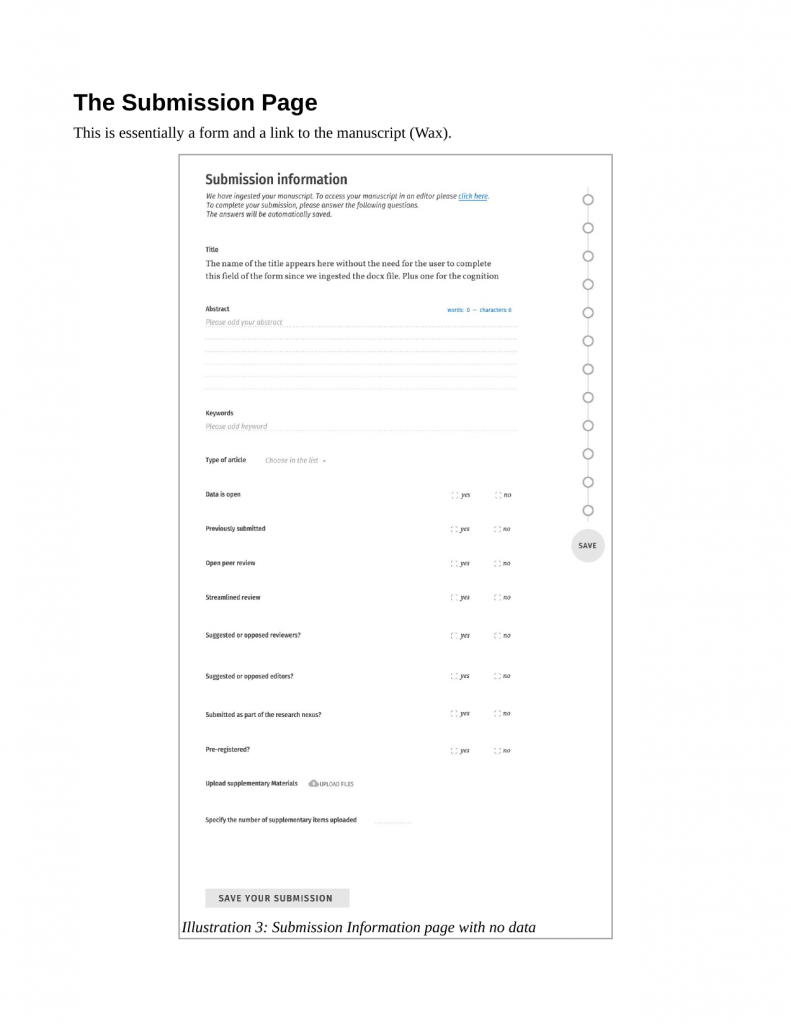
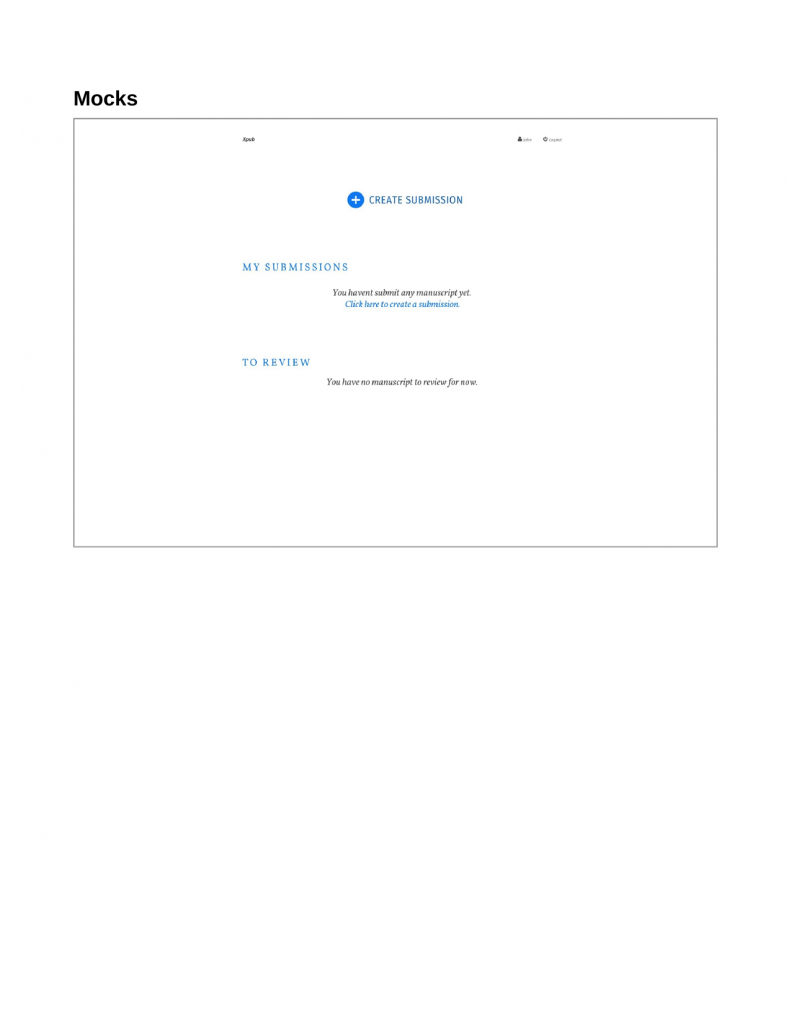
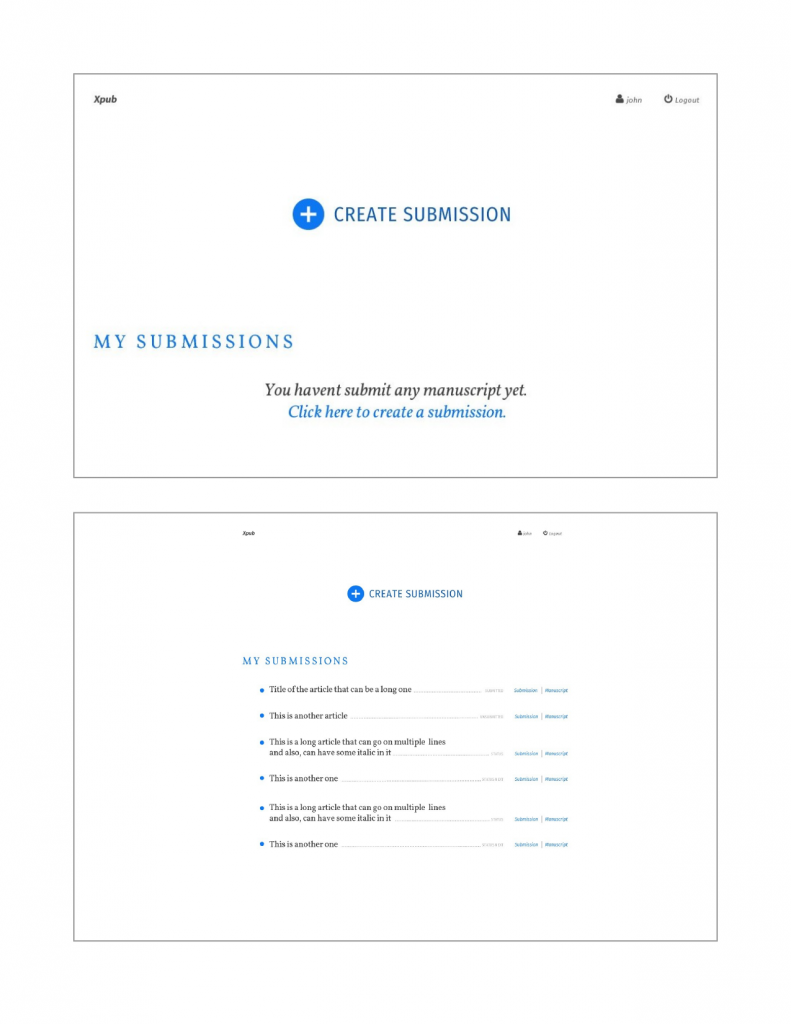
I’ve been in the business of trying to work out how to get Publishing (capital ‘P’) into the web. From the start, there have been some ‘big ticket’ items that have needed to be solved. Some are more urgent than others, but by and large we are cracking these nuts one by one. I have considered for a long time the big 4 to be:
MS Word to HTML conversion
an open source web-based word processor
paginated output via the browser to print-ready copy
in-browser designer
1,2 an 3 are the ‘now’ critical items, number 4 is necessary but a little further down the line. Thankfully, at Coko we are solving these first 3 problems. To solve (1) we are building XSweet, a comprehensive (open source) XSLT conversion suite for converting MS Word to HTML. We are also building Wax to solve (2), Wax is an open source web based word processor based on the Substance.io libs. And for (3) we are using Vivliostyle for in-browser rendering. Number 4) is still on the cards.
Interestingly, the pagination technology (3) might need re-evaluating since pagination will eventually be required for the editor and the in-browser designer.
While pagination inside a web-based processor is not critical for publishers, it is critical for authors and small offices etc and if we are going to get publishers to use a web-based word processor then it would be better that they share infrastructure rather than sit on their own island of technology ie. eventually we need authors to use these tools too. By sharing infrastructure I don’t mean they need to use exactly the same tools, they just need to use compatible tools. So, eventually, we need to migrate authors into the web. It is not critical now, but over time, as the workflow for authors and publishers inevitably becomes more integrated, it will turn out to be necessary.
For in-browser design we need pagination support also so we can work off a single source for the content and then design in the browser to output to the various formats publishers need. Think Gimp or InDesign in the browser. It’s not as far away as it might sound, but to do this we need to be able to paginate inside the browser and have that update with live style changes to CSS.
So far, we are solving the big ticket issues 1-3, but for the next stage of changes we may need to change the tools we use for pagination so we can live-update content and styles and reflow in an editor and in-browser designer. That may mean we to start looking for a different pagination solution.
It is a discussion in the Node issues in Github about their Code of Conduct. One developer, with the handle ‘binoculars’, also known as Barrett Harber, is a developer from the Center of Open Science and objecting to the idea of Codes of Conduct. To quote him:
