INK 1.2 is out. Details here.

Publishing Innovator. Surfer. Ponderer. NZer.
INK 1.2 is out. Details here.
While Yannis and Christos have been in San Francisco they worked on a number of features that will appear in the soon-to-be-released Editoria 1.1
The two standout features include:
The automagic book builder built primarily by Yannis enables a user to populate the structure of a book automatically from a directory of MS Word files. Essentially, from the book builder component the user can click ‘upload word files’ and a system dialog opens. They can navigate to a folder on their computer and select the files they wish to use to create the book. Editoria then sends all these files to INK to convert to HTML, creates the structure of the book, and populates all the chapters and parts with the right content. At this moment it ‘knows’ which MS Word file is in the front/body/back matter and whether it is a part or a chapter by the file name. We will add a config so the rules regarding what a file is called and where in the book it lands can be determined per publisher or (perhaps) per user.
This feature means that a production editor can simply ‘point’ Editoria at a directory of MS Word files, which is what they are used to working with, and without doing anything else other than press ‘upload’ the book will be built for them in the correct structure (assuming they named everything right). It’s a lot less work than uploading every file individually.
The second feature is a Diacritics interface for the editor. This rather nicely made by Christos so that you can have per-publisher assigned special characters categorised and listed in a simple interface (opened from the editor). That is in itself interesting as it might lend itself to other options like a special character ‘favorites’ list etc…but two other elements add some elegance to the implementation, the first is a simple checkbox that will determine if you leave the Diatrics dialog open or if it closes automatically once a character is placed. The second is that the user can search through the Diacritics with key words. For example you could type ‘dash’ to get a list of all the dash characters (m-dash etc), or typing ‘turned g’ would give you the result: ᵷ
We observed that copy editors search Wikipedia for the special characters they want. Now they can search within the editor interface, using the naming conventions they are used.
The Diacritics feature is, of course, a wax-editor component….which is used as the editor in Editoria. We are working a lot on Wax and it will become a substantial product in its own right.
We are currently building multiple systems which are all component based. PubSweet, for example, contains three softwares (which you can find here):
In addition, Editoria, is built on top of PubSweet and it consists of at least the following standalone components (which you can find here):
To the end user these platforms appear ‘as one thing’ but in effect, they are made of multiple standalone moving parts which are mostly all legitimately within the same namespace (editoria-*)
Which brings about a few interesting questions – the first is regarding versions, the second about what exactly it is that we are building.
First – how do you version something like Editoria when the ‘bona fide’ Editoria repository is ‘just glue’ code that brings the other Editoria components together? Each of those components has different version numbers that advance in a rather traditional semver way, but the actual Editoria glue code won’t move much at all. Hence we need to find a good way to think about versioning that communicates forward movement to the outside world.
So, for this situation, we have decided to simply advance the minor number of the version for each significant feature (or group of features) added to the system at large. So, for example, Editoria is now at 1.0. When we add the multiple MS Word import and the diacritics interface we will advance it to 1.1 – this is kind of arbitrary but as long as we correctly version the other components I think its the best way to do it.
xpub offers a different challenge. xpub started as the working title of journal platform (Manuscript Submission System) built on top of PubSweet. However, we quickly realised that xpub is actually more of a ‘ecology’ of components that can be used to build a journal workflow than it is a journal platform. Our thinking is moving this way because we aren’t really building platforms so much as components that can be assembled into platforms. So we don’t wish to have a single ‘xpub journal platform’, rather we will build many components (just like Editoria) and name them with the xpub-* prefix eg. xpub-dash, xpub-submission etc. These components can then be ‘glued together’ to make the journal platform of your dreams…
Just to make it more complex….we are also breaking down what we now call components into UI libraries…so we will also have an xpub-UI-library which contains ‘sub components’ that are then assembled into a component. For example, what we would call xpub-dash is a component, but it is assembled from several xpub-UI-library sub-components like ‘upload button’, ‘article list’ etc…
When we assemble xpub parts into a journal we will then name it something like xpub-collabra (the first assemblage we will be working on)…
So…you can see the difficulty! How to think about what it is you are building, and, how to version something like xpub-collabra when it is really nothing but the glue code which connects a lot of separate xpub-components which in themselves are assembled from xpub-UI-library sub-components!!!!
Tricky!
Below is an image from a whiteboard session conducted some weeks ago with myself, Alf Eaton and Dan Morgan.
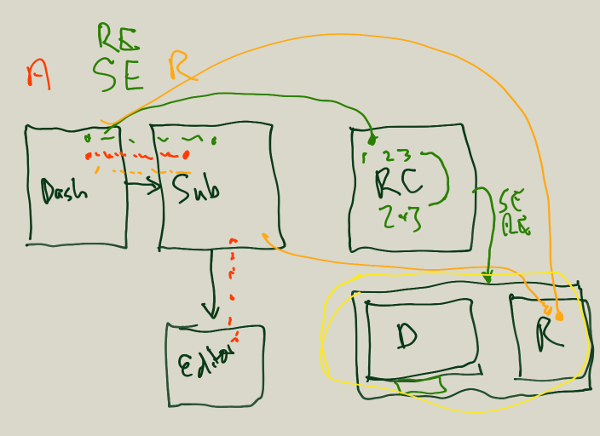
It shows a number of roles (author, Reviewing Editor, Senior Editor, Reviewer) and their path through a component-based Manuscript Submission System built on top of PubSweet.
The components shown above are:
We are currently building this out. Of course we have this broken down in a little more detail! Including the above to give some insight into the starting point of a typical process of mapping workflows onto a component based system. I’ll write more about this at another time.
Yannis and Christos, the two Coko developers that have been working on Editoria from the beginning, have been in San Francisco for 2 weeks.

