt to get to a design and rendering solution in the browser, we later took the Booktype Designer (demonstrated in the video) ideas to a JavaScript prototype called StyleJS for integrating with BookJS but, unfortunately, it didn’t make it to production. StyleJS enabled a kind of ‘WYSIWYG’ tool for styling a page live. Which is an interesting prototype for future in browser book production exploration.
Work continued on BookJS and it has had a useful life despite some quirky turns in the road. During this time, the Booktype team worked with several people on the development of BookJS and received good advice and contributions from Mihai Balan (from the Adobe CSS Regions team), Phil Schatz (from Connexions), Maria Fraser (University College London) and others. As with many software projects, contributions like this deserve a lot of credit, as I have written elsewhere, since these contributions are not always preserved in the code.
In the Booktype world, Juan Gutierrez (who worked on BookJS at Sourcefabric, and now works with me at Coko) extended BookJS to support the CSS Regions polyfil. It is still in use now with Book Sprints for rendering books. Consequently, we are still very grateful that Booktype and Sourcefabric kept the BookJS product AGPL after I left the project so we could extend it. Hurray for Open Source!
It is good to see Booktype going strong, Sourcefabric still invested in Open Source, and a growing interest around Omnibook. I know the team there, Micz Flor (co-founder of Sourcefabric and Managing Director of Booktype) being an old friend, and Julian Sorge also makes a great Booktype Managing Director. They have brought their own vision to the Booktype products, pushing them in new directions, and it is really great to see. I’m hoping they will continue to go from strength to strength.
In summary, these were interesting, productive times. Sourcefabric provided the opportunity for Booktype to grow, and I experimented a lot, as I had done at FLOSS Manuals (and continue to do now), with new ideas and approaches. There was some great software, books, and ideas that came out of that period. Some of the books we made I have even kept with me through my travels. In the video, for example, I demonstrate the Booktype Designer. We built the Designer before and during the Sandberg Institute workshop I led in Amsterdam and used it in the same month as I did the presentation to create this wonderful artist’s book. I carried it with me all over the world and still have it on my bookshelf now!
Wow…I was browsing some old archives to update this new version of my site. I found the most incredible stuff in the Internet Archives Wayback Machine including the outline of a description of Booki (2010) many years before it became Booktype. Amazing! I didn’t think I had the product manager in me but it seems once upon a time I was really focused on this kind of acute detail for product management. I had forgotten!
I’m so astonished how much of my thinking recorded in this email carries through to the way we are approaching product development for Coko now. The statement:
You might have noticed that I prefer to take the easy road for features, leaving as much open as possible, and then refine according to use. That is because,from experience, I have learned that when designing software it is better to be led by the user rather than force them into an imagined work flow.
Might as well be out of the Collaborative Product Design manifesto.
I’ts kind of incredible. The email documents so much of how we were thinking at the time, including using HTML and CSS to create paginated books using browser engines:
* Objavi utilises Webkit for PDF generation. Later Gecko will be added.
…and later in the product description…
3.2.2 CSS Book Design
Status: High Priority, Implemented
Function: The default PDF rendering engine for Booki is now Webkit and will eventually be Mozilla Firefox hence there is full CSS support for creating book formatted PDF in Booki. This changes the language of design from Indesign to CSS - which means any web native can control the design of the book.
Pretty interesting, if only to me! Anyway, the email is below, it documents some features we built on commission for Source Fabric before they eventually took over the project. Thank you for indulging me 🙂
From adam at flossmanuals.net Wed Jul 28 09:11:21 2010
From: adam at flossmanuals.net (adam hyde)
Date: Wed, 28 Jul 2010 18:11:21 +0200
Subject: [Booki-dev] notes to meeting
Message-ID: <1280333481.1582.143.camel@esetera>
hi Frank,
It was good to meet you and I'm glad Source Fabric is considering working with us and you to develop features they and we need (Aco is also keen for this).
I have sent this email to the dev list and to you and Micz. It might be good for you both to consider joining the list.
http://lists.flossmanuals.net/listinfo.cgi/booki-dev-flossmanuals.net
Below the content of this email is a very basic requirements doc. It does not outline the notes tab, so I thought I would make some notes here for your (and Micz's) consideration should Source Fabric decide they wish to commission all or part of this development.
In essence, I think that the notes tab could nest the following:
1. To do list
2. Book notes
3. Style guide
These could be hidden via a dropdown or accordian style interface. Our plan is to keep everything as simple as possible so I would imagine a page with three headings and clicking on each reveals the information behind it.
Some ideas:
1. To do list
The basic form could be a Jquery to do as we looked at today:
http://demo.tutorialzine.com/2010/03/ajax-todo-list-jquery-php-mysql-css/demo.php
If this is the format, it would be good enough as it is. The good news is that this is done using Jquery so I imagine this is a very easy implementation. What you would need to work out, however, is how Aco implements the dynamic updates so that when a to do is altered everyone has that info updated.
If there was room to take this development a step further, I would recommend considering adding the following fields:
* assigned to
* due date
* priority
I am not married to those ideas though as I think we need to insure that the interface does not have too many things going on. So I would actually recommend we start with the basic implementation and move on. When users have tried it then we can consider extending it with these items.
2. Book Notes
Something like etherpad would be good but too complex (see.
http://piratepad.net/ )
I would suggest considering either a) the same interface as we have now in the notes pad except with a very very simple WYSIWYG or b) a threaded comment system. I think the best would again be to do the easiest and simplest - what we have now with a WYSIWYG interface (and no need to press 'save'). Then when users use it we extend according to demand for most-needed features.
3. Style Guide
This is pretty much the same as (2) except it would be used for storing the Style Guide. A style guide is optional but many people request it in FLOSS Manuals and some go out of their way to create one so I think this would be a very good feature to anticipate based on our user experience so far.
I think all of the 3 above are simple and I think Source Fabric's working process (especially for the forthcoming Sprints) would benefit a lot from them.
You might have noticed that I prefer to take the easy road for features, leaving as much open as possible, and then refine according to use. That is because from experience I have learned that when designing software it is better to be led by the user rather than force them into an imagined workflow.
It has worked well for us so far - everything you now see in Booki is pretty much that way because we have tried similar ideas in FLOSS Manuals and seen their effect. I would prefer to continue to work this way with Booki.
So...there was one more feature we discussed - Chapter Level notes. I think this would be extremely useful for Source Fabric (but Micz needs to comment on this) but we need to be careful that we get it right because it is not so obvious how this might work.
I think the notes have to be associated with the chapter page when you edit it - however there is very little space there. One possibility is to build this into the WYSIWYG editor - Xinha - as a 'notes server' or some such. ie. it opens from the WYSIWYG editor but stores the content (chapter notes) in the booki db. The risk here is that people will not know that the notes are there...so we need to consider this. Another possibility is to build this into a 'sliding tab' as Micz suggested. I think that might be ok but it would have to be done carefully as it might look too much like a gimmick.
The other issue with chapter level notes is that I strongly believe that an overview of all chapter notes for a book should be able to be seen somewhere, in one place. Otherwise it would mean checking each chapter which would be a tedious job (books easily have 30+ chapters). So if you consider Chapter notes then you must also consider how to do this.
So on this I am not so clear what would work well for Chapter level notes and because of this I think it's not such a good feature for our first adventure working together. I would recommend instead the first three to be done all together - however this is up to Micz.
My feeling is that the first 3 are an extremely quick development, first however you need to know how it all fits together so i would suggest emailing this list when you have questions and I am sure Aco will answer your questions...
Also, Aco is currently working on the Booki site update so I expect the GIT repo is not updated but will be within the next days once the booki www is updated....
also you should meet Doug - doug is on this list and he is the Objavi (PDF generator) developer....doug - frank, frank - doug
also, meet John who does the Booki manual and other essential tasks intro intro :)
:)
adam
1 INTRODUCTION
1.1 Description
Booki is designed to help you produce books, either by yourself or collaboratively. A book in this context is a "comprehensive text" which can be output to book-formatted PDF (for book production), epub, odt, screen readable PDF, templated HTML and other formats.
Booki supports the rapid development of content. Booki has tools to support the development of content in 'Book Sprints'. Book Sprints are intensive collaborative events where collaborators in real and remote space focus on writing a book together in 3-5 days.
While you can use Booki to support very traditional book production processes, the feature set matches the rapid pace of publishing possible in the era of print on demand and electronic readers. Booki can output content immediately to multiple electronic formats. Print ready source (book formatted PDF) can be immediately generated, and then uploaded to your favorite Print on Demand (PoD) service, taken to a local printer, or delivered to a publisher.
1.2 Purpose
Booki embraces social and collaborative networked environments as the new production spaces for comprehensive (book) content.
1.3 Scope
Booki is available online as a networked service (http://www.booki.cc) for free. This service is a production tool for the creation of free content and not a publishing/hosting service. Content produced within Booki.cc is intended to be published elsewhere, either under another domain, in paper form (ie. books), distributed in electronic formats, or re-used in other content.
Booki can be installed by anyone wishing to utilise this software under their own domain or within private or local networks.
2 OVERALL DESCRIPTION
2.1 Product Perspective
Booki takes what was learned from building the FLOSS Manuals tool set and posits these lessons within a more suitable architecture.
Booki is the name of the collaborative production environment, however there are 2 associated softwares that provide all the services required :
Booki - production environment
Objavi - import and export engine
This document refers to Booki 1.5 and Objavi 2.2
2.2 Booki Functions
* User account creation requiring minimal information
* One click book creation
* Drag and drop Table of Contents creation
* One click editing of chapters
* Chapter level locks
* Live chat on a book and group level
* Live book status reports (editing, saving, chapter creation) delivered
to the chat window
* Drop down chapter status markers
* One click to join a group
* One click to add a book to a group
* One click exporting to epub, screen pdf, book formatted pdf, odt, html with default templates
* Easily accessible advanced styling options for export (CSS controlled)
* User profile control (status, image, bio)
* One click group creation
* Easy importing of book content from Archive.org, Mediawiki, other Booki installations
* Option to upload content to Archive.org
2.3 User Characteristics
2.3.1 Contributor
The majority of users will be contributors to an existing project. They may contribute to one or more project and may produce text and/or images, provide feedback or encouragement, proof, spell check, or edit content. These are the primary users and the tool set should first meet their needs.
2.3.2 Maintainer
These are advanced users that create their own books or have been elevated to maintainer status for a book by group admins. Maintainers have associated administrative tools for the books they maintain which are not available to other users.