I think the concept of having and effectively enforcing a Code of Conduct is fundamentally flawed…I think you’re alienating a much larger portion of your potential and current contributor base by handing over control to the wrong-think police…Obviously, this is not avoiding conflict. It’s creating conflict. Case in point, this conversation. We wouldn’t be having it if it didn’t create conflict.
and the following two bald statements which are absolute doozies:
I’m not concerned with people’s feelings….
…and…
There’s no definition of harassment.
jeeez……it is one of those amazing moments when the speaker doesn’t realise that what they are trying to say is, as the words come out of their mouth, making exactly the opposite point to everyone in the room.
Although this person seems to have a problem with CoCs in general, the critique is directly pitched at the Node Code of Conduct which is particularly hard to understand given that the Node CoC is pretty light, easy to understand, and (I would say) rather standard and non-controversial.
The conversation is blossoming a little around the net including here.
My idea of a good day in. Despite, or maybe because of, living in Silicon Valley (San Francisco is really part of SV these days), I think my media diet is devolving.
Recently, I have been involved in some discussions around what tools to choose for open communities. This came up with regard to the Open Source Alliance for Open Scholarship (links to the new website coming soon!).
One argument that always comes up with these kinds of discussions, and I have been involved in many, is that we should use platform X because ‘thats where the people are’. Because open source has lost in the platform game (but its not too late) this argument almost always points to a closed source platform eg. github, twitter, slack etc
‘Going where the people are’ feels intuitively like a good idea. You want your project to succeed, go where the people are. Hard to argue against that. But argue against that we must, and I’ve started to think a little about how to counter this position better because sometimes, when people get stuck on this argument, there is no budging them.
One thing I have experienced recently that has fed a counter argument is the growing community around Coko. We use Mattermost and Gitlab as our primary web spaces for community and collaboration. What I notice with our gitlab, for example, is that when you open it up in the browser it looks like Coko. It looks like a home for a variety of connected and interesting projects that all revolve around Coko’s mission to reshape publishing. It is my hope that this will grow to be even more true over time. If that proves to be the case, then this gitlab instance will be a home (possibly one of many) for a certain approach and certain kind of thinking about how to change publishing. And that there is incredibly valuable because it speaks to the need for your community tools to surface and reflect your communities activities and values.
