Read the colophon for this book by Bob Glushko
Seriously… an exercise in how to make your life too complicated. If they had used a single source tool all this nonsense wouldn’t have been needed. Ironic given the title and content of the book.
Publishing Innovator. Surfer. Ponderer. NZer.
Read the colophon for this book by Bob Glushko
Seriously… an exercise in how to make your life too complicated. If they had used a single source tool all this nonsense wouldn’t have been needed. Ironic given the title and content of the book.
Pondering the next articles in the Single Source series I’m publishing at Coko. I’m working it out as I go…
The series so far looks (at the moment) like this:
Floran Kohrt just put me onto this interesting project:
Code: https://github.com/Simon-Initiative/oli-torus Website: https://oli.cmu.edu/oli-communities/torus-community/ Its is alearning content management system with a focus on online courses.From Florian: "Torus is developed and used by the Open Learning Initiative at Carnegie Mellon University and published as part of the OpenSimon Toolkit."
We have a lot added to Kotahi. Check the news site for updates
https://kotahi.community/news/
Notably:
I’m writing a series on Single Source and publishing via Coko
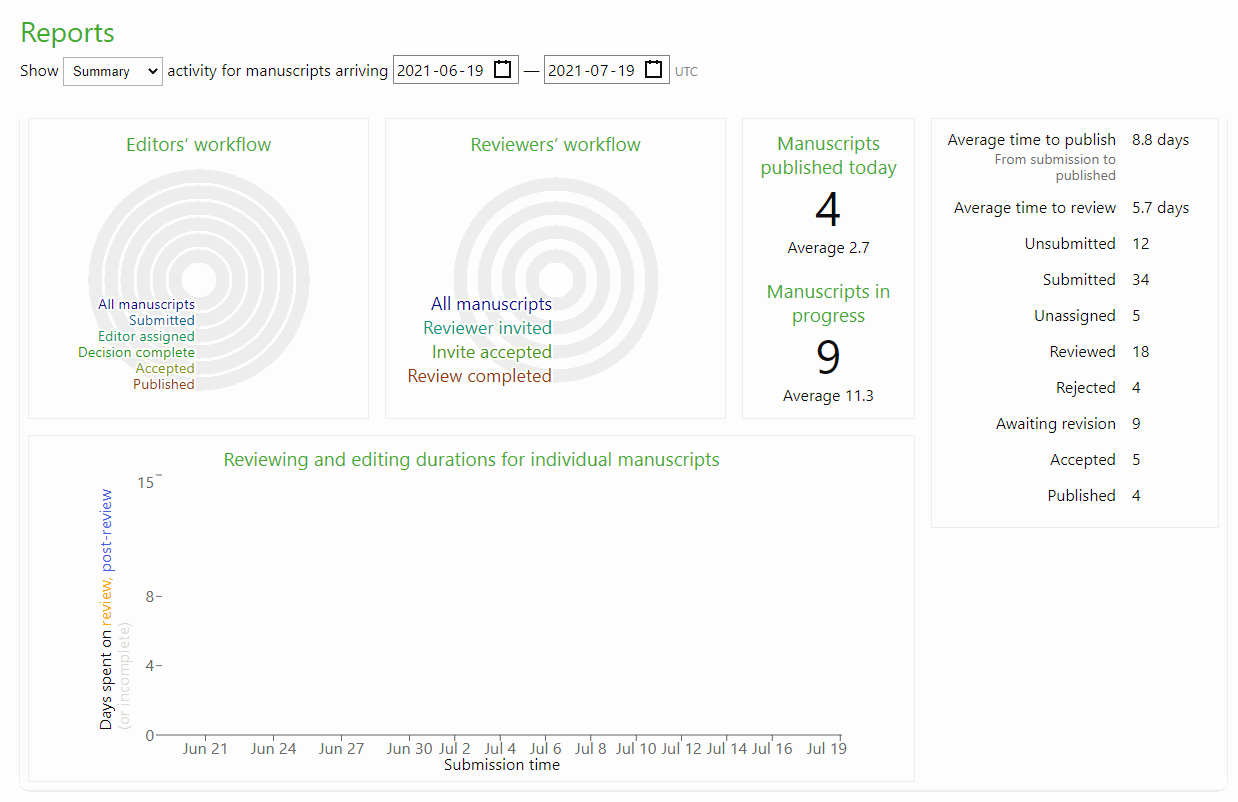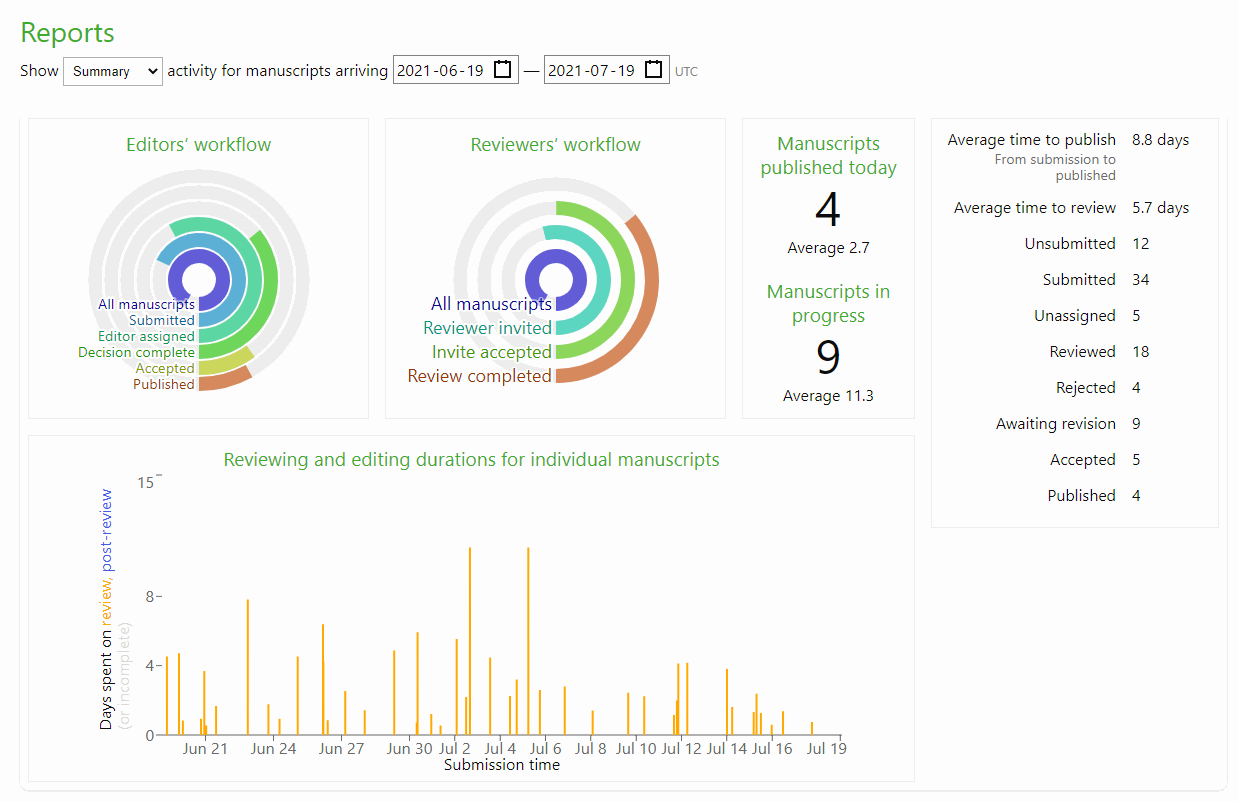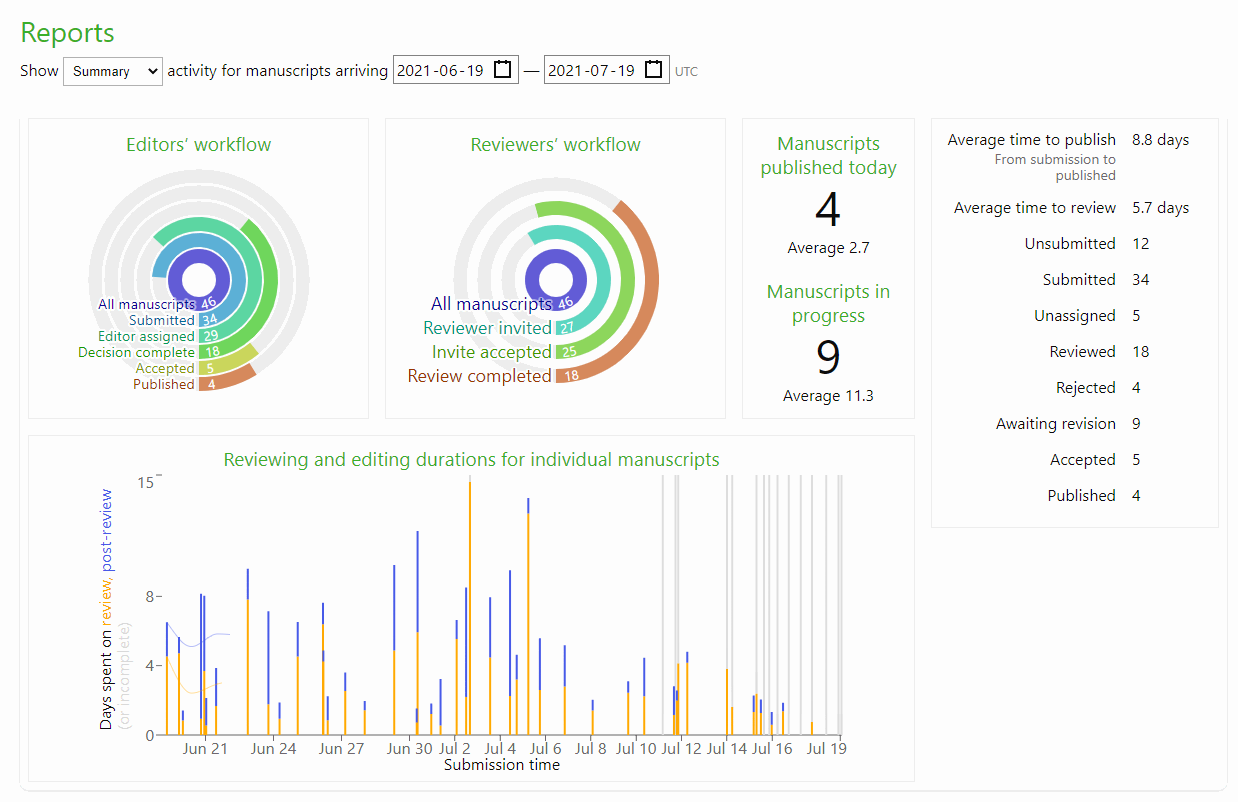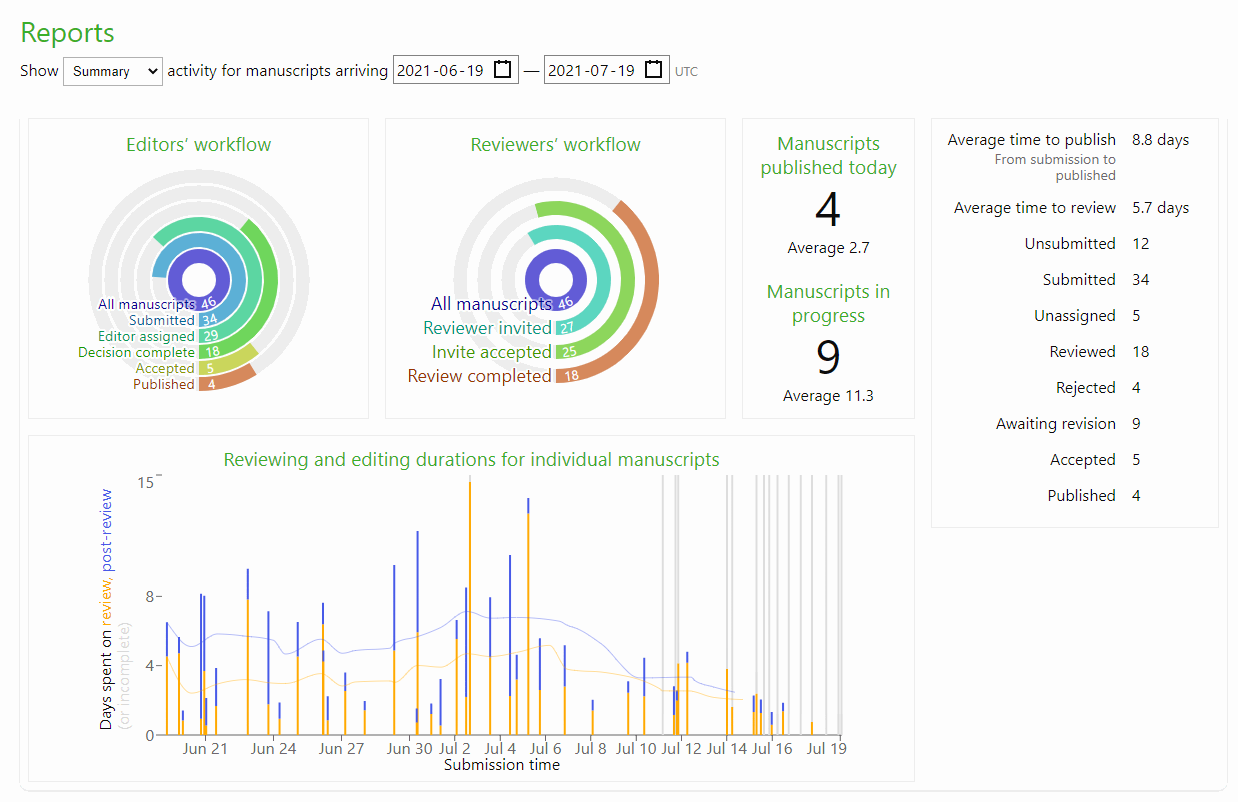
Post coming soon about the Kotahi reports interface.
There are a couple of issues in this sector that have been bothering me a bit. The first is a case of possible fauxpen source, the second is just a pet peeve.
The term fauxpen source or just ‘fauxpen’ has been around for many years and generally refers to projects that state they are open, but when you dig down you discover some funky stuff. Fauxpen source projects have a number of different approaches and I’ve seen almost all of them. Some say things like “we will open the source code” or “the source code isn’t good enough yet to release” … and then they keep that line going in perpetuity. Statements that point to an intended future open state are actually a good give away. In my experience these promises seldom materialize. Fortunately these cases of fauxpen are the most common and pretty easy to spot. I don’t think the folks that land these lines know just how common these kinds of statements are and how transparent they are. When I hear things like the above I lose interest in the project and I often tell them directly to come and talk to me when it is open.
Other fauxpen strategies are more difficult to spot and you may need some deep info to work it out. The use of licenses that they claim to be open but are not approved by the OSI is one example. For this you will need to understand a bit about licensing – which is not a fun or easy topic to come to grips with. For example, there has been some controversy about this with Elastic Search recently regarding their change to a fauxpen source license.