They are super people to work with. I met Yannis in the back of a taxi on the way to a mutual friends wedding in Montemvasia (Greece). It was a cool wedding, and somewhere along the way I realised he was also a great programmer. I eventually talked to Yannis about maybe working together on Coko and he was keen and also introduced me to Christos.
So, last week we did a number of presentations together to various people in San Francisco. Showing Editoria and talking about the technology behind it (INK and PubSweet).
We have also been taking the time to work at UCP together with Kate Warne and Cindy Fulton. I facilitated Kate and Cindy over this last year to design Editoria, so we took the opportunity to spend more time together and do some faster iterations.

This week Kate and Cindy iterated on ideas for an uploader – essentially they wanted to upload an entire directory of MS Word files at once into Editoria and have those files automatically populate the structure of the book. Yannis and Christos had a demo the next day and demonstrated it. We were all pretty happy with the result.

In addition, we met with, amongst others, many UCP production staff and demonstrated and discussed Editoria.

We discussed where it is now and where it is going and there were very many fantastic questions and pointers on things we need to keep in mind going forward. It was also a very cool meeting.

Finally, we are going to build out the diacritics interface, the multiple uploader, and a few other small bells and whistles to production ready code and test next week with Kate and Cindy before Yannis and Christos return to Athens on Thursday. All round, a cool couple of weeks. These weeks also reflect the ‘Coko way’ of working – having as many conversations as possible with those interested in the technologies and processes we employ, and designing systems with the major stakeholders (people who will use the system). Not only does this produce better software, its way more fun.
Cool to see Ghost at 1.0. I like Ghost as a blogging system, not to use, but because I love seeing a system that has made some design decisions and stuck to them. In Ghost the takeaway design decisions are minimalism and markdown. They have seen that through to a harmonised, coherent, system and huge congratulations to them for that.
I haven’t changed my opinion on Markdown! but its great to see well made and well thought-through products in the open source world even if you disagree with some of the decisions. Congrats to the Ghost team!
I’ve been pondering innovation a lot recently. I think this has come about because of a whole bunch of 1.0 releases that the Coko team has produced over the last weeks. There is a lot of publishing and software systems innovation popping out of those releases – Editoria 1.0, INK 1.0 (now 1.1 already), and PubSweet 1.0 (alpha – beta coming soon).
However, I want to focus on PubSweet because what it offers the publishing sector might be easy to overlook and what it offers is rather an astonishing rewrite of the legacy landscape we currently occupy.
You may wish to grab a sneak peak at the beta, and yet to be promoted, PubSweet website (wait a few weeks before trying PubSweet, we are in alpha and need to test both the docs and the alpha release). The site looks beautiful which is a testament to the hard work put into it by Julien Taquet and Richard Smith-Unna.
The layers of innovation happening in PubSweet is pretty remarkable and this is mainly a product of the initial vision and the fantastic work Jure Triglav has put into architecting an exciting software to realise this vision. You can read a little more about this here.
While I could enumerate the innovations, which include Authsome (Attribute Based Access Control for publishing), a component based architecture (back end and front end) and many others – I want to focus on the effect of PubSweet.
PubSweet, as the website now states, is an open toolkit for building publishing workflows. What does this mean exactly? Well to find out we need to look at two features in particular in a little detail:
There are two features of the PubSweet ecosystem that illustrate this statement best:
First up – the PubSweet component library.