Coko GitLab
That’s not so easy to do in github. Go to a github org space and it looks like every other github org space. It looks dull. It reflects the identity of github and not of your community. This doesn’t just come down to theming, but it comes down to more subtle nuances such as with gitlab (or similar open source solution), the space is committed only to the things your community is doing. Things that are not connected are not a click away. From a community members point of view its a space dedicated to them. In this day I believe this is increasingly more unusual, important, and appreciated.
Consequently, I use the argument that developing community identity is more important than ‘going where the people are’. Don’t create a space ‘where the people are’, create a space where your people can go.
Ok..Jitsi initial install is easy. Working out letsencrypt is soso documented but also easy, working out how to get desktop sharing working is barely documented.
It works as advertised for Ubuntu. Except, don’t use the stable sources. We couldn’t get them to work with conferences – we could only get 1 person in a meeting which…er… isn’t a meeting! So, instead use the unstable sources, which means don’t use this:
Make sure that if your Jitsi-meet is already using a subdomain (eg. jitsi.mydomain.com) that you add the above subdomains on top of that eg conference.jitsi.mydomain.com not conference.jitsi.com
Now…you need to change a few things. Open the file located at /etc/prosody/conf.d/[YOUR JITSI DOMAIN].cfg.lua, it should look something like this:
Change both secrets to a random string of the same length. The copy the first one to this file /etc/jitsi/videobridge/config where and uncomment the secret, eg:
# sets the shared secret used to authenticate to the XMPP server
#JVB_SECRET=e355kYFm
JVB_SECRET=sjhfss09
Do the same for the second secret by adding it to this file /etc/jitsi/jicofo/config, eg:
# sets the secret used to authenticate as an XMPP component
#JICOFO_SECRET=Ifc7gffV
JICOFO_SECRET=Hjusk78is
Thanks to Juan Gutierrez for working out the above changes to the files.
Letsencrypt
Also easy, except it doesn’t say anywhere how to do it. There is a nice script for it which is already present but you need to find it. On Ubuntu you can find it in /usr/share/jitsi-meet/scripts/
So to get it running do this (as root or using sudo):
cd /usr/share/jitsi-meet/scripts/
./install-letsencrypt-cert.sh
The script should just ask you for a valid email address. Follow the instructions and it ‘just works’. You*may* need to restart jitsi to do that try this:
/etc/init.d/jitsi-videobridge start
Then navigate to your domain prefixed by https and it should work.
Desktop Sharing
Ha..just when you thought it was so, so, easy! It’s actually pretty easy but it’s not well documented. Essentially you have to install an extension in your browser that allows desktop sharing permissions. However this is domain specific so you have to download the extension and configure it, then compile it and then load it into your extensions. This is true for Firefox and Chrome/Chromium. I haven’t tried for Firefox but the following works for Chrom(e)ium.
Next, with your fav text editor open the file in the ‘chrome’ directory called manifest.json, it looks like this:
{
"manifest_version": 2,
"name": "Jitsi Desktop Streamer",
"description": "A simple extension that allows you to stream your desktop into meetings with Jitsi Meet and Jitsi Videobridge.",
"version": "0.1.6",
"minimum_chrome_version": "34",
"icons": {
"16": "jitsi-logo-16x16.png",
"48": "jitsi-logo-48x48.png",
"128": "jitsi-logo-128x128.png"
},
"background": {
"scripts": [ "background.js" ],
"persistent": true
},
"permissions": [
"desktopCapture"
],
"externally_connectable": {
"matches": [
"*://meet.jit.si/*"
]
}
}
You want to edit the last line:
"*://meet.jit.si/*"
to reflect the domain of your jitsi install eg
"*://jitsi.myserver.org/*"
or whatever… don’t put in http or https or anything, just replace the domain information.
Now, you need to compile that extension. Follow these steps:
If you open up your chrome browser go to (in the location bar) chrome://extensions
check the box ‘developer mode’ if it is not already checked
you will see a button ‘pack extension’ appear at the top, click this
click the button next to ‘extension root directory’
browser to and select he ‘chrome’ directory where you have that manifest.json file
click ‘open’
click ‘pack extension’
A new file ‘chrome.crx’ will appear.
Now you need to load that into your extensions, to do that you need to drag the chrome.crx file to the extensions page open in your browser. It will then just appear, by default it is enabled.
Now…you are almost there…you now have to go to your server and make a few changes. These all happen in one file, the jitsi meet config file. Open the file ‘/etc/jitsi/meet/[YOUR JITSI DOMAIN]-config.js’ with your fav text editor.
You need to change these lines:
// The ID of the jidesha extension for Chrome.
desktopSharingChromeExtId: 'put your Chrome extension ID here',
// Whether desktop sharing should be disabled on Chrome.
desktopSharingChromeDisabled: false,
// The media sources to use when using screen sharing with the Chrome
// extension.
By default, there will be no chrome extension ID and sharing is default turned off. Make sure desktopSharingChromeDisabled is set to false, and put your chrome extension ID in between single quotes after desktopSharingChromeExtId.
But… I hear you say…. what is my chrome extension ID? good question… to get this, go back to your browser and in the chrome://extensions you will see an id listed next to your jitsi-meeting extension. It will be a long string of numbers and letters next to the simple text ‘ID:’
Copy and paste that into the config between single quotes, no spaces and exclude the ‘ID:’ bit. Save and exit the config file. You shouldn’t have to restart Jitsi but if you feel like playing it safe restart as per above.
Navigate to your jitsi meeting and it should work under https, show the desktop sharing icon, and enable desktop sharing! Good luck! I’ll be testing out our install in the next weeks and will post here. Oh…if you wish to replace the default jitsi watermark on the top right then replace the file /usr/share/jitsi-meet/images/watermark.png with a transparent png.
(if anyone would like to walk me through how to do the same for Firefox I’d be grateful and I will also publish that info here.).