Then there are the cases when you just get a feeling from folks that something is funky. Something just doesn’t add up. This is a subjective reading I know, but I can’t tell you how many times I’ve had this feeling when talking to folks and over time its turned out to be right. It is an ikky feeling, I get all clammy and claustrophobic and tend to move away from them. I can’t help myself. I guess because at its heart fauxpen is an attempt to instrumentalize the good will generated by being known as open but with no real commitment to the idea. It feels very bad faith-y and at its core I guess it is nothing more than a pure, and rather cynical, branding play.
Recently my fauxpen radar was re-awakened by this https://www.gitmemory.com/issue/pubpub/pubpub/1125/723329876. This came on my radar as a result of some folks that approached us that didn’t want to use pubpub because of the reasons that follow.
Essentially the above is a discussion that highlights that Pubpub requires firebase, a closed source dependency. It also strongly suggests using CloudAMQP, Mailchimp & Mailgun, AWS – all closed. This might be ok if they supported folks to do without these dependencies – but it appears they do not.
The reply to the comment on ‘self-installs’ [sic] states that “Thanks for the interest in running PubPub! We’re still not at a place where we’re really supporting self-installs, as that’s just not our growth focus at the moment.”.
The comment on missing install docs in the same thread is also a little concerning. It is not unusual for install docs to be out of date or incomplete, but in this context it has me wondering.
In other words, this looks to me to be a deliberate *business decision* by Pubpub not to support anyone other than their own installation. I imagine because (in their minds) that would make the “others” competitors. So beware of installing PubPub for your own use – it appears they will probably see you as competitive to their interests.
If core tech is closed AND they don’t support anyone to install the platform then what is ‘open’ other than a type of branding exercise? I’m not the only one that has picked up this oddity, I’ve been approached by a number of folks that have also sensed this issue regarding pubpub.
This in my mind, makes Pubpub a fauxpen (false open) platform. If you use proprietary core, and you don’t want anyone to use your code – then what else can we conclude?
I think this could be solved by disentangling the closed core (which might been quite a bit of dev work actually), and offering assistance to others wanting to install pubpub. Simple really. Some massaging of the messaging on their site (mission etc) to be more direct, and less marketing speak would also help. Pubpub is a good platform, but these issues are (I believe) being noticed by folks less picky than me. IMHO the folks at Pubpub should do something about it as it isn’t a good look and seems to be turning some folks off.
Another issue, but separate to the above, is PressBooks reliance on Prince – a closed source PDF renderer https://docs.pressbooks.org/installation/ (otherwise, PB is based on WordPress which is all open source). It is a pity that the PDF renderer is closed – it actually means PB incurs a cost that they must pass on to their users…given the mission to help resource OER (who typically have few expendable resources) folks that seems a little strange. To make it worse, the output from prince doesn’t look much better than what you can get from open source products that have been around for 20 years – eg wkhtmltopdf. If you look at the PressBooks guide (https://opentextbc.ca/pressbooks/open/download?type=print_pdf) in PDF, tell me what is different to this book published in 2007 using wkhtmltopdf – http://archive.flossmanuals.net/_booki/audacity/audacity.pdf
I mean … seriously…. why use a proprietary app? Absolutely no reason. It is a little bewildering. Why choose a closed app when there is no need, passing the cost on to your under-resourced users for a critical part of your tool chain? I don’t get it.
Maybe it is part of their business plan too. I don’t know. I can’t really work out why they would do this. The best guess might be that by using a proprietary app they have to pay for they can then justify charging for PDF creation + their own overhead. This might be true because the PDF are generated automatically – so not really any hard costs involved a part from the license cost of prince. I believe PB charges $100 (https://pressbooks.com/self-publishers/) for PDF generation while a server license for prince is $3200 for a server or the academic discount is $1900 (https://www.princexml.com/purchase/). Given that, the $100 PB charges for PDF feels pretty inflated. Another odd business decision if their model is to support the under-resourced.