2.3.3 Group admin
These are advanced users that wish to establish and administrate their own group. They have maintenance tools for every book in their group plus additional group admin tools.
2.4 Operating Environment
Booki is designed primarily for standards-based Open Source browser comparability but is tested against other browsers.
2.5 General Constraints
* Booki and Objavi are Python-based.
* Booki is built with the (bare) Django framework.
* Booki uses Jquery for dynamic user interface elements.
* Booki uses Postgres as the database but sqlite3 can also be used
* Redis is used by Booki for persistent data storage to mediate dynamic data delivery to the user interface
* Objavi utilises Webkit for PDF generation. Later Gecko will be added.
* Rendering of .odt by Objavi requires OpenOffice to be installed with unoconv.
* The Booki Web/IRC gateway may eventually (and optionally) require a dedicated standalone IRC service hosted on domain.
* Content editing in Booki is done by default with the Xinha WYSIWYG editor
* XHTML is the file format for content.
* Content will be ultimately be stored in GIT.
* Localisation in Booki is managed with Portable Object files (.po).
* The code repository for both projects is GIT with a dedicated Trac for bug reporting and milestone tracking :
http://booki-dev.flossmanuals.net
* A Dev mailing list is maintained here:
http://lists.flossmanuals.net/listinfo.cgi/booki-dev-flossmanuals.net
* Developers can be reached in IRC (freenode, #flossmanuals)
* Each release will be as source. Beta and later releases will also be available as Debian .deb packages.
* User and API Documentation will be maintained in the FLOSS Manuals
Booki Group.
* For development we use Apache2 for http delivery
* The license is GPL2+ for all softwares
2.5 User Documentation
Maintained here : http://www.booki.cc/booki-user-guide/
3 SYSTEM FEATURES
3.1 Booki Features
3.1.1 Booki-zip (Internal File Format)
Status: High Priority, Implemented
Function: A Booki-specific file structure for describing books
Interface: Used for internal data exchange between Booki and Objavi.
Notes: booki-zip definition maintained here :
http://booki-dev.flossmanuals.net/git?p=objavi2.git;a=blob_plain;f=htdocs/booki-zip-standard.txt
3.1.2 Account Creation
Status: High Priority, Partially Implemented
Function: Quick access to a registration form from the front page for account creation
Interface: Requires only username, password, email and real name (required for attribution). Email is sent to the user with autogenerated link for verification
Notes: email confirmation mechanism missing
3.1.3 Sign in
Status: High Priority, Implemented
Function: Quick access to a sign-in form from the front page
Interface: Username and Password form and submit button. Username and
pass remembered.
3.1.4 Profile Control
Status: Medium Priority, Implemented
Function: When logged in the user can access a profile settings page to set personal details (email, name, bio, image). Personal details can be browsed by other users
Interface: "My Settings" link in user-specific menu on left gives access to a form for changing the details.
3.1.5 Book Creation
Status: High Priority, Implemented
Function: Users can create a book from their homepage ("My Profile").
Interface: User can click on "My Profile" link from the user-specific menu on the left. On the Profile page a text field for the name of the book, and a license drop down menu (license *must* be set) is presented.
Clicking on "Create" adds the empty book with edit button to the listing of the users books on the same page.
3.1.6 Archive.org Book Import
Status: Medium Priority, Implemented
Function: Users can import books from Archive.org
Interface: "My Books" link in the user-specific menu on the left presents the user with a field for inputting the ID of any book from
Archive.org. The book is then imported when the user clicks "Import".
Notes : Interface is through Booki but Objavi does the importing and returns Booki zip to Booki. Relies on Archive.org successfully delivering epub for each book but this is not always happening. Needs error catching and user friendly progress/error messages.
3.1.7 Wikibooks Book Import
Status: Medium Priority, Implemented
Function: Users can import books from Wikibooks
(http://en.wikibooks.org)
Interface: "My Books" link in the user-specific menu on the left presents the user with a field for inputting the URL of any book from Wikibooks. The book is then imported when the user clicks "Import".
Notes : Interface is through Booki but Objavi does the importing and returns Booki zip to Booki. Needs thorough testing as it is sometimes failing possibly due to time-outs. Needs error catching and user friendly progress/error messages. Should be extended to be a "mediawiki import" tool, not just for Wikibooks.
3.1.8 Epub Book Import
Status: Medium Priority, Implemented
Function: Users can import any epub available online
Interface: "My Books" link in the user-specific menu on the left presents the user with a field for inputting the URL of any epub. The book is then imported when the user clicks "Import".
Notes : Interface is through Booki but Objavi does the importing and returns Booki zip to Booki. Needs thorough testing as it is sometimes failing possibly due to time-outs. Needs error catching and user friendly progress/error messages.
3.1.9 Group Creation
Status: High Priority, Implemented
Function: Users can create groups.
Interface: "My Groups" link in the user-specific menu on the left presents user with 2 text fields - group name, and description. When a name for a group is entered and "Create" is clicked then the group is created.
Notes: Group admin features missing.
3.1.10 Joining Groups
Status: High Priority, Implemented
Function: Users can join groups with one click.
Interface: "Groups" link in the general menu on the left presents a list of all Groups, by clicking on link the user is transported to the homepage for that group. At the bottom of the page the user can click "Join this group" and they are subscribed.
3.1.11 Adding Books to Groups
Status: High Priority, Implemented
Function: Users can add their own books to groups they belong to.
Interface: While on a Group page that the user is subscribed to the user can add their own books to the group.
Notes: When Group Admin features are in place we will change this so that Group Admins set who can and cannot add books to groups. At present a book can only belong to one group.
3.1.12 Readable Book Display
Status: High Priority, Implemented
Function: Users can read stable content in Booki without the need to log-in.
Interface: Upon clicking on the "Books" link in the general menu on the left a page listing all books is presented. Clicking on any of these presents a basic readable version of the stable content. Alternatively users can link to a book on the url http://[booki install domain]/[book name]
3.1.13 Edit Page
Status: High Priority, Implemented
Function: Page for editing content.
Interface: The edit page is accessed by clicking on "edit" next to the name of a book in "My Books" or "Books" (all books) listings. The user is then presented with a page with tabs for : editing, notes, exporting, history
3.1.14 Edit Tab
Status: High Priority, Implemented
Function: Edit interface for chapters.
Interface: Clicking ?edit? on a chapter title will open the Xinha WYSIWYG editor with the content in place.
3.1.15 Notes Tab
Status: High Priority, Implemented
Function: A place for contributors to keep notes on the development of the book
Interface: User clicks on the Notes tab for a book and is presented with a shared notepad for recording issues or discussing the development.
Notes : Implemented but future direction TBD
3.1.16 History Tab
Status: High Priority, Implemented
Function: Shows edit history of the book
Interface: User clicks on the history tab and can see the edit history with edit notes.
Notes: Implemented but unreadable. Users should also be able to access diffs here.
3.1.17 Export Tab
Status: High Priority, Implemented
Function: Export content to various formats
Interface: User clicks on the Export tab and is presented with a form for choosing export options. Clicking "Export" returns the desired output for download.
3.1.18 Version Tab
Status: High priority, Not Implemented
Function: can easily freeze content at stable stages while work continues on the unstable version.
Interface: From the Edit Page a maintainer sees an extra tab "Version".
>From here a maintainer can click "create stable version" - the last stable version is archived recorded and the current version becomes the new stable version.
3.1.19 Subscribe to edit notifications
Status: High Priority, Not Implemented
Function: Users can subscribe to edit notifications
Interface: User clicks "Subscribe to edit notifications" from the Edit Page for a book. If there are edits made a synopsis is emailed with basic edit information (time, chapter, person who made the change, version numbers) and a link to the diff.
3.1.20 Chat
Status: High priority, Implemented
Function: A real time chat (web / IRC gateway).
Interface: Persistent on the edit page for any book.
3.1.21 Localisation
Status: High priority, Not Implemented
Function: Booki needs to be available in any language where it is needed. Hence we may integrate the Pootle code base into Booki to enable localisation of the environment.
Interface: TBD
3.1.22 Translation
Status: High priority, Not Implemented
Function: Content can be forked and marked for translation. A
translation version of a book will provide link backs to the original
material, be placed in a translation work flow, and edited in a
side-by-side view where the translator can also see the original
source.
Interface: TBD
3.1.23 Copyright Tracking (Attribution)
Status: High Priority, Implemented
Function: Any user contributions are recorded and attributed.
Interface: All attributions are automated in Booki. Book level attribution is output in any chapter that contains the string "##AUTHORS##"
Note: should be a syntax for producing Attribution notes on a per-chapter basis eg. "##CHAPTER-AUTHORS##"
3.2 Objavi Features
3.2.1 Book-Formatted PDF Output
Status: High Priority, Implemented
Function: the server side creation of Book Formatted PDF is a pivotal feature. This is managed by Objavi which runs as a separate service. The book formatted PDF supports Unicode, bi-directional text, and reverse binding for printing right-to-left texts on a left-to-right press and vice versa. The formatting engine outputs customisable sizes including split column PDF suitable for printing on large scale newsprint.
Interface: This feature is managed by Objavi, an API is functional and feature rich but not well documented at present. Objavi also presents a web interface for those wanting more nuanced control (see http://objavi.flossmanuals.net/).
3.2.2 CSS Book Design
Status: High Priority, Implemented
Function: The default PDF rendering engine for Booki is now Webkit and will eventually be Mozilla Firefox hence there is full CSS support for creating book-formatted PDF in Booki. This changes the language of design from Indesign to CSS - which means any web native can control the design of the book.
3.2.3 Export Formats
Status: High Priority, Implemented
Function: Users also can export to self contained templated (tar.gz) HTML, to .odt (OpenOffice rich text format), epub, and screen readable PDF. Other XML output options can be developed as required.
I guess I can never claim to not having project management experience again. Darn it.
Some of my projects. As you can see, partially complete. Will add more and then make this a static page.
Publishing-related
Collaborative Knowledge Foundation
Current
The Collaborative Knowledge Foundation’s mission is to evolve how scholarship is created, produced and reported. CKF is building open source solutions in scholarly knowledge production that foster collaboration, integrity and speed.
CKF envisions a new research communication ecosystem that gives rise to wholly unique channels for research output.
CKF was founded in October 2015 with support from the Shuttleworth Foundation.
Shuttleworth Foundation
Current
I have just been awarded a Shuttleworth Foundation Fellowship. I’m deeply honoured to have been selected. I was awarded a second year of Shuttleworth Fellowship for my work on reformulating how knowledge is produced.