Update: Sept 3. Juan worked out how to get the extension in the chrome store. Was easy apparently but cost $25USD.
Now if you try our Jitsi and need to screenshare, then clicking on the screenshare icons redirects you to the above Coko plugin in the Chrome store.
If you found this post useful, repay it by taking the time to document a tricky issue you worked through so others can benefit from what you learned! (I’m forever grateful for the amazing stuff I’ve found online in some random blog somewhere that have helped me out of seemingly unique tech gotchas!).
I have tried various open source video conferencing apps. Actually, as it happens my first introduction to open source was through streaming back in the day. Since WebRTC came on the scene I have been excited by the possibility of open source web-based video conferencing. However, the promise seemed to take a while to deliver. I tried many products, the most sophisticated and promising being, for a while, BigBlueButton. But BBB, and other softwares, just seemed so clunky and hard to install, ugly UI etc. We installed and ran BBB for Coko but no one really wants to use it and we had bandwidth issues etc. Sorry to say it, but open source has been lagging behind the closed source world with regard to video conferencing.
I have been keeping my eye on Jitsi for some time. It looks pretty good. But I was caught up with my legacy understanding of such systems and it took a while, also, for Jitsi to evolve. I tried out their demo for a few meetings but it had some lag issues. Of course, trying out a demo ‘for real’ is a bit dumb and I should not have expected anything like you want in a real world production environment. But… I was a little deterred. I also assumed it would be hard to install.
Finally, this weekend I thought I would give it a go…so I started up a digitalocean droplet (a server) – which costs $20 a month and took about 2 mins to get going. I then followed these instructions – https://github.com/jitsi/jitsi-meet/blob/master/doc/quick-install.md. I had a Ubuntu install at digitalocean so followed those steps. But I expected complications…the install mentions it relies on jitsei-videobridge and I thought… I bet this doesn’t work…I’ll have to install some mad java app or something…What do you know…within 5 mins I had a working version of Jitsi-meet! amazing! The process worked as described, basically 3 commands and it was running.
