I’ve been pondering innovation a lot recently. I think this has come about because of a whole bunch of 1.0 releases that the Coko team has produced over the last weeks. There is a lot of publishing and software systems innovation popping out of those releases – Editoria 1.0, INK 1.0 (now 1.1 already), and PubSweet 1.0 (alpha – beta coming soon).
However, I want to focus on PubSweet because what it offers the publishing sector might be easy to overlook and what it offers is rather an astonishing rewrite of the legacy landscape we currently occupy.
You may wish to grab a sneak peak at the beta, and yet to be promoted, PubSweet website (wait a few weeks before trying PubSweet, we are in alpha and need to test both the docs and the alpha release). The site looks beautiful which is a testament to the hard work put into it by Julien Taquet and Richard Smith-Unna.
The layers of innovation happening in PubSweet is pretty remarkable and this is mainly a product of the initial vision and the fantastic work Jure Triglav has put into architecting an exciting software to realise this vision. You can read a little more about this here.
While I could enumerate the innovations, which include Authsome (Attribute Based Access Control for publishing), a component based architecture (back end and front end) and many others – I want to focus on the effect of PubSweet.
PubSweet, as the website now states, is an open toolkit for building publishing workflows. What does this mean exactly? Well to find out we need to look at two features in particular in a little detail:
There are two features of the PubSweet ecosystem that illustrate this statement best:
First up – the PubSweet component library.

Just what are you looking at on this page? Well, PubSweet is not a publishing platform in the way we typically talk about these things. Typically a publishing platform is one big monolith or, at best, a partially decoupled, platform that prescribes a workflow. Or, in the case of Aperta (which I designed for PLoS), supports a variety of possible workflows after some additional software development.
However, PubSweet takes this idea that I designed into Aperta, a whole lot further. PubSweet is not a platform but essentially a framework/toolkit that you can use to build any kind of publishing platform you want. The way to do this is by assembling the platform from components, hence the component library.
The library consists of both back and front end components, since PubSweet can be extended ‘on both ends’. Hence the INK-backend component you see in that library enables the system to interact with INK for file conversions etc. This component is not visible to the user but extends the overall functionality of the platform ‘under the hood’. While the Editoria-bookbuilder component is the bookbuilder interface for the book platform Editoria.

And the wax-editor component that you see further down the page is the best of breed editor we built on top of Substance.
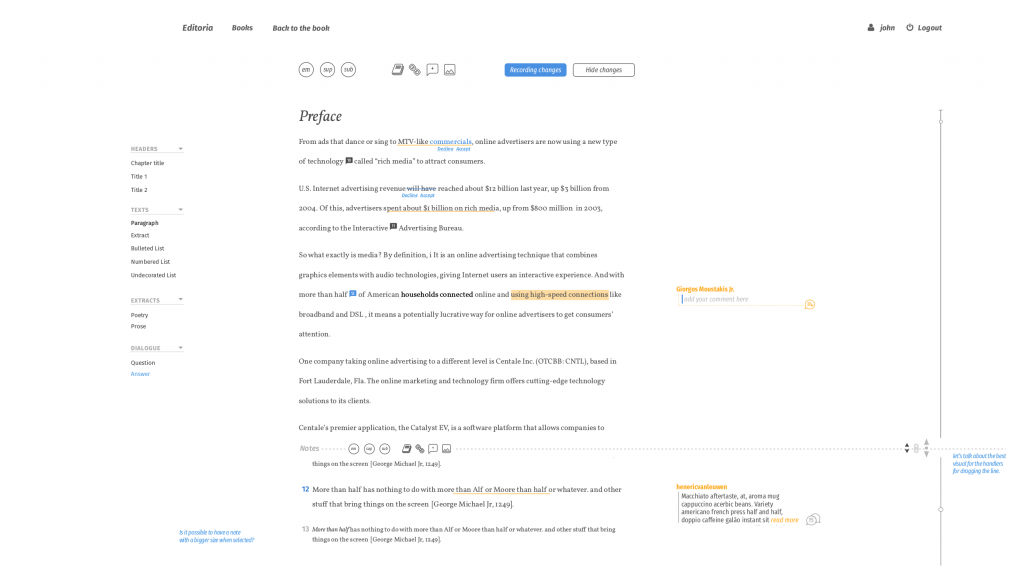
What does this mean? Well, it means that you can assemble the platform you want out of all these components. No more building the platform for book production (eg booktype etc) or the Manuscript Submission System (eg Aperta), rather you can take the components you want and assemble them as you like. Not only does this support a tremendous number of use cases, but it has the following knock on effects:
- efficient reuse – if you need something new in your publishing platform you need only build the difference – making changes small and affordable.