Recent Presentations
The Future of Text
Google Headquarters in Silicon Valley, Aug 2016 http://www.thefutureoftext.org/
Organised by friends and followers of Douglas Englebart, Adam was invited to present on collaboration and book production.
Association of Learned and Professional Society Publishers
London, Sept 2016 http://www.alpsp.org/2016-Programme
Adam was invited to present at the annual ALPSP conference about ways that Open Source could change publishing.
International Society of Managing & Technical Editors
2008 – present, New Zealand http://www.booksprints.net/
Book Sprints is a methodology and a company I founded to rapidly produce books.
Nov 2016: transitioned from founder and CEO to the board. I appointed Barbara Rühling as CEO.
A Book Sprint is a collaborative process where a book is produced from the ground up in just five days. But even more important, this collaborative process captures the knowledge of a group of subject-matter experts in a manner that would be nearly impossible using traditional methods. The result at the end of the Book Sprint is a high-quality finished book in digital and print-ready formats, ready for distribution.
Book Sprints Ltd, is a team of facilitators, book-production professionals, and illustrators specialised in Book Sprint facilitation and rapid book production. Our organisation developed the original methodology and has refined it since 2008 through the facilitation of more than 100 Book Sprints. Topics have ranged from corporate documentation to industry guides, government policies, technical documentation, white papers, academic research papers, and activist manuals.
Book Sprints clients include Cisco, PLOS, F5, the World Bank, USAID, African Development Bank, Open Oil, Liturgical Press, Ausburg Fortress, Cryptoparty, OpenStack, European Commission, JISC CETIS, UNECA, Mozilla, IDEA, Engine Room, Heidy Collective, Transmediale, Google… to name a few.
"If Book Sprints did not exist, we would be forced to invent them, so powerful is the knowledge production paradigm."
--Allen Gunn, Aspiration
"Book Sprints get more brilliant work out of bright people in 1 week than most project can evoke across many months."
--Loy Evans, Cisco
"Writing a book through a Book Sprint turned out to be efficient, thorough and enjoyable; I can’t imagine a better outcome."
--Phil Barker, JISC CETIS
Aperta
2013 – July 2015. Public Libary of Science, San Francisco
In 2013, I designed a platform for the Public Library of Science (PLOS), originally called Tahi but renamed to Aperta. In 2014 I was asked to lead a team to build the platform. I led the 15 strong team to the production-ready 1.0 release of this multi-million dollar project to completion, on time and under budget in June 2015.
Aperta is an entire submission and peer review platform for multiple scientific journals housed within the single instance. The entire system is designed to be highly collaborative and concurrent. The platform includes a manuscript production interface, HTML and LaTeX document editing support, Word ingestion, a workflow management system, task management interfaces, admin interfaces, reports, and user dashboards. The platform was built in Ember-CLI, Rails, implements a highly customised Wikimedia Foundations Visual Editor, and uses Slanger for concurrency. It is an HTML-first system, has many innovative new approaches to journal systems, and solved many long-standing problems in this space. The project also involved a separate codebase named iHat that provides Aperta with an API service for queue-managed file conversions.
"At its core, this new PLOS editorial environment brings simplicity to the submission and peer review process by providing advanced task-management technology and a vastly improved user interface, which will enhance the publishing experience for our community of authors, editors, and reviewers."
http://blogs.plos.org/plos/2015/07/publishing-initiatives-at-plos-a-look-back-and-a-look-ahead/
NB: I only work on Open Source systems. The sources are not yet available for this project.
PubSweet
2012 – present
PubSweet is a platform designed to assist the rapid production of books in Book Sprints. The platform is very simple to use, with very little overhead for new users. The system provides dashboards, publishing consoles, card-based workflow management (task manager), discussions, data visualisations of contributions, a dynamic table of content management, and support for multiple chapter types. PubSweet can produce EPUB and leverages book.js (see below) to produce print-ready PDF (paginated in the browser). PubSweet is written in PHP, using Node on the backend, and CKEditor as the content editor.
Lexicon
2012
Lexicon is a platform produced for the United Nations Development Project to collaboratively produce a tri-lingual (Arabic, French, English) lexicon of electoral terms for distribution in Arabic regions. Lexicon provided concurrent editing for chapters with multiple terms, sorting by language, discussion forums and voting. Lexicon was written quickly in php with Node.
2012 book.js is a Javascript library that you can use to turn a web page into a PDF formatted for printing as a book. Take a web page, add the JavaScript, and you will see the page transformed into a paginated book complete with page breaks, margins, page numbers, table of contents, front matter, headers etc. When you print that page you have a book-formatted PDF ready to print.
book.js has given inspiration to a number of other JS pagination engines. See Vivliostyle, bookJS Polyfil, Pagination.js, simplePagination.js, and CaSSiuS.
Booktype
2010 / 2012 Booktype is a book production platform. I brought this platform to Sourcefabric (Berlin) as ‘Booki’ in 2012. Booki was started in 2010. Booktype is written in Python (Django).
“Booktype resolves challenging issues in collaborative knowledge production resulting in high quality print and ebooks.” – Erik Möller, deputy director, Wikimedia Foundation
Google Summer of Docs
2011, 2012, 2013
The GSoC Doc Camp was an annual event over three years. It was a place for documenters to meet, work on documentation, and share their documentation experiences. The camp improved free documentation materials and skills in GSoC projects and helped form the identity of the emergent free-documentation sector.
The Doc Camp consisted of 2 major components – an unconference and 3-5 short form Book Sprints to produce ‘Quick Start’ guides for specific GSoC projects.
Each Quick Start Sprint brought together 5-8 individuals to produce a book on a specific GSoC project. The Quick Start books were launched at the opening party for the GSoC Mentors’ Summit immediately following the event.
Bookimobile
2011
The Bookimobile was a a mobile print lab in a van – essentially a van that contained all the equipment necessary to create perfect bound books. It was designed to take the ideas of Booki to people and make real books that have been created in Booki. The first Bookimobile was based on the Internet Archives Book Mobile and we took it to several book fairs and events throughout Europe. It was sponsored by Mozilla, CiviCRM, Archive.org, Francophonie.org, Google Summer of Code, and iCommons.
Objavi
2008
Objavi is an API-software service originally written for Twiki Book (see below) but also serviced Booki and later Booktype. Objavi converts books from their native HTML into PDF for printing. It also handled other file conversions (eg HTML to ODT, HTML to EPUB etc). I later produced a similar API-based conversion software for PLOS known as iHat. Objavi is written in Python.
TWiki Book
2006
TWiki Book didn’t have a real project name at the time. The project was the first publishing system I built. TWiki Books was created solely to meet the needs of FLOSS Manuals (see below) and it was built on top of TWiki, a Perl-based wiki. TWiki Book included book remixing features, side by side translation, table of contents building, publishing interfaces (I actually wrote a separate php-based system to manage this), edit notifications, versioning, diffs, live chats and many other features. It was a good system but reasonably difficult to extend and maintain since it re-purposed an existing wiki software (hence my approach to building purpose-built book production systems after this point).
FLOSS Manuals
2006
FLOSS Manuals was the project I founded in 2006 that got me started on this whole publishing thing. FM was, and is still, an active community of volunteers that creates free manuals about free software. There is now a foundation and several language communities (notably French and English). The contributors include designers, readers, writers, illustrators, free software fans, editors, artists, software developers, activists, and many others. Anyone can contribute to a manual – to fix a spelling mistake, add a more detailed explanation, write a new chapter, or start a whole new manual on a topic. The aim was produce high quality free works and we succeeded – creating many fantastic manuals in over 30 languages (and still growing).
“Introduction to the Command Line” is at least as clear, complete, and accurate as any I’ve read or written. But while there are countless correct reference works on the subject, FLOSS’s book speaks to an audience of absolute beginners more effectively, and is ultimately more useful, than any other I have seen.”
-- Benjamin Mako Hill, Wikimedia Foundation Advisory Board, Free Software Foundation Board
Presentations about publishing
I am asked to talk about publishing from time to time. The following are some links to some of those presentations.
Choosing a document network
August 2015, Vancouver, Public Knowledge Project
Open Access and Open Standards Oct 2014, San Francisco, Books in Browsers
Books are Evil May 2014, Rotterdam, Off the Press
Regional Lexicon Project May 2014, San Francisco, I Annotate
Changing the Culture of Learning
May 2013, San Francisco, I Annotate
The Death of the Reader
Oct 2013, San Francisco, Books in Browsers
A Web Page is a Book May 2012, Berlin, re:publica
Writings
I have been writing about publishing here and there. Since last year these efforts have been focused on this site. The following are some links to some of my other works:
Fantasies of the Library : After the Proprietary Model
Interview with me about the future models for publishing, published by k-verlag (Berlin).
Radar O’Reilly posts
When Paper Fails
What happens when books, ownership, authority and authors are all challenged by a network.
2008, Quarantine Island, New Zealand
This project was actually called ‘Intertidal’ but I like the name Seaweed better. Douglas Bagnall and I created a one-day community project to discover a new species of seaweed. We hosted this on Quaratine Island in the Dunedin Harbour and invited anyone to come work with us and a marine biologist from the local research center to search for a new species. The project was a community project and a reflection on the notions of species as an out-moded idea, and on taxonomy as a dying art. About 50 or 60 people – individuals, groups, and families – came out on the free boat (provided by the local sea scouts) and hiked across the island to participate on a coldish Dunedin day to search for and document seaweed. We possibly discovered a new species.
throwing into focus the ever-present potential for new knowledge. Drawing upon 19th century methods of species discovery, involving collecting, looking and drawing, their work formed questions around what we don't know.
Geek-o-system
2008, Christchurch, New Zealand
Julian Priest, Dave Merritt and I drove about a tonne of old electronics 700km or so in an old landrover (top speed 35km/hr) from Daves warehouse in Wanganui to an art gallery in Christchurch, New Zealand. In the gallery, we served up the old electronics as a participatory art project and invited anyone to come and build new objects from the old. It took 3 days to get there. It was an adventure.
A Geekosystem was a participatory workshop based on a redundant technology collection created by David Merritt. Items were selected from the collection and packed into a Landrover and driven to The Physics Room in Christchurch. A call for participation was issued by The Physics Room and a group of geeks gathered to re-configure the technology into artworks. A workshop space was created and plinths were placed at once end of the gallery and populated with artworks made from the e-waste. The workshop was open to the public and continually added to during the duration of the show. Old technology books were formed into a library. Proprietary software manuals were shredded and mixed with coffee grounds. This was mulched into soil and silver beet seedlings were successfully germniated in floppy disk trays.
