Plasmic looking good
A figma-ish approach https://www.plasmic.app/ Open Source!
Markdown definition
I’ve been pondering how you classify markdown as a way of creating text. Programmers like markdown and there is a tendency to in dev circles to advocate markdown for everyone.
But actually its very simple to define markdown as ‘source code’ (it is). Asking why we want authors to learn how to create source code should really be the question as it is largely rhetoric.
NZ Lockdown
We are in lockdown for the first time since Feb. 170 days of freedom. It is level 4 and the government just extended 8it to mid week. It seems there are about 30 known cases of the Delta variant in the community, which means there will be more to come. The government is moving hard and fast. Having said that, we have only 20% vaccinations (I got my first one today having become eligible only last week).
Lets see how it goes.
SSP P5 out now
Part 5 in the series about Single Source Publishing out now! Learn about the features of the source format and high level architecture than can make all the magic happen. https://coko.foundation/single-source-publishing-part-5-workflow-first-systems/
Single Source Publishing Digest
New Editoria Site
Coming soon…

Single Source Publishing Part 3 : Is Automation the Answer?
Single Source part 2
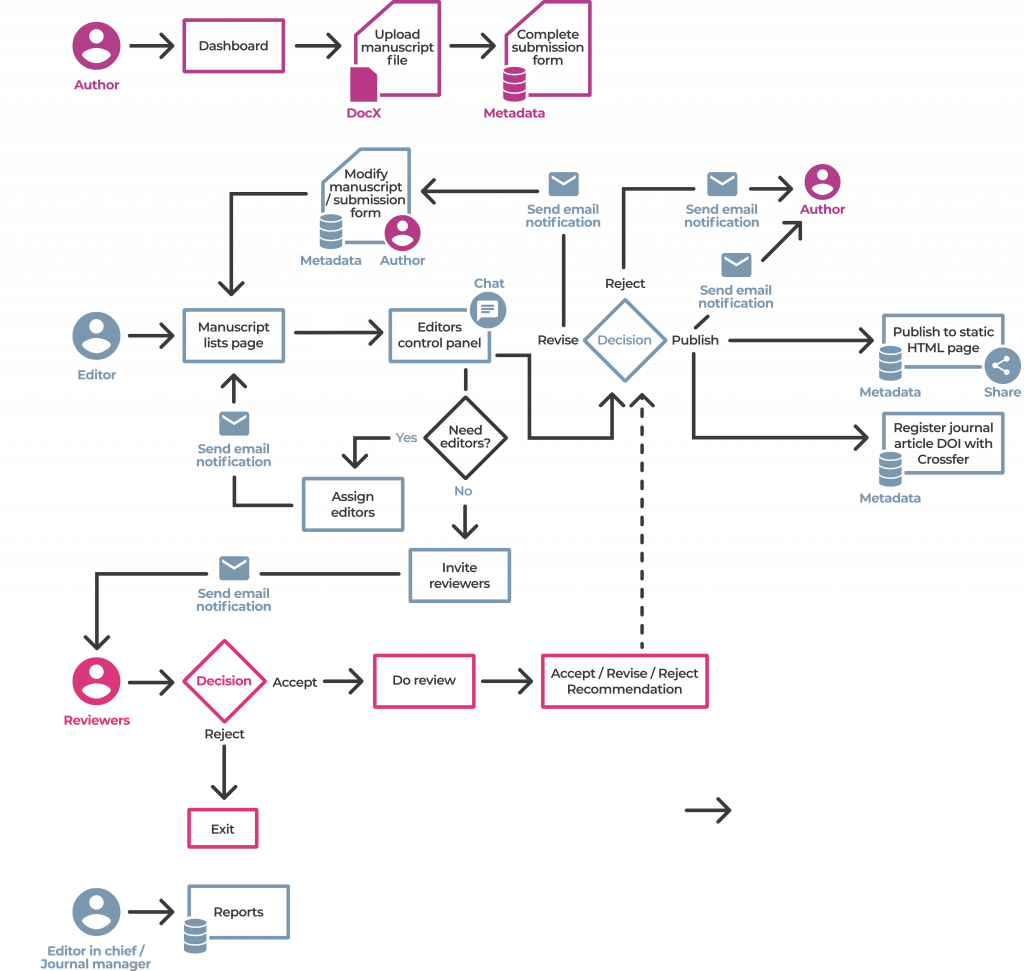
One workflow model for Kotahi
For aperture. A typical journal workflow that is supported by Kotahi presently. Kotahi can be configured to support many more workflows. I’ll share them also when we have good diagrams. Missing an arrow between manuscripts list page and control panel. Will update. Updated.