Just what are you looking at on this page? Well, PubSweet is not a publishing platform in the way we typically talk about these things. Typically a publishing platform is one big monolith or, at best, a partially decoupled, platform that prescribes a workflow. Or, in the case of Aperta (which I designed for PLoS), supports a variety of possible workflows after some additional software development.
However, PubSweet takes this idea that I designed into Aperta, a whole lot further. PubSweet is not a platform but essentially a framework/toolkit that you can use to build any kind of publishing platform you want. The way to do this is by assembling the platform from components, hence the component library.
The library consists of both back and front end components, since PubSweet can be extended ‘on both ends’. Hence the INK-backend component you see in that library enables the system to interact with INK for file conversions etc. This component is not visible to the user but extends the overall functionality of the platform ‘under the hood’. While the Editoria-bookbuilder component is the bookbuilder interface for the book platform Editoria.

And the wax-editor component that you see further down the page is the best of breed editor we built on top of Substance.
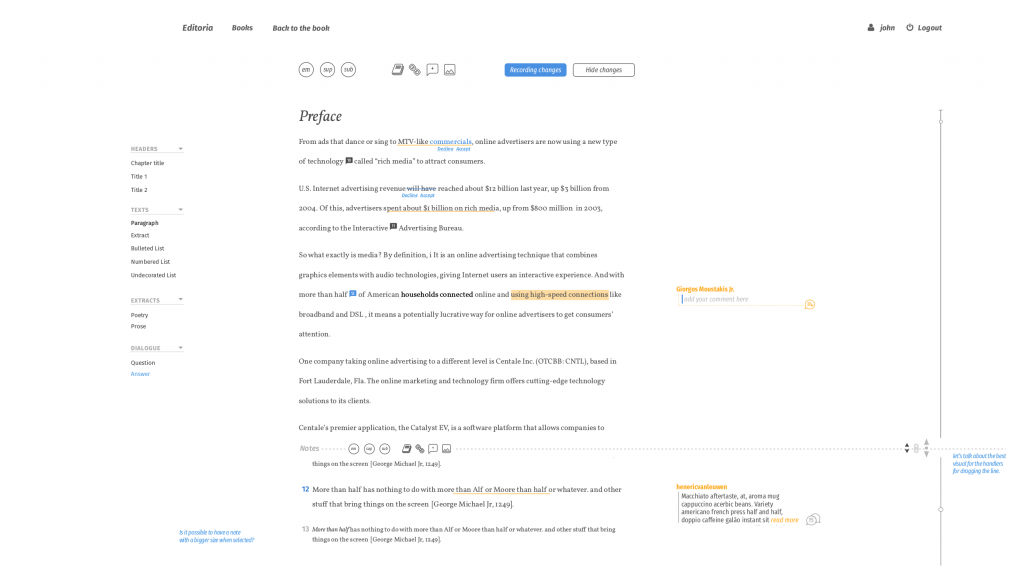
What does this mean? Well, it means that you can assemble the platform you want out of all these components. No more building the platform for book production (eg booktype etc) or the Manuscript Submission System (eg Aperta), rather you can take the components you want and assemble them as you like. Not only does this support a tremendous number of use cases, but it has the following knock on effects:
This is tremendously exciting. It’s so exciting I can hardly speak right now! No hyperbole intended, I can literally feel the adrenaline flowing through my veins as I write this.
So…the second feature of the PubSweet universe that is going to blow peoples minds is the PubSweet CLI. So, CLI is an acronym for ‘Command Line Interface’. Geeky stuff. I won’t go into the full details of the PubSweet CLI as it is intended as a tool for the technically minded, but the item that will probably interest and excite you is scheduled for the 1.2 release. And that is – single line platform installs.
Yep…just imagine. If you want to try out a particular configuration of components which someone else has put together as a platform, then you need only run one command to install it.
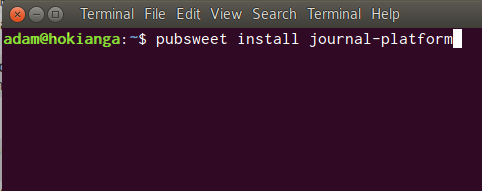
Imagine something like:
pubsweet install editoria
or perhaps…
pubsweet install journal-platform
or…
pubsweet install open-peer-review-journal