A Geekosystem was shown first at the Physics Room in Christchurch in 2008 and then at The Green Bench during the Whanganui Open studio week in 2008. The Geekosystem garden was transferred to a permanent location and produced vegetables for a number of years.
Paper Cup Telephone Network
2006, Exhibited at the Exploratorium in San Francisco, Zero One Festival in San Jose, and many other venues.
This was a project I made with Matthew Biederman and Lotte Meijer. The Paper Cup Telephone Network (PCTN) was a free communication system and comment on how ‘simplicity’ in technical systems is trickery, and problematising the corporatisation and ever increasing individualisation of modern communications.
The PCTN was a network of paper cup telephones. Just like the games played by children, anyone could put a PCTN cup to their ear to listen, or to their mouth to speak. However, the difference between the PCTN and the original game is that the “string” is connected to the World Wide Web where your voice is streamed to all the cups on the network carrying it, blocks or even miles or a continent away. We built the entire system from free software telephony systems (asterisk and SIP phones), open and standards-based telephony protocols, cups, and string.
As simple as it was, it remains the most difficult technical project I have ever undertaken.
Wifio
2006, exhibited at the Waves exhibition in Riga, Latvia
Wifio was a project I did with Lotte Meijer and Aleksandar Erkalovic. Wifio was a comment on the naivety in which we broadcast our personal information. It was a hardware UI and software that allowed anyone to tune into the World Wide Web wifi traffic. If someone near you was browsing the web on a wifi network, you could simply tune in with Wifio by selecting the right channel and tuning into their IP address.
…but don’t worry, you don’t need to know what their “IP Address” is, in fact you don’t even need to know what an IP address is! Just move the dial until you hear their emails or what they are saying in chatrooms.
I was proud when Julian Oliver (an old buddy from NZ) referenced this project as inspiration for one of his works.
Sound Elevator
2007
r a d i o q u a l i a (see below) were commissioned to make a new work for Forte di Bard in Valle d’Aosta in Italy for “Cima alle stelle (Stars)”, a large exhibition showing historical works by major masters like Durer, Tintoretto and Guercino; contemporary artists such as Pierre Huygue, Olafur Eliasson and others; and astronomical instruments and writings by Copernicus, Galileo, Kepler, Newton and Einstein.
We made a new site-specific sound installation inside two of the glass elevators which take visitors from the arrival area of Forte di Bard, to the gallery levels. Much of the elevator travel is external to the Forte (pictured below). Sound Elevator consisted of two linked sound environments inside the elevators. As the elevators ascended to the exhibitions halls, visitors experienced an auditory journey from the local celestial environment to the edges of the Universe. In the first elevator, visitors sonically travelled through the Earth’s ionosphere and magnetosphere, hearing our closest star, the Sun, interacting with our planetary atmosphere. The upward and outward journey continued in the second elevator, with sounds from our planetary neighbours, the sonic echo of distant stars, and finally the sound of the Big Bang itself.
I-TASC
2006/2007 Antarctica
I did a 2-month residency in Antarctica at SANAE (South African Research Base) as part of I-TASC, ultimately a failed network of individuals and organisations working collaboratively in the fields of art, engineering, science and technology on the interdisciplinary development and tactical deployment of renewable energy, waste recycling systems, sustainable architecture and open-format, open-source media. But it was still a great experience.
The coolest thing about it, was the 2 weeks each way on the beautiful icebreaker the SA Agulhas (now decommissioned). I kept some diary pages on the Interpolar site. I also did a few other projects while there including Polar Radio (see below).
The worst thing about it was that we shouldn’t have been there. There is no need for anyone to be in Antarctica. Most of the ‘science’ projects are strategic positioning for a land grab when the time comes. Some science might be justifiable… but arts projects?
Leaving Antarctica I cried my eyes out. It was just too much for me to deal with. Too amazing. After Antarctica, I gave up the art world. I couldn’t think of anything else the art world could do for me.
It was a conflicted but beautiful experience.
Polar Radio
2006/2007, Antartica
Polar Radio was a community radio project initiated by I-TASC and
r a d i o q u a l i a. The first prototype station began FM broadcasts on 29 December 2006 in the Dronning Maud Land sector of Antarctica, where South Africa maintains their base, SANAE IV. It was Antarctica’s first artist-run radio station. It was the first step towards establishing a permanent polar radio presence in Antarctica, which may eventually broadcast in between geographically dispersed Antarctic bases.
But y’know…I wish I hadn’t done it. When I first got to Antarctica I turned on a radio and went through many many frequencies… and I heard nothing… that was amazing. Where else in the world can you nothear anything on your radio? I then went ahead and polluted the spectrum. Darn. I regret it.
Polar Radio was part of a series of projects run by I-TASC – the Interpolar Transnational Art Science Constellation.
Mobicast
2005, Transiberian Express
Capturing the Moving Mind was a conference on board the Trans-Siberian train. It was about new forms of movement and control, war and economy, in the current situation. 50 international researchers, artists and activists participating in the mobile conference formed a mobile production unit aboard the train. For the audiovisual streams, Luka Princic and I developed a free software ‘mobicasting’ platform which enabled mobile transmission of material on the web from mobile phones on the train. Mobicast was initially developed during a residency I had at MAMA Media Lab (Zagreb, Croatia).
It was a great project but really really fragile. The tech of the time was not up to it. Mostly it ran on Puredata and some obscure bits of code from here and there. Still it worked. Best moments were hanging out on the train laughing at people trying to be ‘artists’ in real time… huh? …and getting sardonic with Dr Gillian Fuller – the world’s best queue hacker. Watching the train wind around the Gobi desert… also kinda cool.
mobicast was initially developed to overcome the problem of delivering live video from a moving train to the internet. Traditionally this is the domain of OB (Outside Broadcast) technologies or expensive vehicular satellite uplink hardware. However mobile phones are now very capable remote broadcast environments. Many modern phones record images, video, audio and allow the editing and transfer of these media through wireless data networks (eg. GPRS) with almost global coverage. The quality of these recorded media have generally been considered 'low-fi' but fidelity is increasing and importantly, the expectations of networked media are becoming more appropriate. Once upon a time there was a mythic "broadcast quality" threshold all media had to pass before being accepted by broadcast organisations and (theoretically) audiences. However, now there are active calls for content generated by "on the spot" accidental observers by large scale media organisations. The tide and scale of remote media is changing. The nature of experimental media on this type of platform is the intentional playground of mobicasting. With this emerging new type of media witness cultural forms are also emerging. Multiple networked media phones is in itself a platform for collaborative cultural development and opens interesting doors for experimental media.
2001-2004, International
For many years I had a wonderful mentor – Tetsuo Kogawa. He is the father of MiniFM. I saw Tetsuo build a mini FM transmitter at the Next Five Minutes festival in Amsterdam. Sometime after that, I asked him if he would teach me how to make them too, and he very generously spent a good deal of time making sure I understood the ins-and-outs of the process. Together we designed a workshop and Tetsuo worked out even simpler ways to build the transmitters. For many years I travelled the world leading transmitter-building workshops and often Tetsuo would stream in from his studio in Tokyo to talk about the idea and give a quick demonstration before we started building.
Later Tetsuo and I created a project called SilentTV which was the same idea but using simple elements to broadcast TV.
I’m forever grateful to Tetsuo for his kindness and mentorship.
re:Play
November 2003, South Africa re:Play explored the world of the computer game. It featured an exhibition of artists’ computer games by Andy Deck, Josh On + Futurefarmers, Mongrel, Natalie Bookchin, the escapefromwoomera collective and Max Barry, and a programme of workshops and lectures. re:Play was a collaboration between the Institute for Contemporary Art, Cape Town and r a d i o q u a l i a. It launched at L/B’s – The Lounge at Jo’Burg Bar in central Cape Town, South Africa, and went on to be exhibited at Artspace and the Physics Room in New Zealand.
The games in the exhibition were not typical computer games. While all of them encouraged play, and involved a gaming objective, unlike regular computer games, they had a strong political dimension and explored how play, interaction and competition can be utilised in an artistic context.
The re:Play education programme included talks and workshops lead by Graham Harwood of Mongrel and r a d i o q u a l i a at Cape Town High School, Fezeka Senior Secondary School in Gugulethu; the Alexandra Renewal Project, Johannesburg and at Wits School of Arts, University of the Witwatersrand, Johannesburg.
Free Radio Linux
2002, The World
Another project that got a lot of attention for r a d i o q u a l i a, most notably through being exhibited at the New Museum in NYC, but it also at Banff and other places. I loved this project because it brought together several threads.
Formally, Free Radio Linux was an online and on-air radio station. The sound transmission was a computerised reading of the entire source code used to create the Linux Kernel, the basis of all distributions of Linux.
Each line of code was read by an automated computer voice – a speech.bot
utility I built for the work. The speech.bot’s output was encoded
into an audio stream, using the early open source audio codec, Ogg Vorbis, and was broadcast live on the internet. FM, AM and Shortwave radio stations from around the world also relayed the audio stream on various occasions.
The Linux kernel at that time had 4,141,432 millions lines of code. Reading the entire kernel took an estimated 14253.43 hours, or 593.89 days.
Listeners tracked the progress of Free Radio Linux by listening to the
audio stream, or checking the text-based progress field in the ./listen
section of the website (which is no longer up)…
Essentially this was all about how free radio and free software were wierdly the same. If you ever worked with free radio geeks, you will know they are nerdy technophiles who believe in the purity of what they are doing. Very much the same as Open Source geeks at the time. Most were interested in the tech and the political ideal of the respective mediums (radio and software). So, FRL was a comment on this. It was also a comment on how free radio was, ironically, very difficult to achieve on the internet unless serious attention was made to developing free codecs. But also FRL had two other elements going for it. The first was to (again) poke fun at the ridiculous hyperbole that surrounded the open source movement. People were expounding this ‘amazing new phenomenon’ and extrapolating how it would change the world (much as they did about wikis a short time after) when they had never come into contact with code or geeks. So this was an attempt to expose those people to the code…or what it sounded like. But also, at the time there was a lot of early talk about how to preserve digital media (a problem still not solved) and radio waves apparently never die… so by broadcasting the Linux kernel into space we were preserving it on the oldest medium ever, forever. Hehe…
I did, however, feel very sorry for the attendants at the New Museum who had to work 8-hour shifts listening to “one dollar sign dollar sign comma hatch four new line seven two dollar sign dollar sign…”
Thing FM
2002, New York City
This was, in theory, a radio network but in reality, just a few transmitters got installed. Still, it was fun. Thing FM was based in NYC and built during a residency I did at the Thing in NYC. The same week that the Yes Men came into the office to film their ‘shit burger’ stunt. They came into the Thing and asked who wanted to go and I didn’t go! doh! Anyway, we built the network using internet audio (via wireless and wired connections) and miniFM. Each of the transmitters was about 0.1 W output and sourced their audio live from the internet using the Frequency Clock scheduling system I had built earlier.