If it works for Coko it is also very interesting because Jitsi on the front end is all JavaScript and there seem to be some react components…which means we could integrate into xpub/editoria (publishing systems) etc…
We will try it out in the next weeks. Expect more info soon!
Currently listening to Hearing Music by Joanna Brouk. Super crazy beautiful. Sparse, drifting tones – synth, flute, piano, field recordings. She is an American composer that died earlier this year. Hearing Music was released in 2016 as a compilation of some of her works previously released on cassette tape. Just amazing.
Also a compilation of hard-to-find earlier releases. Sometimes cacophonous, but mostly eerie and soothing at the same time. A mix of field recordings and almost every instrument you can think of from water drums to French horn and synth. Also fantastic.
Much is going on in the Coko world at the moment and a lot of news coming out soon about various collaborations. Much of the attention has been around xpub, the journal system we have been working on built on top of PubSweet.
PubSweet is, of course, a component based system so you can ‘roll your own’ journal or book platform from existing components. We are making a lot of components for both Editoria and xpub and publishing them for reuse with an open source (MIT) license.
Some of the components we are generating for xpub are coming out of the work we are doing with Collabra, the UCP Psychology Journal. Today the Managing Editor, Dan Morgan, and I met for another session working out the logic of the components and how they fit together.
We started by working through the flow from the perspectives of each of the major stakeholders – Managing Editor, Senior Editor, Handling Editor, Author, Reviewer. We worked out what they each needed to see on the dashboard and then went through their workflow and what they needed from each component.
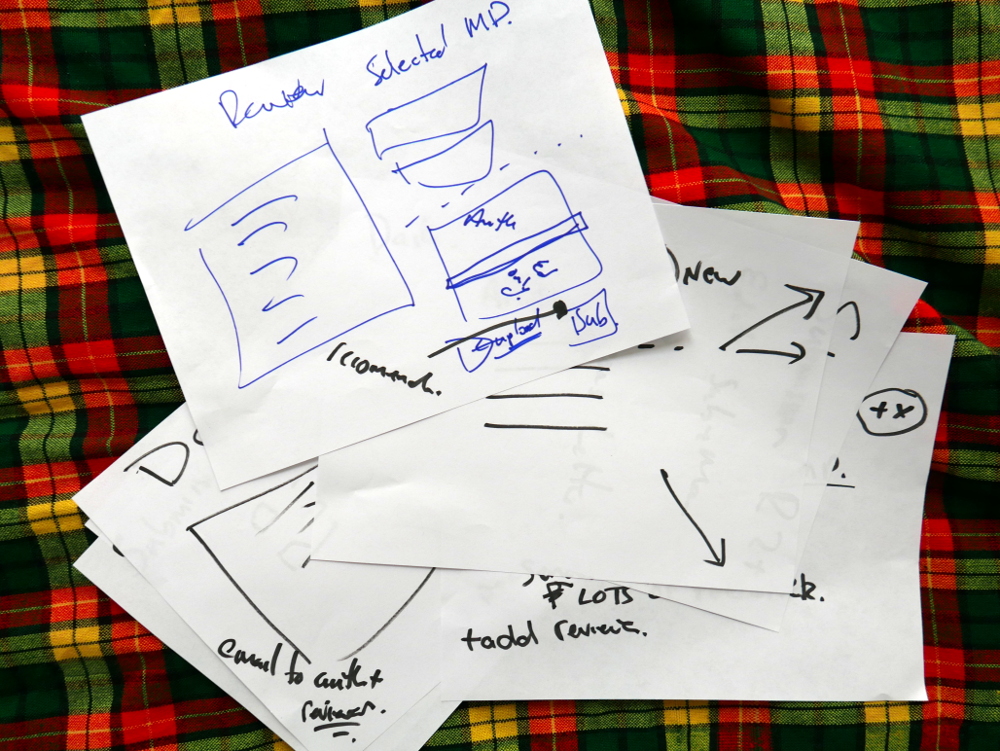
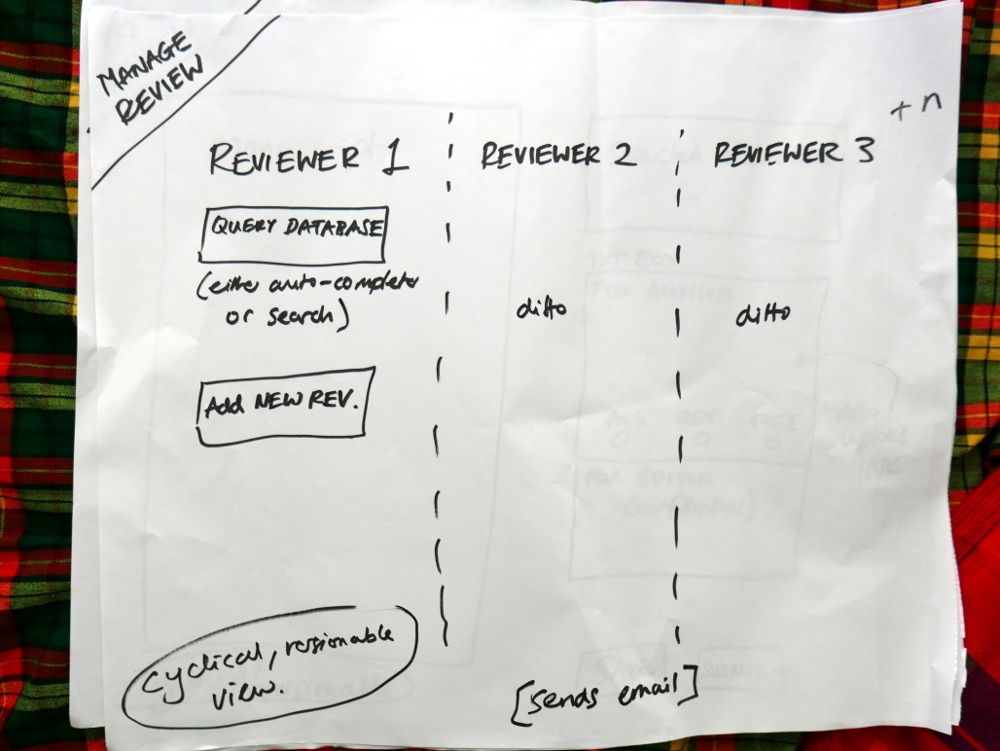
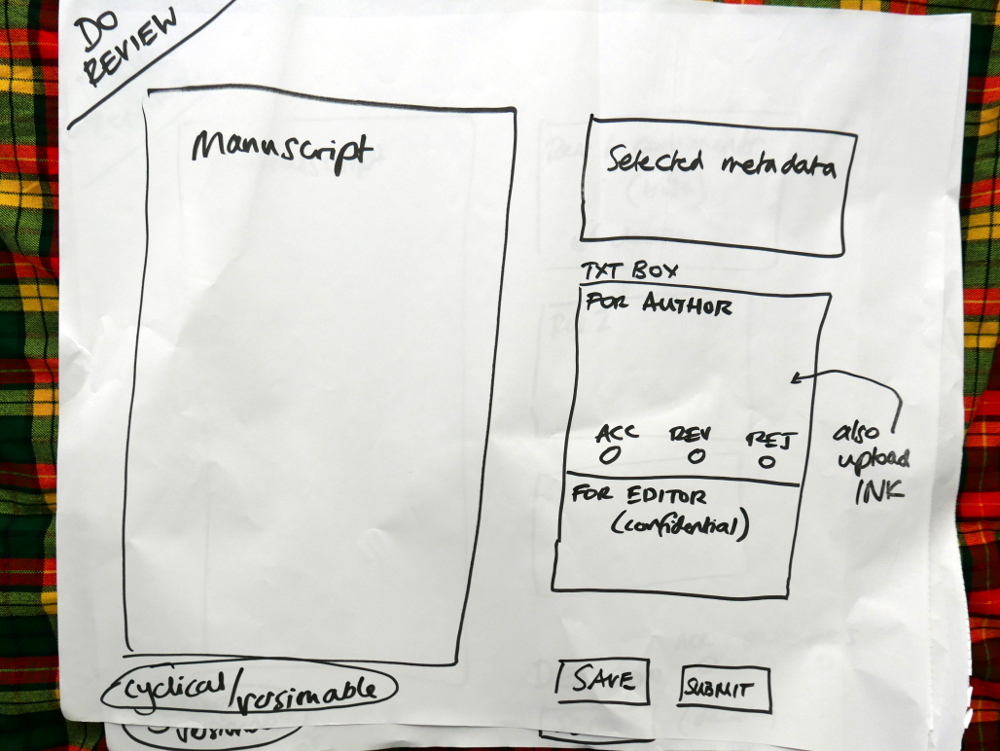
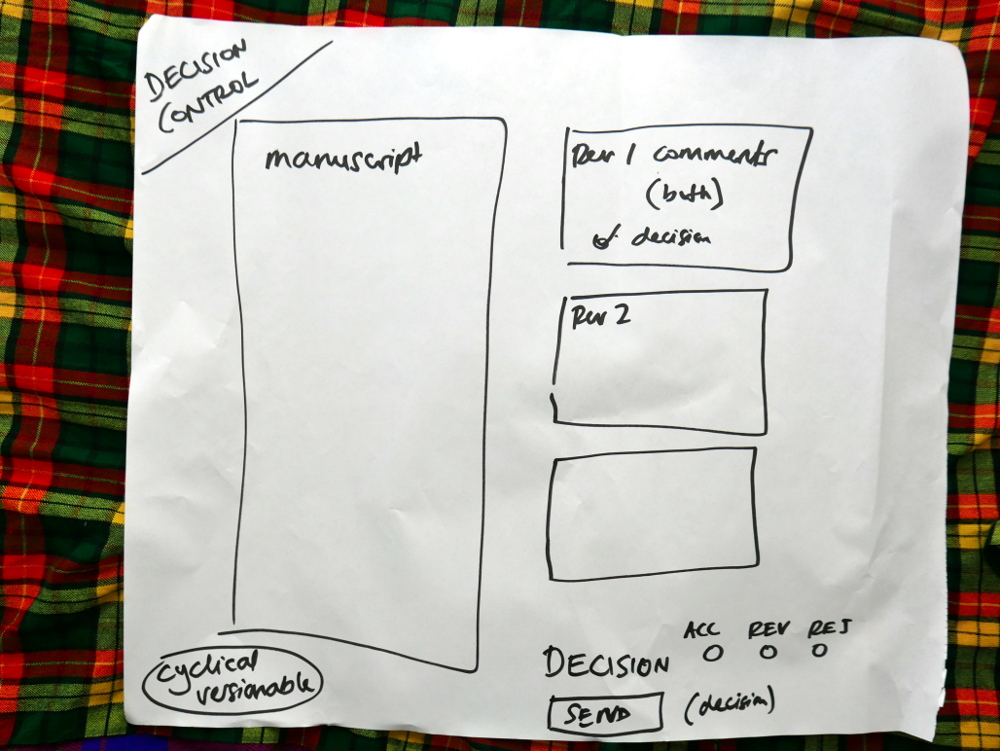
List of what each actor sees on their dashboardMapping out the flow across components.Sketches of components
We then took each of these small mappings and transferred them to larger pieces of paper. Drawing the interfaces in basic form.