- shared reduced effort – if you contribute what you build back to the library you reduce the burden of development for others.
- innovation – anyone with some JavaScript skills or JS folks on staff can innovate on the component level and slot that into their publishing platform. Making innovation and the associated risk cheap and easy to back out of.
- continual optimisation – no need to ‘jump platforms’ when you run out of functionality. Instead you can continually optimise your workflow by reconfiguring and extending the system.
- developing conversations – now this might not be so obvious but I find this tremendously exciting. By sharing components and innovations conversations will start to emerge between publishers. At this moment this doesn’t happen because the systems are owned by software vendors. Publishers don’t talk to each other about platforms, which also means that they hardly spend the time learning from each other about how to optimise their workflow (and less time on how to innovate). However, publishers will naturally fall into these conversations if they use each other’s components…I have already seen this in action at the PubSweet 2.0 meeting I facilitated last week in San Francisco. It was very exciting to see.
- Jumpstart a new solutions ecosystem – currently publishers are reliant on ‘big box’ software vendors and service providers. If a publisher wants to improve their system they must deal with an expensive, slow moving. vendor. That vendor must then balance legacy code with a legacy client base to determine if they will make the requested changes. However, with PubSweet and the component approach, we might see the evolution of hundreds or thousands of small existing JavaScript shops assembling platforms out of the components for publishers. A small university publisher, for example, could work with a small local development house to assemble and extend a PubSweet component based platform to meet their needs. Effectively that means publishers have a whole lot more choice about who they do business with, it could also mean opening up a market for programmers they did not previously exist.
This is tremendously exciting. It’s so exciting I can hardly speak right now! No hyperbole intended, I can literally feel the adrenaline flowing through my veins as I write this.
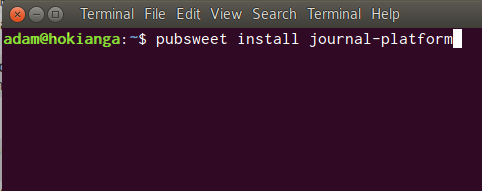
So…the second feature of the PubSweet universe that is going to blow peoples minds is the PubSweet CLI. So, CLI is an acronym for ‘Command Line Interface’. Geeky stuff. I won’t go into the full details of the PubSweet CLI as it is intended as a tool for the technically minded, but the item that will probably interest and excite you is scheduled for the 1.2 release. And that is – single line platform installs.
Yep…just imagine. If you want to try out a particular configuration of components which someone else has put together as a platform, then you need only run one command to install it.
Imagine something like:
pubsweet install editoria
or perhaps…
pubsweet install journal-platform
or…
pubsweet install open-peer-review-journal
…can you imagine?…. it is currently ridiculously difficult to install publishing platforms even if you have the code (most publishing platforms are closed source so you don’t even have the option). But… a single command line and you will have the system you want up and running…
Interestingly, this has been part of the vision from the beginning (notes from the early sessions I had with Jure, and Michael and Oliver from Substance can be found here), but it was almost too exciting to speak out loud in case we couldn’t get there. Now it is within striking distance and we should see this functionality within some weeks.
Even better is that this is all Open Source. So a big vendor won’t be able to buy this ever. They can use it, provide services on it, but they will never be able to have it all exclusively to themselves. We aren’t going to, nor can we, sell PubSweet to some proprietary vendor so don’t even bother asking. It is free for now and forever, and this might just be the most disruptive part of the whole plan.