This partly adopts the ethic of micro-radio as founded by Tetsuo Kogawa, where many low powered FM transmitters are coupled to create an effective broadcasting entity that ‘falls beneath the radar’ of the communication authorities. fm.thing.net combined this ethic with that of net.radio which was a relatively new phenomenon focusing on the use of the internet as a carrier signal, best illustrated by the practices of the Xchange network. By combining the net.radio and micro-radio we hoped to build an efficient radio network in New York that used the internet as a primary carrier of the audio for re-broadcasting on legal or almost legal microFM broadcasts.
Hanging with Ted Byfield and Jan Gerber was a highlight of this experience. Wolfgang Strauss was also pretty fun but I was so intimidated by him. He was just so cool. Also sharing a tenement apartment in Ludlow Street with 3 people (bath in the kitchen) was pretty fun.
Radio Astronomy
2001 Radio Astronomy was an art and science project which broadcasts sounds intercepted from space, live on the internet and on the airwaves. The project was a collaboration between r a d i o q u a l i a, and radio telescopes located throughout the world. Together we were creating ‘radio astronomy’ in the literal sense – a radio station devoted to broadcasting audio from our cosmos.
Radio Astronomy had three parts:
a sound installation
a live on-air radio transmission
a live online radio broadcast
Listeners heard the acoustic output of radio telescopes live. The content of the live transmission depended on the objects being observed by partner telescopes. On any given occasion, listeners may have heard the planet Jupiter and its interaction with its moons, radiation from the Sun, activity from far-off pulsars or other astronomical phenomena. Honor from rQ later made a TED Talk about it.
Dino, drummer from HDU, did the website design…thats gotta rate…
RT32
2001, Latvia
In 2001 I had the good fortune to be part of the Acoustic.Space.Lab project which started a long love affair with the RT32 radio telescope. Formerly a cold war device, this telescope was liberated when the Russian Army pulled out of Latvia. I worked with this telescope as an artistic device and with the generous scientists for many years after. The doco clip below introduces the explorations of the international Acoustic Space Lab Symposium which took place on the site of RT-32 in 2001.
Highlights of this period in Latvia included being evicted by Russian builders, getting a hernia, and being amazed Marc Tuters survived eating so many dodgy looking mushrooms he found in the forest.
Open Sauces
May 2001, Scotland and also later…
I have come to realise there is just too much stuff I have tinkered with to comment on. Open Sauces falls into that bucket. Google tells me this was 2001. Essentially I got sick of all the Open Source blah blah of the time.. everything was suffixed by OPEN and it got very tiring (Open Gov, Open Hardware, Open Society…). No critical reflection on the fact that geek methods are geek methods and they are not transportable – AND – OPEN processes, methods etc existed well before geeks came along and inherited the word. No geek invented openness. I’m still tired of this I have to say…still…. I created Open Sauces which was an open database of recipes… anyone that did a residency could add their favourite recipe and you could just tick all the ingredients you have in your fridge and get a recipe to suit… doesn’t sound too revolutionary but at the time this sort of thing didn’t exist. It was a comment on this abuse of the use of the word ‘open’ and how cooking way preceded sharing of ‘code’ / ‘instructions’ etc… and also how food is probably the most important part of any collaborative project, whereas unsocial nerdy talk is optional. Later Fo.am in Brussels were inspired by the idea and started an Open Sauces theme.
net.congestion
2000, Amsterdam
I’m particularly proud of this project. It came about when I was a very naive newly arrived resident of Amsterdam. I suggested to Geert Lovink this idea for a festival and he said to speak to Erik Kluitenberg. Both huge legends in my mind you understand… I mustered the courage up to suggest it to Erik who was a cultural curator at De Balie at the time. He said he would think about it and I thought I wasn’t very convincing. A week later he called me up and said let’s do it! Whoot!
The festival was held in Amsterdam in October 2000. Net.congestion was an intensive three-day celebration and critique of the new cultures that have arisen from all forms of micro-, narrow- and broad- casting via the internet, now collectively known as streaming media.
The event covered most of the interesting ground of the time for streaming media, from the transformation of issues surrounding intellectual property to the uses of streaming as a mobilisation tool for global resistance through to the more rarefied questions of aesthetics and how narratives are transformed when embedded in networks. The overwhelming experience of many visitors to Net.congestion was a sense of tools, networks and sensibilities being re-purposed, returning us, again and again, to a primary experience of the net as a social space.
Net.congestion occurred just months before dot.com bubble burst, exploding the ‘new economy’ and ‘the long boom’ with its fantasies of a world in which the economic laws of gravity had been repealed. There is no doubt that if the same event were to be held now, the atmosphere would be markedly different. It is not that Net.congestion was an industry event which depended on the hype for its existence, as the very title indicates that we mixed a healthy dose of skepticism with our festivities. But none of us, however critical, can entirely escape the zeitgeist and there is no doubt that in those brief heady days Warhol’s aphorism was re-written; we could all dream of becoming billionaires, if only for 15 minutes. A strange historical phase when (particularly for anyone involved in streaming media) the normally fixed boundaries between business, art, technology, science fantasy and just plain bullshit temporarily blurred to create a moment of unique cultural hysteria. In that sense our timing was perfect.
The Theory Machine
2000
In an attempt to make theorists a little more funky, I made a software they could use to put their brainy thoughts to glitchy syncopation. It was mainly used by Eric Kluitenberg including one memorable performance at Club Otok in Dubrovnik.
HelpB92
1999, Amsterdam
I helped found an organisation during the Nato bombing of Serbia and Kosovo in 1999. The international support campaign for independent media in Yugoslavia, including the famous Radio B92 media centre, in operation between March and July 1999. We did some pretty cool things but mostly I was very happy to be involved in what must have been one of the web’s early large-scale activist campaigns. It was also the start of my longish relationship with Amsterdam as XS4ALL offered me a job and I stayed for a few years. I still have a bike there somewhere.
What was tricky, though, is that I agreed to go to Skopje to assist an Albanian refugee radio station (Radio 21). It was kinda nerve wracking. There were literally bombs set to explode to take out as many Albanians as possible. Some kids lost their legs across the street from where I was working. I was a milk and cookies boy from NZ.. what was I doing here? Still, I stuck it out and we managed to set up quite an innovative way of getting radio transmissions out of the refugee camps to Radio Netherlands Shortwave.. .I’ll write that up when I get time.
The Frequency Clock
1998 – 2004 or so, The World
This was one of the earliest r a d i o q u a l i a projects and how I learned to program. To understand this project you have to understand the dark ages of the internet when video and audio hardly existed. Essentially we built a media scheduling system that allowed you to build archives of live and pre-recorded content, tag them, and then schedule them. All built in JavaScript… remembering these were these days when Javascript was very rudimentary.
The Frequency Clock was originally conceived as a mechanism to control FM transmitters over the internet. In essence it was a networked timetabling system, connecting globally dispersed FM transmitters so they could broadcast the same internet audio simultaneously. The original player was a popup window but we also built desktop apps to do the same thing using VisualBasic (Win) and RealBasic (Mac). All open source.
However… then we realised that video could also work… and we used it to control community TV channels in Amsterdam and Linz and we also controlled giant video billboards in Estonia and a whole lot of other things. It was exibited a lot, most notably at the Walker when Steve Dietz was still there. We even installed a transmitter in the roof of De Waag! It was a remarkable experiment for its time. Yes, yes, pre-Napster and YouTube and all those other toys… while writing this I found some kind of prototype online.
Sound Performances
1996 – 2008, the world.
Performing solo as ‘eset’ and with Honor Harger as r a d i o q u a l i a I did a lot of sound performances, most using sounds from space and either live performances in real space or on radio. Some stuff still exists online: https://soundcloud.com/radioqualia
Or eg:
r a d i o q u a l i a
This was the project that liberated me from the south and the reason I moved to Europe with no money and no return ticket. My plan was to make coffee and do some arty stuff in London. Thankfully, Nato bombed Serbia (hoho) and everything changed.
What I really loved about this time, was that I felt part of a lovely international community of artists. We used to travel around and bump into each other in various crazy places. This group included people like Marko Pelijhan, Heath Bunting, Rachel Baker, James Stevens, Luka Frelih, the Mama crew, Lev Manovich, Steven Kovats, Matthew Beiderman, Giovanni D’Angelo, Zita Joyce, Adam Willetts, Rasa Smits, Raitis Smits and so many many others…it was an awesome time.
r a d i o q u a l i a was an artist project that consisted of myself and Honor Harger. I have described some of our exhibitions and performance projects above, and listed some below. There were many more.
In August 2004, r a d i o q u a l i a was awarded a UNESCO Digital Art Prize for the project Radio Astronomy. In September 2003, we were awarded the Leonardo-@rt Outsiders 2003 New Horizons Prize together with the participants of the Open Sky installation at the @rt Outsiders exhibition at the Museum of European Photography in Paris.