Drawing out the components in detail
Each of the diagrams are detailed below.
We had already worked out this structure. Today was about running through the logic from each actor’s point of view. Good news is, the logic held up and validated the architecture. Good news! So, what you see in these pics is more or less what we will build. It is a thin horizontal slice that covers the complete lifecycle of a manuscript going through the Collabra process. We’ll build it and test it, and then layer on additional functionality.
Next I’ll recreate these in digital graphics and add a page of bullet points for explanation. We will then meet with the Coko team and talk it through and start building! It’s a good way to design systems, way better than endless months gathering pages and pages of product requirements. It’s a lightweight and fun process. Software is a conversation after all!
The past two posts I wrote on this topic looked at defining the difference between a text editor and a word processor. The posts in this series represent me ‘thinking out loud’ about what word processing needs to evolve into in the age of the web. So far, in my opinion we haven’t seen an evolution from the desktop given that Google Docs, as the premier example, looks and thinks pretty much like MS Word.
For this post I’m going to look at the first obvious visual differentiator between a text editor and a word processor. You notice this immediately when you open a word processor document, and you are skilled at manipulating its characteristics, but you might not think of it as a ‘feature’ as it is so present to almost be invisible – I’m talking about pagination. The first thing you notice when you open an existing document or start a new one is pagination, the boundaried space that makes your digital interface look like a piece of paper. Its not the sort of thing we think of when we think about a ‘feature’ but it is probably the strongest differentiating characteristic that separates the two categories of software.
Pagination
Why do we need pagination in a word processor? What purpose does it serve?
There are a number of purposes. Picking them off one by one:
navigation. We can generate navigational schemas if the content is paginated. These can either be inline references to page numbers or it might be in the form of a table of contents.
position in document. Related to (1) above – knowing what page number you are on, and the total number of pages, is an important function of pagination.
boundaried read/write space. In the print world it has long been considered a best practice to have between 45-75 characters per line (commonly abbreviated as CPL). Various arguments have been made that this number is optimum for speed of reading and comprehension (although I haven’t found any research about this, if you know of any please let me know!). Robert Bringhurst, the author of The Elements of Typographic Style (a goto for many book designers), goes even further to suggest the ideal number of characters for optimum legibility is 66. That is pretty specific. As it happens writing environments have always been around this range. Typewriters, for example, were generally around 80-90 CPL, teletype around 70-72 CPL, and this WordPress editor in which I am writing this has 72 CPL. Bounded spaces in Word Processors generally limit the CPL to around the same amount. Google docs is somewhere around 70-80 CPL, and LibreOffice is around 80. The area of 70-80 seems to be quite standard for Word Processors but laptops and larger screens can easily accommodate hundreds of characters per line so we need a bounded space to limit the CPL. Pages are a handy, and familiar, way to boundary the text area to limit CPL.
‘how much’ metrics. Word count is one indicator of how long a work is, but page count is often used both formally (ie. funding applications or job applications require a fixed number of pages) and intuitively by the writer to get a sense of how long their work is as they create it. Academics, in particular, often think of a works length in terms of page count.
expected ‘look’. Placement of headers and footers, page numbers etc are added to a document to make it conform to an expected look and feel. A letter of application for a job, for example, needs these elements as they are generally considered to add an air of formality to the document. This is obviously inherited from the age of paper but interestingly we still do this regardless of whether the content is printed, distributed as a word processor file, or rendered to paginated PDF.
design canvas. Interestingly, word processors are used as design environments. Think of the times you have played with fonts, tried to get the right spacing between a heading and the following paragraphs, added images and tweaked with the text flow to make the image sit well in the page etc. A boundaried ‘page’ presents a known canvas within which we can apply our implicit document design skills honed over many years of using word processors.
to print, or the possibility of print. There always is the possibility that the documents we create will be printed. If not by us, then those we share the documents with. We implicitly understand that if it looks fine on the screen then anyone printing it ‘sometime later’ will get a tidy outcome. In many cases we don’t think about it much, it’s more of an implicit assumption that covers us ‘just in case’ it is printed.
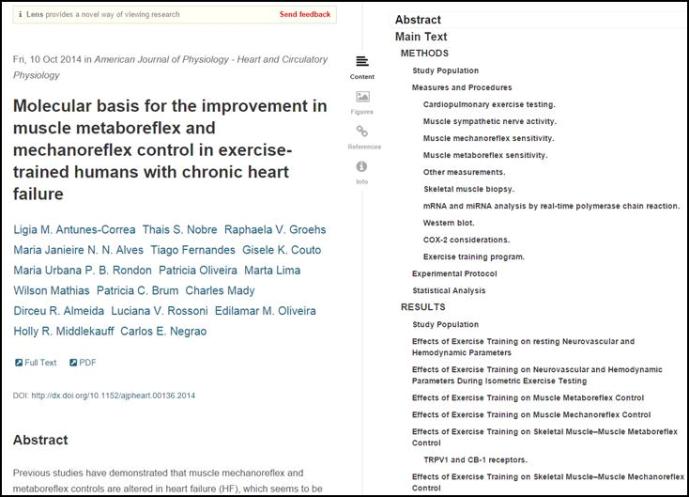
So, what to make of this. First, pagination is pretty essential to how many people use a Word Processor. It’s hard to think we can do without it. We might be able to achieve some of the above without a page paradigm. We could probably reasonably easily overcome the first 4 issues above – for example, we could provide word counts + ‘approximate page count’ indicators to give an idea of ‘how much’ content there is, provide a hierarchal navigation view of headings instead of page numbers for navigating around a document and as a ‘table of contents’ as Google Docs and eLife Lens (based on Substance.io) does.