…can you imagine?…. it is currently ridiculously difficult to install publishing platforms even if you have the code (most publishing platforms are closed source so you don’t even have the option). But… a single command line and you will have the system you want up and running…
Interestingly, this has been part of the vision from the beginning (notes from the early sessions I had with Jure, and Michael and Oliver from Substance can be found here), but it was almost too exciting to speak out loud in case we couldn’t get there. Now it is within striking distance and we should see this functionality within some weeks.
Even better is that this is all Open Source. So a big vendor won’t be able to buy this ever. They can use it, provide services on it, but they will never be able to have it all exclusively to themselves. We aren’t going to, nor can we, sell PubSweet to some proprietary vendor so don’t even bother asking. It is free for now and forever, and this might just be the most disruptive part of the whole plan.
As much as I have innovated, I also like to support innovation. I’ve done this throughout my career but in recent years I’ve been extremely lucky to have had the resources (both time and finances) to play a more substantial role in supporting some pretty interesting, and extremely innovative, projects.
First, with my Shuttleworth Fellowship the first thing I invested in was support for Substance.io. We then followed this up with additional funding from Coko. The aim here was to support, what I believe to be, a critical player in the open source publishing ecosystem.
Next Coko also helped, both financially and with additional support and advice, Nokome Bentley and the wonderful Stenci.la project. Nokome has since received a grant from the Sloan Foundation. Which is pretty awesome and very much deserved.
And most recently Coko has supported ScienceFair financially so Richard Unna-Smith can work half time on the project while continuing to work with us on PubSweet. I wrote a little more about Sciencefair here.
In addition, Coko has helped the bring together of a bunch of very interesting open science/open source/open publishing projects under the umbrella of the (still very new) Open Source Alliance for Open Science (I facilitated the first OSAOS meeting in Portland a few months ago). I’m hoping OSAOS will foster a lot of cross-collaboration and innovations will appear out of this mixing of minds.
Anyways, innovation is really about creating a culture of possibility and an ecosystem of connected thinking as much as it about supporting individual projects/approaches, and I’m very proud of having played a part in helping support some of these people and bring some very smart folks into conversation with each other.
Photos from the first Coko Surf Club meeting! We had a blast at Linda Mar, 20 mins from San Francisco. Awesome day, featuring special Coko Surf Club t-shirts!

















