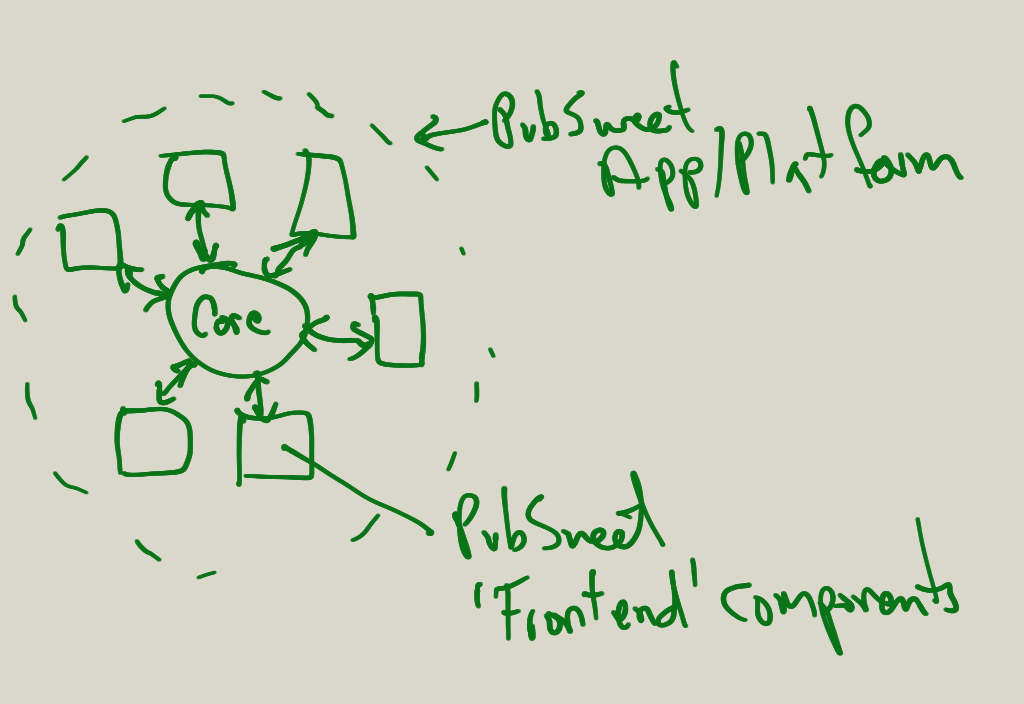
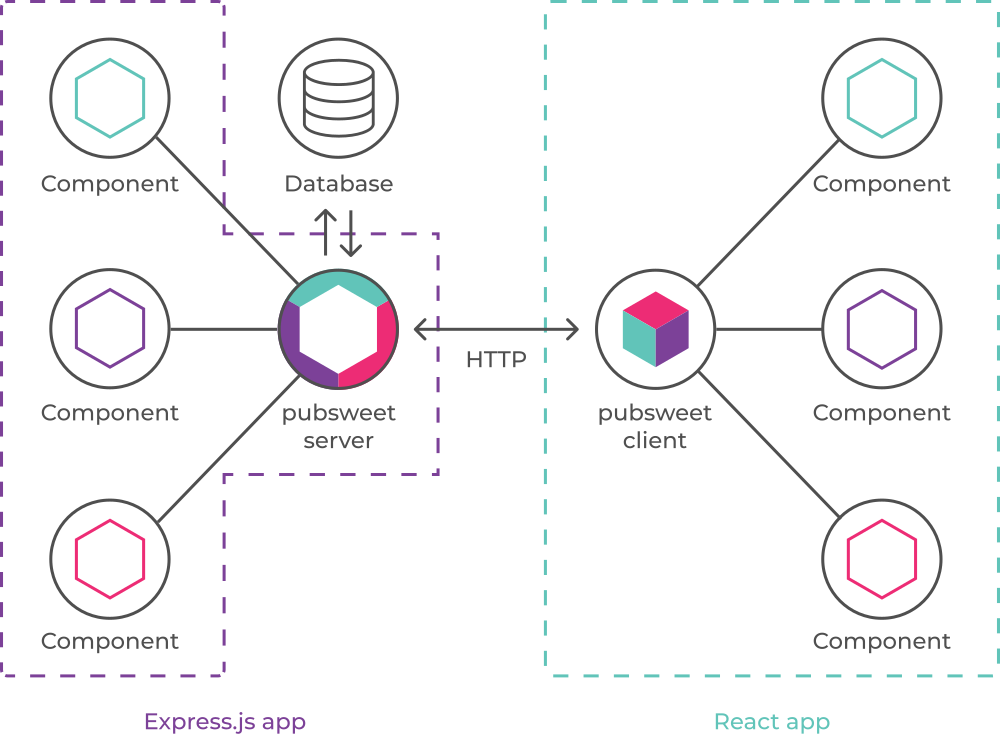
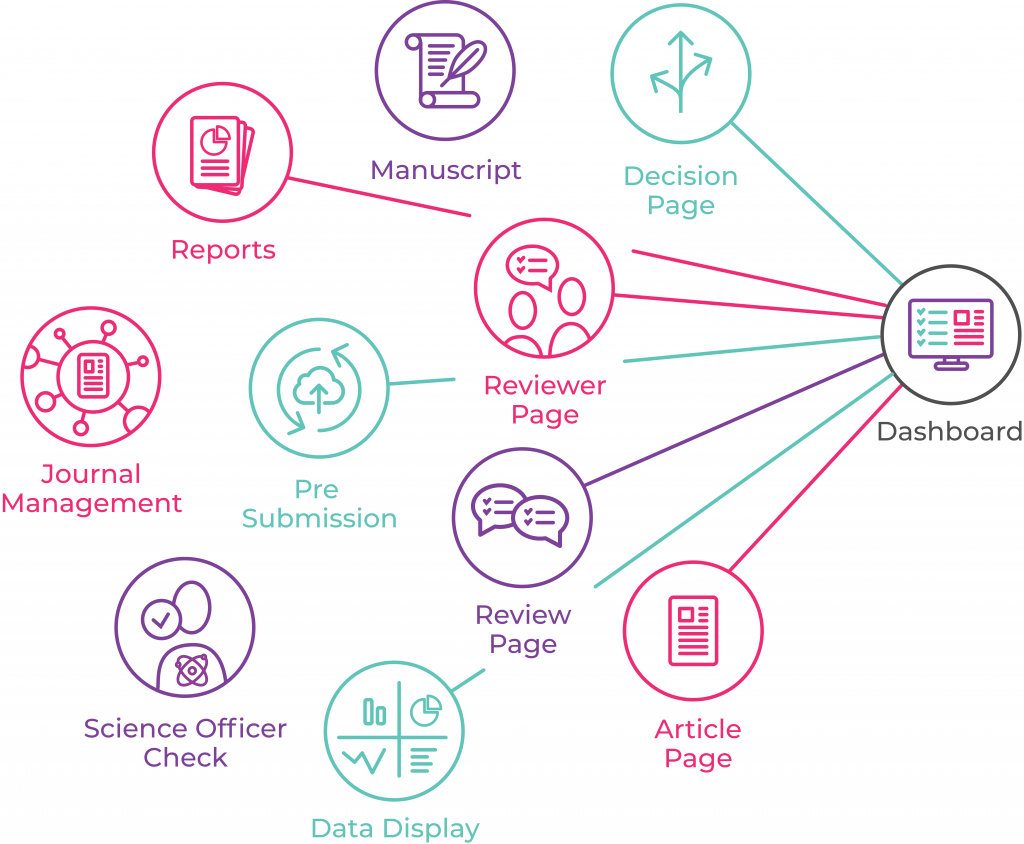
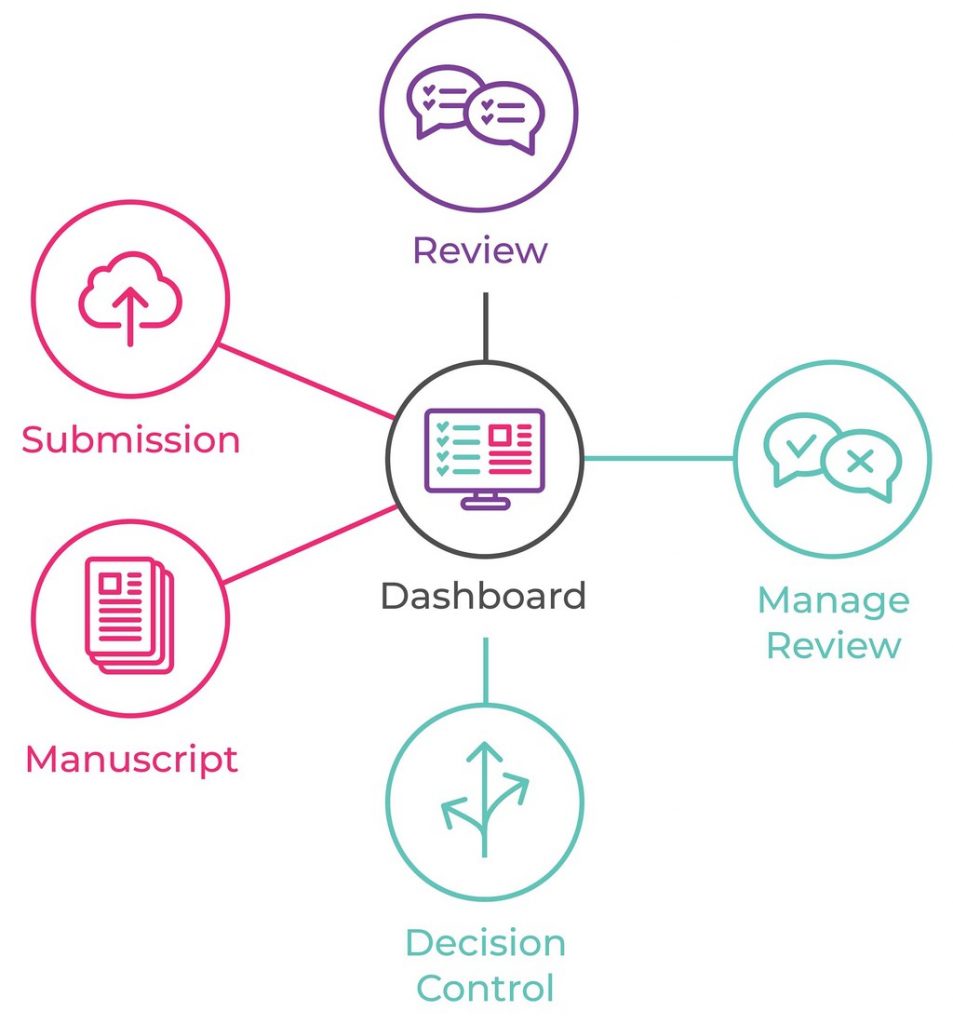
Reading Open Innovation – a thesis evolved by Henry Chesbrough in 2003. I have also the follow-up book published in 2006 which is a collaboration with other researchers going through his earlier thesis.
I’m researching this as I’m interested in what current literature exists that explains Open Source and why / how it works which is not from the Open Source domain. Books that emanate from the Open Source domain tend to be religious in nature and it is also true that most attacks against Open Source take it from the religious angle… so having literature that endorses the model which is not open source evangelicalism is very useful.
Previous to this I found a lot of value in The Diffusion of Innovations (originally published in 1962) by Everett Rogers.
Open Innovation and the Diffusion of Innovations separately explain quite a bit about why Open Source works, and I think I’ll post more about this as it becomes clearer in my head.
Chesbrough’s thesis can be summed up in one quote
The Open Innovation paradigm treats R&D as an open system. Open Innovation suggests that valuable ideas can come from inside or outside the company and can go to market from inside or outside the company
Essentially it is the admission that any one company doesn’t have all the smart teams/people/ideas. So how about re-imagining innovation and release it from a so-called ‘vertical innovation’ model, where all the R&D is done inhouse and where IP (Intellectual Property) is jealously guarded, to a open model where innovation essentially comes through collaboration with orgs and individuals outside the company.