eLife Lens. Table of Contents on right
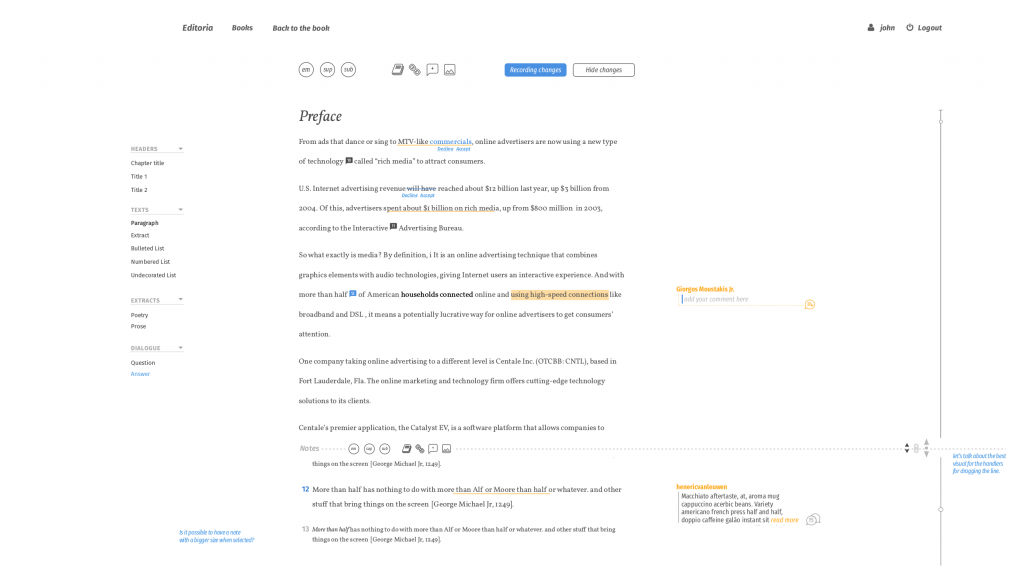
In addition, there are a number of ways to indicate the reading position in a document that do not require page numbers – check out this example (thanks to Julien Taquet for this tip), and it is also possible to limit the CPL without providing page boundaries in the design as Wax Editor does.
Wax Editor
However…the show stoppers really are the last 3 from the list above (to summarise again) –
expected look – many documents are expected to have page-based design elements regardless of whether we actually print them
design canvas – we know how (from years of banging around on ugly Word Processors) how to design documents using Word Processors, and
to print, or the possibility of print – we never know when something might be printed so knowing it looks ok on a ‘virtual page’ is a nice guarantee that it will look fine if printed.
Are we stuck with pagination?
It is difficult to argue that we could easily, or completely, throw away the page based paradigm based on these three items. So…does that mean Word Processors will be forever tied to the rather ugly page that you see floating like an existentially blank canvas every time you start a new document? Will web-based word processors forever be stuck in this paper paradigm?
My argument is no. We don’t need the page. Or at least, right now, in many use cases we can throw it away. The examples I used above provided clear cases where we need to directly correlate what you see when you create a document to the final result – whether for screen-based display, or print. But not every use case is like this. What is one of the biggest situations where you do not require a strict co-relation like this? Publishing.
I think I might hear you thinking ‘huh’? Afterall, if there is one industry that actually does require pagination it is the publishing industry (thinking in terms of the book and journal publishing sector for now, excluding newspapers, magazines etc).
That is true. However, the publishing industry doesn’t distribute to their readers a journal article as an MS Word file, or a book as a directory of MS Word files. They distribute unpaginated (usually) HTML files on the web, paginated PDF, EPUB files with various approaches to pagination, or paper. They generate these files by sending their source files (often MS Word) to an external vendor or in-house designer, who imports them into any number of design environments and converts this into the required formats.
Pagination comes ‘at the end of the line’ so to speak. Hence, unlike the typical home or office environment, there is no 1:1 correlation between what you see in word processors and what is finally distributed. So the needs of a word processor for a general user might be different to the needs of publisher. That, in itself, is pretty interesting. What if we could imagine specific word processors for specific use cases….
However, you will notice that word processors take a one-size-fits-all approach. We don’t have one word processor for book authors, one for publishers, one for lawyers (etc etc etc)…that is not to say we don’t need to differentiate these use cases and look at the specific needs of each. Interestingly, developing web based environments takes a lot less work that developing desktop applications and things have moved on since MS Word first hit the shelves. The web gives us substantially more room for modularity and customisation. With web-based word processors, every feature can be a configurable option. Don’t want or need track changes? That’s ok… remove it… Need a Diacritics interface? Easy… add it. Don’t want pagination? Remove it.
The point is, we can start building web based word processors that are highly customisable and can be configured to meet individual use cases. We haven’t seen that so far in word processing, Google Docs has also chosen a one size fits all – the only real difference here between GDocs and MS Word is that their ‘all’ is a smaller group. But that doesn’t mean we can’t do it if it makes sense. Technically it is very feasible and, as it happens, it’s the approach we are taking with the Wax Editor.
So, let’s imagine we have our own word processor made specifically for publishers. Do we need pagination? What role does it play in publisher workflows?