Selected r a d i o q u a l i a exhibitions and performances:
Lecture & performance at the Centre Pompidou, Paris, France
Work: Sonifying Space, as part of the Space Art conference
Exhibition at the New Museum of Contemporary Art, New York, USA
Work: Free Radio Linux, as part of the OpenSourceArt_Hack exhibition
Exhibition at the NTT InterCommunication Centre, Tokyo, Japan
Work: Radio Astronomy, as part of open nature, a show curated by Yukiko Shikata
Online exhibition / commission / installation at Gallery 9, Walker Art Centre, USA
Work: Free Radio Linux
Exhibition at Arsenals Exhibition Hall, Riga, Latvia
Work: solar listening_stations, part of WAVES
Exhibition at HMKV, Dortmund, Germany
Work: solar listening_stations, part of Solar Radio Station
Exhibition at the Walter Philips Gallery, Banff, Canada
Work: Free Radio Linux, as part of The Art Formerly Known As New Media
Exhibition at Centre d’Art Santa Monica, Barcelona, Spain
Work: Radio Astronomy, as part of Sonar 2005
Performance at Tesla, Berlin, Germany
Work: from polar radio to solar wind
Performance, La Batie Festival, Geneva, Switzerland
Work: signals as part of signal-sever
Exhibition at Ars Electronica, Linz
Work: Radio Astronomy
Exhibition at ISEA 2004, Helsinki, Finland
Work: Radio Astronomy
Symposium & Performance, Ventspils International Radio Astronomy Centre, Latvia
Work: Acoustic Space: RT32: Orchestrating the Solar System
Broadcast on Radio New Zealand
Work: Revolutions Per Minute 1: Frequency Shifting Paradigms in Broadcast Audio
Broadcast on Radio New Zealand
Work: Revolutions Per Minute 2: Little Star
Exhibition at Small Gallery, Los Angeles, USA
Work: comma.data.space: 11 Ghz
Performance at the Moving Image Centre in Auckland, New Zealand
Work: comma.data.return :: 56:30 – 21:1
Performance at Version festival, Auckland, New Zealand
Work: listening_stations v0.3: langmuir waves
Exhibition at the Physics Room, Christchurch, New Zealand
Work: re:Play
Exhibition at Artspace in Auckland, New Zealand
Work: re:Play
Exhibition & education programme, South Africa
Work: re:Play
Exhibition at the Reg Vardy Gallery, Sunderland, UK
Work: Free Radio Linux, as part of the Art for Networks exhibition
Exhibition at Museum of European Photography/ Maison Europeenne de la Photographie, Paris, France
Work: listening_stations, as part of @rt Outsiders exhibition
Exhibition at the Physics Room, Christchurch, New Zealand
Work: data.spac.ereturn, as part of the Audible New Frontiers exhibition
Locative media Residency at K2, Karosta, Latvia
Work: Locative Media
Exhibition at Turnpike Galleries, Leigh, UK
Work: Free Radio Linux, as part of the Art for Networks exhibition
Exhibition at Fruitmarket Galleries, Edinburgh, UK
Work: Free Radio Linux, as part of the Art for Networks exhibition
Radio show on Resonance 104.4FM, London, UK
Work: r a d i o q u a l i a on resonanceFM
Exhibition at the Generali Foundation, Vienna, Austria
Work: listening_stations as part of the Geography and the Politics of Mobility exhibition
Exhibition at Chapter, Cardiff, UK
Work: Free Radio Linux, as part of the Art for Networks exhibition
Performance & Broadcast, Ars Electronica, Linz Austria
Work: Radiotopia @ Ars Electronica
Radio Broadcasts on Austrian National Radio, Vienna, Austria
Work: i s o l
Exhibition at CCCB, Barcelona, Spain
Work: frequency clock – gallery installation – [sNr v.0.1]
Sonar 2001, Barcelona, Spain
Action & Broadcast, Ars Electronica, Linz, Austria
Work: Take Over Cultural Channel
Performance, Residency & Symposium at, Ventspils International Radio Astronomy Centre, Latvia
Work: Acoustic Space-Lab
Exhibition at Video Positive, Liverpool, UK
Work: Frequency Clock – gallery installation – [ vp00 v.0.0.3 ]
Workshop & Performance, Adelaide Festival of the Arts, Adelaide, Australia
Work: Closing the Loop 2000
Seminar & Performance at Lux Centre, London, UK
Work: Tuning the Net
Performance at the Stockton Festival, Stockton, UK
Work: transitions & undercurrents part of live-stock
Exhibition & Performance at OK Centrum, Ars Electronica, Linz, Austria
Work: pso.Net, as part of Sound Drifting
Exhibition at Experimental Art Foundation, Adelaide, Australia
Work: Frequency Clock – gallery installation – [ eaf v.0.0.2 ]
Exhibition at Experimental Art Foundation, Adelaide, Australia
Work: Illata
Exhibition at Contemporary Art Centre of South Australia, Adelaide, Australia
Work: e Q
Performance at LADA98 Festival, Rimini, Italy
Work: we are alive and well but terribly uncommunicative
Exhibition, Ars Electronica, Linz, Austria
Work: Frequency Clock – gallery installation – [ aec98 v.0.0.1 beta ]
Performance, Ars Electronica, Linz, Austria
Work: 56h LIVE!: Acoustic Space
Exhibition at Bregenz Festival, Bregenz, Austria
Work: gl^tch.bot
Performance and presentation at net.radio.days 98, Berlin, Germany
Work: self.e x t r a c t i n g.radio (.ser)
Online Project
Work: self.e x t r a c t i n g.radio (.ser)
Exhibition at the Machida City Museum of Graphic Arts, Tokyo, Japan
Work: The Qualia Dial
Exhibition at Fabrica New Media Art Institution, Italy
Work: Balance
Most of the book production platforms in circulation have very little workflow tools to speak of. This is not necessarily a bad thing. A platform that is ‘just an editing environment’ is still pretty powerful. If you do need tools to assist with workflow, then in situations where a small group know each other well they can use email or, if in real space, Post-it notes or paper to track what needs to be done next. In many cases, a live chat in the interface, or integrated topic-based forum, will be enough to satisfy many workflow needs, and in other cases the platform can be augmented by external systems such as wikis, online spreadsheets, content management systems and other tools to meet particular requirements.
However, there are a number of situations where these ‘solutions’ become unsatisfactory. This is especially true for organsiations which have a large number of people involved in processing content, or which have sophisticated content-processing needs (such as book publishers).
Before going too much further, let me clarify what “workflow tools” are. In the broadest sense, they are tools that help you to know what needs to be done, and when it needs to be done by. Using this very broad definition, we can see that mechanisms such as discussion forums and live chats are workflow tools. By chatting with colleagues through a live chat or forum, you can work out what needs to be done next, or get a ‘notification’ (a shout out) that it needs to be done now… From there, systems can evolve into complex technical environments which are either relatively open-ended (such as Trello) or relatively closed, such as hard-coded workflow pipelines.
The first book production system I built for FLOSS Manuals was ‘built’ on top of Twiki in 2006-2007, had some basic workflow tools, namely:
a basic live chat
a dropdown status-selector for marking chapter statuses (needs content, needs images, finished, and so on)
notifications in the table of contents when someone is editing a chapter
a mailing list where efforts could be coordinated
These tools were simple and effective and served us well for a number of years. I also incorporated similar mechanisms into Booktype and PubSweet. In addition, when we used these platforms for Book Sprints, lots of whiteboard scribbles and Post-its were utilised.
In a Book Sprint, notably, the facilitator is the main coordinating workflow mechanism. I point that out because it is important to understand that workflow tools can include humans – often the easiest way to know what needs to be done and when is to be done by, is to get someone else to tell you.
And let’s not forget that human factor! We are living at a time when we tend to want to programmatically solve problems with overly prescriptive technical systems. But sometimes underdetermining the technical systems is the right way to go.
I first tried pushing past these basic software workflow tools with Booktype – a book production system I founded, now housed with Sourcefabric. I leveraged the kanban idea of multiple columns (phases) populated by ‘todo’ items to build the equivalent of a digital kanban system, making the first simple prototype in a demo for the Frankfurt Book Fair in 2012. The inspiration came from Pivotal Tracker and the Open Source Fulcrum.
Most often the technology used to set up a kanban system is a whiteboard, with marker pens to draw and label the columns, and Post-it notes as a marker of the tasks. This kind of system is popular in unconferences, and also often used by software development houses. We also use this type of kanban approach a lot in Book Sprints.
The task manager (as I called it) and the production system were linked to each book and worked nicely. Although this system didn’t make it into the core code of Booktype, this version got the idea across, and later Juan Gutierrez made an integrated version for PubSweet. (During 2014, I also built this idea into a system for PLOS).
The task manager used a whiteboard-like interface in which the user could use to create columns (phases). Cards could be added to each phase and simple notes kept on each card. It was simple but effective.
In time I discovered Trello, and Why Cards are the Future of the Web by Paul Adams – these examples placed cards nicely within evolving design paradigms of the Internet, and I started to think about this model in more detail.
There are many advantages to cards, not the least being that cards can ‘follow the user’ – think of them as powerful work-unit-applications that can be accessed by a user within any context where they are needed.
Additionally, when thinking of digital cards within the digital workflow-kanban paradigm, the nice thing is that it is a very simple model. There are essentially just 2 elements – cards and columns. You can create as many of each as you like. Further, you can name the columns and cards anything you like. That means these two devices can be used to represent any number of simple or complex workflows. You can start from the kanban default – three columns marked ‘to do’, ‘doing’ and ‘done,’ and add cards for each task – progressing them from left to right as tasks progress from ‘to do’ to ‘done.’ This is the default configuration when creating a new Trello board.
Replicating this system in an application is pretty easy to do. Trello is an excellent example. While Trello is not easily integrated into another technical system (such as an in-house publishing system), it is interesting in that the designers, while surely tempted by all that a web application could offer, have endeavoured to keep the Trello system true to the kanban ideology of useful but simple. With Trello, therefore, you can add columns, and cards to columns, naming each as required. When you open a card, however, you have some nice widgets for making lists, comments, discussions, attaching files etc. This is something paper cannot easily do, at least not with the small real estate afforded by Post-it notes.
Trello is a lovely application precisely because these systems, like the paper kanban, have been designed to be simple to use and serve as many generic use cases as possible.
However,while digital kanban systems like this are useful as standalone ‘context agnostic’ systems, they could be much more powerful for publishers (or anyone) if this simplicity and flexibility could be preserved while the system also served their specific use case. The trick is to preserve the simplicity and flexibility to allow publishers to model existing and future workflows in an easily ‘grok-able’ drag and drop manner (similar to Trello), while building cards that reflect the publisher’s specific needs (to invite editors, push content to external vendor services, perform peer review etc).
Building cards like this, means pushing cards away from the Trello/kanban generic-use paper metaphor towards a more sophisticated specific-use digital and networked paradigm. This means embracing the idea that cards are networked applications and building cards that precisely serve the publisher’s needs and integrate into their existing internal and external systems.
Amongst the core requirements for a book production platform are the source file format and the editor, and of course, these are intimately linked. The development team is usually faced with choosing the format first, then the editor.
Choosing a format
The choice is pretty much HTML? or not HTML?