From an Open Source point of view this is a ‘duh’ moment… Open Source has long expounded this approach. But…I have never found it well explained…
So it is good to find this argument made elsewhere and in clearer terms…but unfortunately the Chesborough thesis was published in 2003 when Open Source was still very young. Consequently Chesbrough reads Open Source as a idealistic and altruistic movement… he doesn’t really consider open source projects to have a business model and a business model is central to his thesis. Its a pity as Open Source has moved on since then and there are a lot of very successful and interesting examples of Open Source business models. But if you sorta squint while you are reading, and blur out the dated-ness then there is a lot of stuff that could just be quoted verbatim that makes a strong argument for Open Source as seen through the lens of the Open Innovation thesis.
Thats pretty interesting as, combined with the Diffusion of Innovations, these two bodies of work explain the value (and consequently provide a rationale which does not come from the open source sector directly) of open source. Open Innovation explains why open source is a good idea if you are a company whose business requires software to function in its core offerings, and the Diffusion of Innovation theory helps us understand why open source can beat closed source software in the arena of adoption.
The point is, if you can combine the two you have a winner – a model that enables rapid adoption and innovates faster than closed alternatives/competitors. If you can marry successful commercial activity to this you have something very powerful that can potentially wipe out the existing proprietary offerings – which is what we need in the publishing sector. The aim of what we are now doing in Coko, in this post-foundational stage, is to seed the commercial activity around the very healthy core of community technologies we have built.
Anyways… here are some quotes I liked from some of the chapters….Some of the quotes come from this chapter by Joel West and Scott Gallagher http://web.simmons.edu/~weigle/INNOVATION/Patterns%20of%20Open%20Innovation.pdf
Open Innovation is the use of purposive inflows and outflows of knowledge to accelerate internal innovation, and expand the markets for external use of innovation, respectively. Open Innovation is a paradigm that assumes that firms can and should use external ideas as well as internal ideas, and internal and external paths to market, as they look to advance their technology. Open Innovation processes combine internal and external ideas into architectures and systems. They utilize business models to define the requirements for these architectures and systems. The business model utilizes both external and internal ideas to create value, while defining internal mechanisms to claim some portion of that value. Open Innovation assumes that internal ideas can also be taken to market through external channels, outside the current businesses of the firm, to generate additional value
…useful knowledge is scarce, hard to find, and hazardous to rely upon (a root cause of the NIH syndrome). In Open Innovation, useful knowledge is generally believed to be widely distributed, and of generally high quality
IP becomes a critical element of innovation, since IP flows in and out of the firm on a regular basis, and can facilitate the use of markets to exchange valuable knowledge. IP can sometimes even be given away through publication, or donation.
Recently, open source software has emerged as an important phenomenon that utilizes external knowledge in a network structure (Lerner and Tirole 2002; O’Mahoney 2003; Dedrick and West 2004; von Hippel 2005)
Most software users would face significant switching costs in using some other software package, due to some combination of retraining user skills and converting data stored in proprietary file formats. As Arthur (1996) observes, software thus has tremendous positive returns to scale, generally allowing only one (or a small number) of winners to emerge.
These winners are tempted to extract rents from their customers by increasing prices and creating additional switching costs to protect those rents (Shapiro and Varian 1999). From these production economics, commercial software firms seek to build complete systems to meet a broad range of needs, in hopes of forestalling potential competitors and protecting high gross profit margins
In other cases, a system architecture will consist of various components. Some mature (or highly competitive) components may be highly commoditized, while other pieces are more rapidly changing or otherwise difficult to imitate and thus offer opportunities for capturing economic value. Two open source examples are the IBM’s WebSphere and Apple’s Safari browser…
…Customers access the WebSphere e-commerce software using standard web browsers, so IBM originally developed a proprietary httpd (web page) server. IBM later abandoned its server for the Apache httpd server, recognizing that it would be wasting resources trying to catch up to the better quality and larger market share enjoyed by Apache (West 2003). Today, IBM engineers are involved in the ongoing Apache innovation, both for the httpd server and also related projects hosted by the Apache Software Foundation (Apache.org website)