I don’t think many people (unlike the pubpub issue above) notice this issue, it probably doesn’t effect anyone’s sense of what Pressbooks is trying to achieve and the good work they are doing in OER, but it annoys me a lot as I can’t see why they have to use a closed source renderer when plenty of open ones are available (disclaimer, yes yes I founded pagedjs. They are welcome to use it, but if not I’m also not bothered. I’m more bothered that they are using prince in the first place. What can I say? After years of working in open source these things annoy me). To be clear, I don’t think PB are playing fauxpen games. They used to do this – for a long time PB did not release its source code (despite being based on WordPress which was already open source). That was annoying. But to their credit they do release their source now, and they do call out in their readme that they use a closed source app as part of their PDF toolchain. So I don’t see PB as playing fauxpen games currently, I’m just annoyed by their unnecessary choice of a closed source component for this (important) part of their app.
These are two issues that kind of taint the landscape of open in publishing IMHO. They shouldn’t really bother me but occasionally things like this irk me enough to spend a few mins jotting it down here…
The following article is written by a chap (Mike Shatzkin) who I find very little to agree about when it comes to publishing. Oddly he just wrote this article that argues for ‘enterprise publishing’ as a force for change, and an important trend. As it happens this thinking, which I argued for many times over the years, is how Book Sprints has been operating within for the past 14 years. As it also happens, folks like this author have been pretty dismissive of these arguments in the past which makes it interesting that the tone of some of them is changing. Mike Shatzkin positions himself as a kind of leader of the mainstream, so I’m interested in who picks up on the opinions reflected in the article he wrote.
However, what the author of the below article doesn’t quite get yet, is how this trend changes the process of producing books. As I stated in 2014
“issues of voice, of knowledge production, of collective ownership and participatory workflows and concepts will come up in future discussions.”
https://networkcultures.org/digitalpublishing/2014/05/27/adam-hyde-books-are-evil-or-towards-a-collaborative-production-model-of-books-using-free-software/)
I’m more of the opinion that this movement isn’t just a placing of publishing ‘somewhere else’ as suggested by the below article, but there is a lot of opportunity to deconstruct publishing and authorship and right the many wrongs (capital P) Publishing has maintained when it comes to the proprietorship of knowledge, its construction, and its authority. I doubt the author would arrive at this as they are a pretty mainstream commentator. Nevertheless, the following is an interesting read.
So, at Coko I’ve pondered, designed and delivered several major technologies. Along this road I’ve been scoffed at a lot when I’ve advocated for each of these approaches, but then we delivered them.
I’m thinking of things like a typesetting engine – Pagedjs. No one in their right mind opts to commit time and resources to building a new typesetting engine. Particularly one with a wholely speculative approach. But now we have something astonishing in Pagedjs and the results speak for themselves. We can now achieve ‘InDesign level’ output – as per this demo:
I’m also thinking of Wax – a web based word processor. We needed a word processor capable of delivering the functionality and performance publishers get from Word. And we did it. It is also an editor that works with a ‘HTML-compliant’ data structure. When I advocated for this approach 15 years + ago I was not taken seriously. To be fair, the tech at the time wasn’t up to it. But now it is and we have done it. Not only that, the extensible framework is now going in directions that are fascinating including plugins for the generation of question models for textbooks, test banks etc.
I’m also thinking of PubSweet – the framework for building publishing platforms. When we announced this approach most folks thought we had bitten off too much. We had to bet on parts of the stack that were as yet unproven bets. But it paid off. We did it. We now have a dozen or more platforms built on PubSweet – https://coko.foundation/product-suite/.
That and XSweet – a high fidelity MS Word to HTML converter. Which sounds simple, but the thinking behind it reflects an usual but effective approach.
And then there are many platforms including Editoria (shown above in the video) and the new platform Kotahi – which is a hard platform to describe because it simultaneously enables folks to pursue traditional journal workflows, while enabling whole new ways of working.