Currently, HTML is the ruling choice of format for a web-based book production platform. HTML is native to the browser and has associated standards-compliant support, such as CSS and javascript. Inversely, not choosing HTML puts you in a bit of a hole and can create a lot of overhead.
It might be interesting to look back a little and learn from some others since there have already been projects in this space that started down non-HTML roads and then gave it up for HTML. Kathi Fletcher, originally the project manager and technical director for Connexions (now OpenStax) which built a custom XML editing environment for academic materials, later researched in-browser XML vs HTML editing environments for her Shuttleworth Foundation-funded OERPUB project. Kathi became convinced HTML was the way to go and did some great work on HTML editor usability with the Aloha HTML editor.
We have chosen to use HTML5 as the canonical format for open textbooks, because developers and tools are more plentiful for web technologies than XML technologies.
The (closed source) O’Reilly Atlas platform also started with the complex AsciiDoc format (a form of markdown) and eventually awoke to the power of HTML in 2012.
HTML5-based authoring offers a streamlined production workflow for producing both print and digital outputs, facilitates “digital first” content development, and is a perfect fit for creating a WYSIWYG, web-based writing experience.
They then got an extra dose of religion and started a project called HTML Book which is a suggested ‘spec’ for a subset of HTML elements to be used in books.
So far I have not seen a book production platform travel the reverse direction, from HTML to something else. Instead, we are seeing more and more platforms start with, or change to, HTML as a source file format.
Markdown
Markdown is sometimes put forward as the way to go but I’m not going to go into that in too much detail here. I have talked about this elsewhere. The only additional thing I will say is that markdown causes even more issues for book production platforms than those included in that article. Namely, in an in-browser markdown environment, the markdown will most likely be displayed as rendered HTML next to the authoring pane. That is a huge amount of lost screen space and extra UI junk for no apparent gain. Think of the UX cost. If you don’t have that rendered display then you will most likely only see pure markdown in a text field with no rendered display. The user won’t really know if their document looks right until it is rendered somewhere down the line, which is also a tremendous cost to the user for no apparent gain. Markdown: all pain, no gain.
NB: There is a possible good use case for markdown as a helpful add-on for HTML WYSI editors but I will cover that later.
LaTeX
There is a more valid use case for LaTeX in the browser since some scientists and academics will never use anything else, and you’ll never convince them to adopt HTML regardless of the benefits. You are up against the great Church of Knuth and I don’t fancy your chances. If your audience is comprised of LaTeX addicts, then I think you have no choice other than to support that.
Many times I have talked about remedies for unstructured MS Word documents (for scientific manuscripts) only to have someone earnestly comment that if everyone just learned LaTeX we would be in a much better position… They might be right, but I’m pretty sure it’s never going to happen.
The preference for LaTeX is a legacy issue, and problematic, but needs to be dealt with. (Unfortunately, today’s Markdown heroes are growing legacy issues like this with each passing day, and that is going to cost us down the road).
Recently there has been some interesting work on in-browser LaTeX editing including the (closed source) Authorea platform and, most notably the (open source) ShareLatex platform. ShareLatex round trips the LaTeX syntax displayed and edited in a text area (in the browser), renders that to a bitmap on the server, and returns it to the browser for a side-by-side ‘WYSIWYG’. The effect is that you can see a just-in-time rendered view of the LaTeX as you type. It’s a neat trick and effective if you insist on LaTeX in a web-based platform. Then you just have to live with the UI costs. However ,you only need this approach if you wish to support the full LaTeX syntax. If you wish to just support LaTeX equations, you can use an HTML editor with a LaTeX plugin based on MathJax or the Khan Academies KaTeX(and there are some other solutions such as Mathoid).
Incidentally, if you need to support full LaTeX I highly recommend checking out ShareLaTeX over WriteLaTeX. They both have the same approach but WriteLaTeX is proprietary whereas you can pick up the ShareLaTeX code and integrate it straight away. You could even build your own ShareLaTeX-like interface, it’s not too tricky – together with a colleague – Rizwan Reza – and I (Riz did all the hard work) we managed to develop a workable prototype in about 2 days, but there are many gotchas setting up the LaTeX compiler correctly.
Not many book projects need LaTeX, so I will leave this as an interesting edge case. There are solutions if you need it, but not many people need it.
XML
I think I will just leave it to the words of the brilliant Dave Cramer (Hachette Book Group):
So we’ve chosen to describe our content with HTML, and build our production system around HTML.
When I tell people that, they smile condescendingly, and chuckle a bit. “That’s cute. Why don’t you use real XML?”
I then ask them what you can do in Docbook (or TEI, or NLM) that you can’t do in XHTML? I haven’t heard a good answer to that question yet. XHTML is XML, by definition. Calling something “para” rather than “p” doesn’t get you anything, except carpal tunnel syndrome and invoices from consultants
The problem with non-HTML XML is that it is essentially just XML the browser can’t use. Hence you lose all that other good stuff like WYSI editors, CSS design tools, cool tricks with JavaScript, and all the cool tools that are being developed for HTML. XML just can’t compete, plus you are going to need to convert the XML into HTML anyway. So don’t make life more complicated than it already is – continue your love affair with XML as long as it’s XHTML!
HTML
HTML is king in the browser and it gives you all you need to make books. I don’t want to spend a lot of time arguing the merits of HTML in this post as there is a lot to say and I want to bring that in at other points of the conversation. But in brief:
HTML is supported by JS and CSS.
The DOM is known natively by the browser.
HTML is standards-based.
It is straightforward.
HTML is easy to read and easy to clean.
HTML is the most popular file format on the planet.
You can use HTML to build structure in documents with assigned class and id values, or microdata formats.
HTML is the native file format for EPUB.
PDF can be rendered directly from HTML in the browser (more on this later).
HTML can be paginated in the browser.
CSS is moving towards supporting more and more page based elements.
The browser can act as a design environment.
You can create real what-you-see-is (WYSI) production environments.
Basic editing is built into the format itself.
HTML is supported by an enormous number of tools for conversion (in and out).
HTML is supported by an enormous repository of examples (the web).
HTML is cheap to develop with.
Even book designers are getting used to it.
Some schools teach it.
It has a million free tutorials online to help you use it.
A lot of people know HTML.
HTML is supported by a rapidly proliferating body of JavaScripts for typography, graph production, animation, interactions, dynamic rendering etc etc etc etc
The basic idea really comes down to this.
HTML is the cheapest format of our time.
HTML is the most popular format of our time.
HTML is the networked document format of our time.
Increasingly HTML is the way stories are told, whether that is in books or on the web. It’s a trite analogy perhaps, but HTML is the paper of our time. As Dave Cramer says:
why start with something other than HTML, when you have to turn it into HTML anyway?
It should be noted that Cramer also turns HTML into paper, and the Hachette Book Group have produced many beautiful paper books using HTML as the source format. Many of these books you will now find in the best-selling sections of your local brick and mortar bookstore.
Other print producers are also using HTML as the source. Print-on-demand services, used to producing very ugly books by ingesting MS Word and dealing with all that ugly conversion, are also adopting HTML production environments. Books on Demand, Germany’s largest Print on Demand service, adopted Booktype so their customers could have an easy in-browser book production environment. The source format is HTML but the users don’t know that, and the books look better. That’s the beauty of HTML.
Finally, helped a lot by the efforts of Dave Cramer and the Hachette Book Group, Sourcefabric, the people at O’Reilly, and others adopting HTML, we might be starting to see the very beginning of the changing of the guard.
HTML is the way to go for Book Production Platforms. If you choose another format you will find you inherit a lot of costs and additional overheads and, sadly, you will soon be left behind. There is just no format going forward at the same speed as HTML. Not even close. So, my advice is to first ask the question – can HTML do what you need? Push your team to answer that question. Will format X give you anything HTML can’t? As an exercise ask your team to prove HTML is a bad choice, and if the answer is not-HTML, then contact me and let me try and talk you into it!
There are a number of web-based book production platforms out there at the moment. Booktype was the first. Its birth was around 2006-2007 and it started as a series of extensions (written in Perl) to the TWiki platform. TWiki was, and is, an old school wiki with a very pluggable architecture.
Booktype is now a stand-alone book production platform built with Python (Django). I founded the project and kept it going for many years, and I’m very proud of it. It is free software and now has a permanent new home at the Open Source, Berlin-based, development house Sourcefabric. I’ve since moved on to think about similar issues for the Public Library of Science.
Since Booktype, many platforms have come out of the woodwork including Atlas (closed source), PressBooks (semi open), gitbook, Inkling, PubSweet, Lexicon, Penflip (closed), Gitbook.io, FastPencil (closed), and many many others.
Seeing these evolve has been interesting. Most interesting is that I see a lot of mistakes still being made which we made in the early days of Booktype. I’m not saying Booktype is perfect, it is far from it, but I wanted to document what I consider to be a few high-level gotchas for those wanting to build this kind of platform. We need more book production platforms that improve the game. We need to avoid making the same mistakes over and over, so I hope the following will give those building tools from scratch at least something to think about.
This article is first in a series. It should be noted that I am targeting my comments at those that wish to build Open Source book production platforms. I’m not terribly interested (actively disinterested), in closed source platforms. Hence the narrative encourages you, the Open Source development team, to consider book production platforms as a distinct category of software – don’t use existing software such as MediaWiki, or WordPress etc to do the job.
Stand-alone platforms
I firmly believe that book production platforms should be built as stand-alone applications dedicated to the work at hand – building books. Book production platforms should be specialised software that ‘thinks like a book’. Your users want to make books, not blog posts or wiki articles, and they deserve a platform that is built with their goal as the central premise.
Don’t learn this the hard way as I did. Booktype started with a wiki and it did a pretty good job. At the time TWiki could be considered as a kind of rapid prototyping framework for Perl, much like Django or Rails is for Python and Ruby respectively. It provided essential login features and user management, plus a host of plugins to extend functionality with diffs, reports, permission management etc. It did pretty well for a while. However, the wiki-like paradigm soon started to grow old. Initially, I had pulled the guts out of the wiki and replaced wiki markup editors with HTML editors (more on that later) and did a whole lot of crazy URL redirects using .htaccess to get nice book-like book/chapter URLs and attending structure. That was OK, but when it came to other functionality that books needed, then the wiki paradigm was sagging pretty noticeably. It also took increasing amounts of time and effort to build an interface that was clearly intended for making books instead of wiki pages, not to mention the issues with updating a core application framework for security or performance improvements when the internals had been hacked so extensively it no longer really worked the same way as the original application.