It is true that relative to the total number of publishers out there I’ve seen inside a small % of publishers’ workflows. However, interestingly, with each new publisher I work with I am seeing, more or less, the same workflows and from what I have seen so far, MS Word files are used widely to support a kind of early page-prep workflow. Publishers check and improve the content of course, but they also make sure certain elements are in place that will affect the final design. They check, for example, if all paragraphs are correctly indented. They check if images are in the right place, they check if headings are marked correctly and that no levels have been jumped etc. These all affect the final paginated outcomes, but none of this requires working within, or manipulating, pagination as it appears in the word processor. Checking the results of pagination (including page numbers, running heads, widows and orphans etc) comes when publishers do their page proofs ie. when they check the PDF before print or distribution (sadly, many publishers don’t check EPUB very thoroughly but just accept that it ‘is what it is’). Publishers don’t currently check the results of pagination, as it will appear in their final distributable form, in the word processor. So pagination in the word processor, at least on this point, is a little redundant.
So… my point is, if we get down to it, pagination features in a word processor are not required when you are working inside a publisher to prepare a document for publishing. We could instead use an unpaginated environment with a navigation based on document structure (not pages), word count as a metric for how much content there is, and simple constraints on CPL that do not look like a boxed, bounded, page.
But…what about the need to print on your office or home printer? Interestingly, I think this gets to the crux of the matter. Unbounded, flowable text, in a word processor does not mean you can’t print. It only means what you see in the word processor won’t have a one-to-one co-relation, with regard to pagination, to what is printed. But the big question is – is this acceptable to publishing staff? Can we get them to let go of thinking, a product of many years of legacy word processing user experience design, that the pagination in the browser ‘must’ correlate to the pagination that comes out of their home or office printer. My experience designing such systems alongside publishing staff leads me to believe his is possible. In fact, the University of California staff designed the Editoria system which features the Wax Editor which displays content sans pagination. The challenge is – it is up to us to show them that throwing pagination out works in their favour.
Before I go on to why throwing out pagination can be a convincing argument, I want to indulge in a rather lengthy aside and state that throwing out pagination is not the same as ‘not printing’. The results of printing from an ‘unpaginated’ form in a web-based word processor can be beautiful and a more consistent experience than printing off ‘any old’ word file. This is because we can use CSS print styles to make beautiful looking results that come out of your home printer. The point is only that the pagination will not correlate to what you see in the word processor. But you can have other things – for example, you could render pages for printing at any time that look like your final output. Quite probably this statement is news, or confusing, to you. It needs extensive explanation. But the idea, in basic form, is that content in HTML based word processors can be shaped by CSS into paginated form in the browser. This process allows you to automatically format the content into book or article form including running heads, page numbers, widow and orphan control, multiple columns (if desired) while also generating the table of contents and even indexes. This can be achieved, for example, by platforms that leverage tools like Vivliostyle. I’ll get to this in subsequent posts, maybe even the next one (in the meantime, you may wish to read this). For now, I want to leave this issue to the side but make the simple point that content that is not bounded by a page in the word processor can still be printed and, further, the results can be more beautiful and consistent than what you get by printing from Google Docs or MS Word today. However, the process of printing will feel slightly different because ‘how you print’ will be to first render a view that is conformant with your printer and then print. It’s not much different to how it is done now because this is how print-preview works in word processors today. When we print, we commonly choose the page format at print time, although most of the time we leave it at its defaults because we know that what we have seen in the word processor is the same as what will come out of the printer. ‘The new way’ would mean you will need to pay more attention to the second step – checking the formating in print preview before printing. Which is why I emphasise that the process will feel slightly different, the actual change in behaviour is minimal, if anything at all. But it would be a mistake to conflate user experience with user behaviour. The experience of the software is nothing to be brushed lightly aside, it can be a very strong impediment to new ways of working. So how things feel need to be taken into account. Which is why I think, ultimately, we will need other arguments to help many (not all) ‘get across the line’.
Which brings us back to the question – what is the advantage of not having pagination? If we can do away with it we have far more options for making beautiful experiences. The bounded page that all word processors commonly present is, in my opinion, hideous. It constrains how you construct a user interface, how people feel about that interface, and how people work. If we can free ourselves from it I think we open the door for much better experiences and innovations on what a word processor can do and be which also means, in the publishing industry, we can start innovating around word processor workflow.
Additionally, removing pagination from the word processor in publishing workflows is better aligned with how publishing works. Publishing formats do not share the same pagination. An EPUB page is not going to be the same page as the content displayed on the net, in a Kindle, in a PDF, or in a book. Might as well let that one go. If we need pagination at all, it needs to look like the final output and we need to get it earlier in the workflow than what currently occurs. Currently, publishers only see this after the content has been through their workflow and gets ingested and output to various formats by a designer, production staff, or external vendor. However…. HTML based word processors that leverage tools like Vivliostyle (mentioned above) enable the content to be paginated to all these formats on the fly. That means you can have ‘page proofs’ anytime you want in the process. So, letting go of pagination in the word processor, coupled with the ability to create these various paginated forms at any time, is an advantage to publishers. Publishers don’t need to wait for page proofs from a designer before they can tweak elements in the content (eg placement of images) to make the pages flow better in the final output. They can render, check, and tweak at any moment. From this point of view seeing one kind of pagination in the browser, especially one that conforms to a generic printed page coming out of the office printer, as it does now, is counter intuitive. But, I don’t expect many publishing staff to accept this by argument alone. We have to first get most people to experience this, and other benefits of a pagination free experience in a word processor, before they can start moving the way they work forward.
My conclusions? Well, I think it will be a while before we can convince the general user to drop pagination. But web based web processors allow us to build much more customisable experiences and avoid the ‘one size fits all’ approach. We can build to meet publishers’ specific needs and it is because of this that I believe we can produce software that will convince publishers to make the conversion sooner. This is because we can make the experience for them better if we drop pagination. The pages, which they look at for hours on end, can be cleaner, easier to read, and less tiring over long periods of time. We can also start using space more effectively by removing borders around pages (with their attendant inner and outer margins). And lastly, I think it is important to remove pagination from word processors for publishing workflows because it helps disambiguate what you see in the word processor from the final, designed and paginated, results. This latter point has positive knock-on effects that I will come to in other posts. Couple all this with the ability to ‘paginate on the fly’ (so to speak) at print time (for domestic/office printers) or to generate ‘page proofs’ of many target formats, and we have a winner.