While we have been building all of this we have taken unusual approaches to everything. We have had some failures – our first version of Wax bet on the wrong third party libs. But on the whole we have taken bets and they have come in well.
One small new bet in the making is with our new product – Flax – it is a publishing front end built on an existing static file CMS called Eleventy. It is a sane approach in our opinion, but probably for many in the publishing sector it looks like an odd choice. It might seem to ‘low fi’. But we believe that technology can fulfill a need right now at low cost. It is easy to maintain and flexible. It doesn’t yet have everything we need, but that hasn’t stopped us from making successful bets before.
So… Flax is, IMHO, a small bet. I think it is low risk. A bigger bet is our intended approach for producing JATS.
JATS, Journal Article Tagging Suite, is a necessary evil. I’d actually argue it is *unnecessary* and evil. But many folks still need to produce if for various archival and data-transferal (eg migration) purposes.
The way this problem is usually solved is to either build your own XML editor, or throw the content over the wall to a publishing vendor to convert the (usually) MS Word files to JATS.
Our approach is going to be different. Essentially it will take HTML and go through what folks sometimes call ‘up conversion’ – that is a process where you try to go from a less structured document format, to a more structured document format. In this case we will go from an HTML-compliant format, to structured JATS.
How will we get there? Well, Kotahi, (as above) ingests docx into the platform via XSweet. It is then capable of being edited in the platform via Wax. In addition to this, we have all the submission data captured in known blocks through submission forms in Kotahi.
So, we know what the article structure is, in a basic hierarchical form (headings etc) and we know what blocks of data (from the submission form) are. We know what the author information is, for example, from the submission form.
So, to get to JATS, which more or less requires us to add:
We will enable the adding of these to the ‘HTML-compliant’ document via wax. To do this we will add the ability to highlight blocks to add the block level structure, and then we will enable the drag and drop placement of the nested blocks from the submission form. This keeps the whole approach firmly within the ‘WYSIWYG’ approach. Selecting blocks and drag and drop… something any publisher can do.
Its not an approach I see advocated for. But it is very doable and we will go down this path.
The advantage is that it puts the tools for producing JATS in the hands of the publisher. So small publishers can do this themselves without knowing anything about JATS. Larger publishers with larger volumes who still work with vendors can also use this production tool as it will be integrated into Kotahi. So it will be a place where the vendor enters into the system and works with the publisher to produce the JATS. I expect this will produce greater turn around times and higher transparency.
Wendell Piez and I did some thinking about this some time ago. Now it is time to try it out. To do this we will be partnering also with Amnet Systems.
Why is this a better solution than an XML editor? Well, the approaches I have seen where folks use an XML editor is that you must already have XML to load into it. So you must get from where you are to XML, and then use the editor. The approach I’m advocating is that you just start with a HTML-compliant hierarchical structure, and add additional structure and data to it progressively – without needing to know anything about XML.
The question is, why hasn’t this approach been tried before? It might have been tried, if you know of it let me know. But essentially I think there are a few issues that have prevented this kind of approach and it all comes down to the background thinking.
Generally folks have considered the creation of XML to be a complex problem, requiring complex solutions. Need XML? Ask the XML experts how to do it. What will they say? Get a tool that manages XML. This is ‘XML thinking’. It doesn’t allow for out of the XML-box thinking. It is also overly complex.
Next, folks think of XML as a file. But XML need only be a file at export time. There is no need for all the assets that go into creating that XML to be present only as an XML file. This is ‘file’ thinking, and prevents folks from seeing the next thing…
Journal systems are exactly that – systems. They contain both the article and the submission data. So you have all the things you need to create the XML within the system. So just munge the data together at the right moment by bringing all those elements within the system together. This solution requires thinking of how to leverage a journal system NOT how to manage a separate XML editor or XML creation process.
Anyways…that is what I have observed. I am sure there are many folks that won’t take this approach seriously. Its ok, we will do it anyways.
Tally Ho!