A bit of template paint helped with some of these issues, and I commissioned some programmers to extend TWiki to fill in these book-wiki gaps, but, after a while, it became obvious it would be better to build a dedicated standalone book production platform from scratch. Given all my experience since then, I am convinced that if you want to make books you should have a software built specifically to do that.
Paradigm differences
Book production platforms are a specific category of software as the functional needs are quite different from those for producing wikis, blogs, or other types of CMS. When building book production software there are essential paradigmatic differences that just force you out of the existing categories and into the new…
The following are some examples, and I will document one or more at a time as this series continues. First of all, the Table of Contents.
Table Of Contents
Any book production software needs a way to create and manage a Table of Contents (ToC). Neither wikis, CMS, nor blogs have the need to structure content in this way: they are designed for non-linear, contextual navigation (you click on a link from within a paragraph to be taken to somewhere else). The closest these other software paradigms get to a Table of Contents is through navigation bars and breadcrumbs and hacking together ‘lists’ of associated content.
However, books have a very linear structure so one thing follows another in a vertical narrative. That’s not to say you can’t break the structure. However, if you intend to create paper books or electronic books, then it is very difficult to escape this very strict linearity. An easy and fluid way to manage this vertical linearity is a must for any book production platform.
There have been attempts at making this work with other types of software. Mediawiki makes an attempt to do this with the concept of ‘collections’. A user can save references to articles in a list then jockey them into order. Other software, such as PressBooks, has attempted the same with blogs – organising blog posts into a list. But the solutions are never satisfactory. It always feels like a compromise – the poor user is asked to work with something that feels like it’s actually built for another job, and it is.
A Table of Contents interface should be the heart of a book production platform, and the platform should own that space. There needs to be a fluid and fast interface for creating new chapters, moving items around, quickly seeing the structure of the book, and if you like the idea of concurrent production, then it needs also to be able to show at a glance who is working on what. The user needs to be able to add and remove chapters at a click, move chapters outside of the ToC while keeping them available for possible later use, or rename them – right from the ToC without the need to dig down into individual chapter settings. Additionally, the changes in structure need to be dynamic: updating immediately for every user without the need to refresh. The status of individual chapters needs to be ascertained from a single glance at the ToC. The interface for book production should be fast, clean (separate from additional blog or wiki cruft), and feel like it is an interface built specifically for the job it is attending to.
The ToC is how people get an overview of a book, and book production software necessarily gives them the tools to manage that overview. So start with the Table of Contents as a central UI element, and let the user go from there. The user will then feel that the platform is all about managing their book. The UI will communicate ‘book! book! book!’…not ‘wiki!…err…book!…errr…wiki!’. A ToC as a central motif communicates the purpose of the platform and gives the user a tool that gives an immediate overview of the work at hand, and the output feels like a book from the very beginning.
Book production platforms need to have a Table of Contents interface as a central part of the paradigm, and this should be reflected in the UI – it should not just be something that has been tacked on as a ‘workable solution’. Start building something to manage a ToC beautifully and work out from there.
Around 1460, the entrepreneur Johann Fust (commonly confused with Johann Faust) took some of the Gutenberg bibles to Paris to sell. Paris did not know of the printing press and rumours started. How could someone produce so many books so cheaply? How could they possibly be made so quickly and with the exact same rendering of all characters on all pages? The apparent ease and speed by which these books were produced had the feeling of witchcraft.
It’s a good story and a popular one, although it might actually be apocryphal. It seems, according to Elizabeth Eisenstein [see The Printing Press as Agent of Change, Cambridge University Press 1979, p50] that at that time, the “increase in output did strike contemporary observers as sufficiently remarkable to suggest supernatural intervention.” This story helps us imagine how Gutenberg’s Press changed the world forever, simply by making the production of books easier and faster. Before this, books were created by scribes copying the content by hand – a process which took tremendous time was prone to error and was very expensive. The newly invented printing press meant books could be made quick and cheaply. As a result intellectuals and artists were starting to work closely with printers, print shops became places where these people would meet and where knowledge started to cross disciplines, publishers eventually evolved, the economics surrounding knowledge changed, book production was made accessible to a vastly larger section of society, literacy increased, and knowledge was transmitted across societies and boundaries in ways previously unimaginable. Making books easier and faster to produce changed everything.
Because books are now web pages, book production again becomes easier. All the tools required to produce beautiful books can be accessed through a browser. ‘Web-based workflows’ for book production begin with an empty book and take you through the entire book production process without needing to leave the browser. Easy-to-use tools take you through this workflow and in so doing they change every part of book production. The book becomes something you can make, not something that publishers make for you.
This ease of production is assisted greatly by the development of online print-on-demand services and ebook distribution channels which integrate APIs. An API is an ‘Application Programming Interface’ – jargon for a technical process that enables websites and online services to integrate and work together. Using APIs, you can utilise the services from another website in your own webpage. For example Lulu.com – one of the world’s largest online print-on-demand services – allows you to upload books directly to their service from your own website. That makes web-to-new book production models and print workflows a whole lot easier and faster. Ebook distribution services are also offering APIs so platforms can push ebooks directly into their channel.
Book production coming online means new book production models can evolve and new kinds of publishing can emerge. Book production can become faster, publishing becomes something anyone can do, people from all over the world can share distributed workflows and work on the same content simultaneously. Book production is open to more people, and anyone can produce an array of books from best sellers to niche texts. Peer production markets of skills and knowledge can ben generated to enable the production of the books we want – faster, cheaper, and better than the current state of publishing.
Book production platforms to enable these advantages are just starting to appear. Wikis were, and still are for many, the default knowledge production platform and have been used many times to make books. But Wikis are not designed for making books. Not only do they do this badly but they do not foster a ‘book writing’ mindset. Wikis tend to be used for short form texts and often as a kind of textual mind map. Wikis do not deliver the ease of production we are looking for.
The same is true of blogging software. Blogs do seem to build a culture of slightly longer and more structured narrative forms which does help but blog software is not intended for producing books either. It is intended for producing another kind of text. It’s true that blogs like WordPress can be bent into many shapes and WordPress is often considered by many to be a Content Management Tool rather than a blog, but at the end of the day, building a non-blog becomes more work using WordPress than if you had chosen a tool built for that purpose.
Essentially Wikis, Blogs, and CMS all have very specific roles. Bending them to fit book production may work for a while, but they lack the possibility to richly explore online book production because they were not built to do this. They might be a useful shortcut for rapid prototyping but their inherent paradigm will soon get in the way. If you want to do something, then it’s usually more effective to use a tool built for that purpose. Additionally, it’s not just the tool’s purpose that counts: the culture surrounding how the tool is used is also important.
Having used a wiki to build a publishing system, I can say from experience that we soon ran up against core design principles of the tool that made it hard to make it do what we wanted. We could do all the basics but when we really started working in an immersive way with online book production, we found that there were many issues that a wiki could not handle without significant re-development of its architecture.
When building a software for book production there are some features and issues that need to be considered as part of the core paradigm. First – any platform operating in the world of open or federated publishing MUST be open source. Open content on a closed platform is a hypocritical position. You deserve to be skeptical of any platform like this and its relationship to you, your privacy, the ownership and control of content, the distribution paths open to you etc. Beyond the primary necessity that the platform must be open source there are 4 key features that should be easy to manage :
it’s easy to create a new book
it’s easy to add and edit content
it’s easy to manage the table of contents
it’s easy to export to a book format
These are the basic 4 necessary ingredients.
Beyond this, there are some very important issues that need to be managed, either in a second tier of interface or done ‘automagically’ using default settings or presets:
copyright license management
attribution
well designed output
That gets you to a basic ‘plain vanilla’ online book production environment. Of course it looks easy but it’s not. Realizing this simple vision is pretty easy if you wish to produce EPUBs. However, if you wish to support multiple output formats, it gets trickier. Paper books are especially tricky because you have to deal with the page – a real paper page. Paper pages need left and right margin control, page numbering, accurate linking of the page numbers to the table of contents, and not to forget bi-directional text rendering and widow and orphans control. Not only are these not very simple issues to resolve technically they are also offer very many questions about usability. How many of these options/parameters do you manage ‘by magic’ and how many (and how) do you expose to the user to control? This is when the going gets tough.
We are seeing a few online platforms evolve that are embracing some or all of these notions. The variety of feature sets and strategies is large but the following three online book production platforms are the ones I believe have the highest claim to having a stake in the game to date :
PressBooks – a service started by Canadian Hugh McGuire who had previously experimented with a book platform called the Book Oven (which is now closed). PressBooks is based on WordPress and has a good workflow if you are familiar with the popular blogging tool. Unfortunately the platform, while built on top of an open source software, is not open source software. It is a free (gratis) service but closed source. PressBooks does not currently hold high collaborative potential but it is very useful for writers who wish to work with an editor or editorial teams to compile anthologies. PressBooks is focused on extending the traditional publishing cycle online. The development team is spending a lot of time working on good formatting for book-formatted PDF. PressBooks also targets the web as a book output.
Inkling – a service which is free to use but all content must be sold through the Inkling sales channel. Inkling derives a royalty for each sale through this channel. It is closed source and targets the iPad and the web as output formats. Inkling is targeted at textbook publishers and sells content in the form of books and chapters. Inkling is not open source and is targeted at traditional (but distributed) online publishing workflows for traditional publishers.
Booktype – of the three listed here, Booktype has been around the longest – formerly known as Booki and originally developed by FLOSS Manuals, it has been around for almost 6 years in various functional prototypes. Booktype is now developed by Sourcefabric and is open source. Booktype has a very flexible workflow which is ‘native to the web’ and is designed for non-publishers and publishers alike. Booktype can be a highly collaborative environment and is the platform of choice for rapid development processes such as Book Sprints. Booktype outputs to web, iPad, Kindle, print-on-demand, text document formats, PDF and many other formats. (Disclaimer : I am the project lead for Booktype).
These three are the 3 best platforms on the radar for easy online book production right now. The web being what it is, means there will be more to enter the market and this will probably happen quickly. The iPad iBook Author is not mentioned here because although easy to use it is not an online tool and I believe this is a critical missing feature for reasons that will become clearer later.
I believe these three outlined above change the game and interestingly have their own distinct primary use cases and strategies. There will be more to come. If you believe Gutenberg’s efficiencies changed society forever then what effect will tools like these have? It’s a giddy question and from working with book production like this for 5 years now, I firmly believe making books in the browser is not just a matter of having an easy way of making books – it will have an enormous impact on society as a whole.