Recently we released INK 1.1, it is a great milestone to arrive at, just a few weeks after 1.0. Charlie Ablett, the lead dev for INK, has been working very hard nailing down the framework and has done an amazing job. It is well engineered and INK is a powerful application. You may wish to ink1 if you wish to learn more about where INK is now.
For the purposes of the rest of this post (and if you don’t wish to read the above PDF) I should provide a bit of background, cut directly from the PDF:
INK is intended for the automation of a lot of publishing tasks from file conversion, through to entity extraction, format validation, enrichment and more.
INK does this by enabling publishing staff to set up and manage these processes through an easy to use web interface and leveraging shared open source converters, validators, extractors etc. In the INK world these individual converters/validators (etc) are called ‘steps’. Steps can be chained together to form a ‘recipe’.
Documents can be run through steps and recipes either manually, or by connecting INK to a platform (for example, a Manuscript Submission System). In the later case files can be sent to INK from the platform, processed by INK automatically, and sent back to the original platform without the user doing anything but (perhaps) pushing a button to initiate the process.
The idea being that the development of reusable steps should be as easy as possible (it is very easy), and these can be chained together to form a chain (recipe) that can perform multiple operations on a document. If we can build out the community around step building then we believe we will be able to provide a huge amount of utility to publishers who either can’t do these things because they don’t know how or they rely on external vendors to perform these tasks which is slow and costly.
A basic step, for example, might be :
Which is pretty useful to many publishers who either prefer to work on an HTML document to improve the content, or have HTML as a final target format for publishing to the web. Another step might be :
Which is useful in a wide variety of use cases. Then consider a step like:
That would be useful for many use cases as well, for example, a journal that wishes to distribute PDF and HTML.
While these are all very useful conversions/validations in themselves, imagine if you could take any of these steps and chain them together:
So, you now have a ‘recipe’ comprising of several steps that will take a document through each step, feeding the result of one step into another, and at the end you have PDF and HTML converted from a MS Word source file. Or you could then also add validations:
That is what INK does. It enables file conversion experts to create simple steps that can be reused and chained together. INK then manages these processes in very smart ways, taking care of error reporting, inspection of results for each individual step, logs, resource management and a whole lot more. In essence it is a very powerful way to easily create pipelines (through a web interface) and, more importantly, takes care of the execution of those pipelines in very smart ways.
I think, interestingly, conversion vendors themselves might find this very useful to improve their services, but the primary target is publishers.
In many ways, INK is actually more powerful that what we need right now. We are using it primarily to support the conversion of MS Word to HTML in support of the Editoria platform. But INK is well ahead of that curve, with support for a few case studies that are just ahead of us. For example, INK supports the sending of parameters in requests that target specific steps in the execution chain, and it supports accounts for multiple organisations, and a few others things that we are not yet using. It is for this reason that we will change our focus to producing steps and recipes that publishers need since it doesn’t make sense to build too far ahead of ourselves (I’m not a fan of building anything for which we don’t currently have a demonstrated need).
These steps will cover a variety of use cases. In the first instance we will build some very simple ‘generic steps’ and some ‘utility steps’.
A Utility Step is something like ‘unzip file’ or ‘push result to store x’ etc…general steps that will be useful for common ‘utility operations’ (ie not file processing) across a variety of use cases.
A Generic Step is more interesting. Since there are a lot of very powerful command line apps out there for file processing we want to expose these easily for publishers to use. HTMLTidy, Pandoc, ebook-convert for example, are very powerful command line apps for performing conversions and validations etc. To get these tools to do what you want it is necessary to specify some options, otherwise known as parameters. We can currently support the sending of parameters (options) to steps and recipes to INK when requesting a conversion, so we will now make generic steps for each of these amazing command line apps.
That means we only have to build a generic ‘pandoc’ step, for example, and each time you want to use it for a different use case you can send the options to INK when requesting the conversion.
The trick is, however, that you need to know each of these tools intimately to get the best out of them. This is because they have so many options that only file conversion pros really know how to make them do what you need. You can check out, for example the list of options for HTMLTidy. They are pretty vast. To make these tools to do what you need it is necessary to send a lot of special options to them when you execute the command. So, to help with this, we will also make ‘modes’ to support a huge variety of use cases for each of these generic steps. Modes are basically shortcuts for a grouping of options to meet a specific use case. So you can send a request to run step ‘pandoc’ to convert an EPUB to ICML (for example) and instead of having to know all the options necessary to do this you just specific the shortcut ‘EPUBtoICML’…
This makes these generic steps extremely powerful and easy to use and we hope that file conversion pros will also contribute their favorite modes to the step code for others to use.
Anyway… I did intend to write about how INK got to where it was, similar to the write up I did about the road to PubSweet 1.0. I don’t think I have the energy for it right now so I will do it in detail some other time. But in short … INK has its roots in a project called Objavi that came out of FLOSS Manuals around 2008 or 2009 or so. I’ll get exact dates when I write it up properly. The need was the same, to manage conversion pipelines. It was established as a separate code base to the FLOSS Manuals book production interfaces and that was one of it’s core strengths. When booki (the 2nd gen FLOSS Manuals production tool) evolved to Booktype Objavi became Objavi2. Unfortunately after I left the conversion code was integrated into the core of Booktype which I always felt was a mistake, for many reasons of which I will leave also for a later post. So when I was asked by PLoS to develop a new Manuscript Submission System for them (Tahi/Aperta) I wanted to use Objavi for conversions but it was no longer maintained. So I initiated iHat. Unfortunately that code is not available from PLoS. Hence INK.
The good news is, this chain of events has meant INK, while conceptually related to Objavi and iHat, is an order of magnitude more sophisticated. It fulfils the use cases better, and does a better job of managing the processing of files. It also opens the door for community extensions (Steps are just a light wrapper, and they can be released and imported as Gem files into the INK framework).
At this moment we are looking at a number of steps, still deciding which to do first so if you have a use case let us know! A beginning list of possible steps is listed below:
Utility steps
Generic Steps
Steps