BBQ last night, mellow hanging out. Then meets this morning, and off shortly to surf.



Publishing Innovator. Surfer. Ponderer. NZer.
BBQ last night, mellow hanging out. Then meets this morning, and off shortly to surf.
2 days surfing with some good buddies from Northland – Pete n Pepper. A cool 2 days. Camping and surfing. We checked out Rarawa Beach and Shippies/Mukies. Camped out at a DOC (Department of Conservation) camp near Rarawa. Didn’t take too many pics.




My outdoor workspace is coming along. No help from me mind… all done by Patrick, Harper and Joseph. Nice neighbors from down the road and a pretty famous family around here. They have been busy digging it out and putting in the posts for the retaining wall… looks super sturdy… they kindly gave me permission to take a few pics of the progress 🙂




So, I am making an outdoor lab space in the Hokianga (NZ). The space looks like this at the moment…

…and I am going to make an outside wall for post-it note sessions, with a big wooden table and some seats, some grass to sit on etc…I think its going to be great!
But… it’s quite windy up these ways and well.. the big question is… will post-it notes stay up on a wooden wall? Post-its are notorious for not co-operating in sub-ideal conditions. They just fall off or blow away. Such serious problems make up my day sometimes…so I decided to test it. Luckily the post-it notes people have just released a new product which has the entire back covered with adhesive (as opposed to a think stripe at the top)… so I got a packet and tested it in the space…by sticking them to plants and clay….







Why not make it a serious test? If it can stick on these then we are more than good…so I stuck them up and left them over the afternoon, which was really windy, and then over night… and the results…





Some of them slightly peeled off but not much and they all stayed stuck! I was figuring none would last overnight…awesome!…
And some photos of my day, including the new home for the surfboard I made in France a few weeks ago. It’s in the corner of my house. Also below are pictures of the Rawene Ferry (I was on it today on the way up North). And a photo of the Hokianga Harbor when I got home this evening.









I’ve been pondering building a lab space at my place in NZ. More than pondering actually – I cleared a bit of the bush behind my house and Patrick from down (ish) the road dug it out. Next week we are putting in some retainer posts. It’s a pretty nice spot. I’m sitting here as I write this, I can hear the sound of the wind through the trees, birds. It’s midsummer and yet it’s nice and cool here in the shade of some tall manuka.
The idea is to have a lab where publishing/collaboration/ knowledge-making folks can come think, by themselves, with me, and with others. A first meet is lined up for April for SprintLab, an offshoot of Book Sprints…
But more on all this soon. Here’s some photos of where I’m sitting right now. I’ll draw up some rough sketches of what I plan in the next days/weeks…suffice to say for now that the spot in the photos will be an outside workshop space….I’ll put a little sleepout also somewhere else on the property but imagine what you see below as a lovely outdoor collaboration workspace/think lab….




The photos below are of some of the bush surrounding the lab. The pointy tree top you can see 2 pics down is of the largest tree on the property – a maturing Kauri tree.






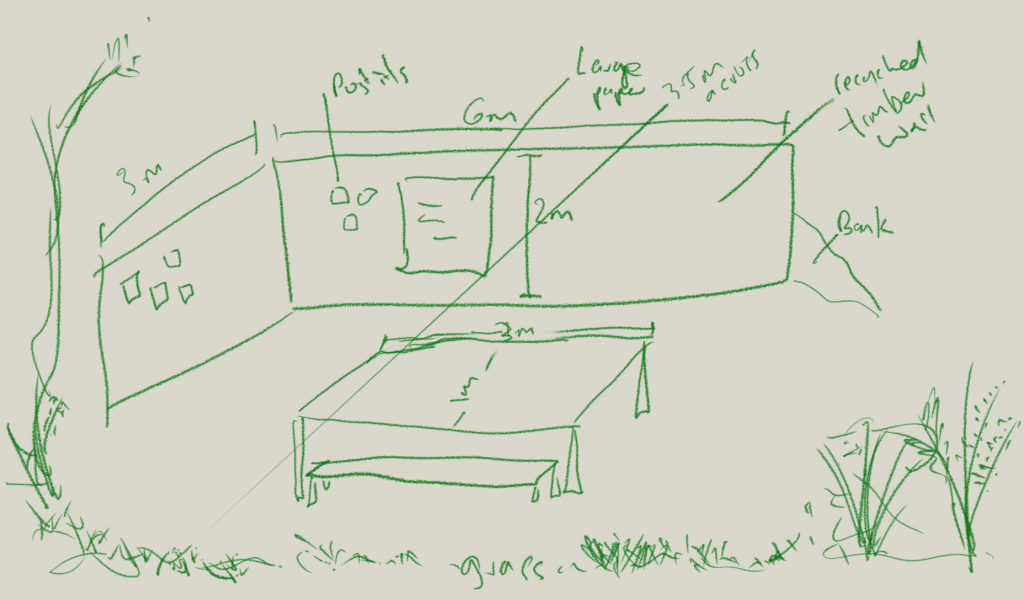
And… a rough sketch of my thoughts so far…generally, to build 2 walls out of recycled timber that semi-enclose the space. This is for post-it notes and large pieces of paper to be hung. Then a large wooden table in the middle, and the clearing to be grassed with native grass.
And some more shots from the evening, which makes it a little easier to see the space. First shot is the path down.







I’ve been sitting in my bath and pondering publishing platforms. Specifically, how long it takes to build them. We get asked this all the time. So… here is my very non-scientific answer to the very open ended ‘how long will it take?’.
For a start, let’s measure it in person years. 1 person working one year = 1 person year. A calendar year, on the other hand, is an actual year ie 1 year elapsed.
The answer, I think, is around about 3-6 person (dev) years + 1 year management/design/UX etc. 6 (+1) person years is at the top end for the old skool way of building platforms (building everything yourself). If you build with PubSweet I think we have that down to about 3-4 (+1) person years. So 1 developer will take 3-4 calendar years (with management/ux/design occurring in parallel).
Adding more devs lessens the time. That means if you have 2 devs its around 1.5-2 calendar years. 4 devs gets it lower but at a slower ramp down. Maybe 1 calendar year.
I think, again incredibly unscientific, that the 1 year management/ux/design is both 1 person year and a static calendar year…ie. no matter how many developers you have, you still need one or so cal year in total for nailing down details, improving UX, look n feel etc…so even if you get dev down to 1 year, its hard to see how you can reduce the 1 calendar year management/ux/design. Theres just a lot of to and fro and thinky time required for these parts. Thankfully however most of this can be done in parallel to dev work.
That seems about right from what I have seen in the outside world and inside the Coko community. The new improved PubSweet dev times don’t account for significant complexity (eg very experimental approaches or situations with many legacy integrations or systems which themselves contain significant new applications like web based word processors/pagination engines/JATS Editors etc – each of which will take longer). It also doesn’t account for significant reusability (which will cut down the time). The numbers are based on a team building a ‘typical’ journal or book production workflow from the ground up on PubSweet and re-using some existing components but building most themselves.
I think as we grow this timeline will drop through the floor with significant re-usability and more people to learn from. Both of which are conditions that will be met as the community grows. We have already shaved 2 or so years at least from such endeavors which is significant and I think we will see it drop even more. Those that come later will benefit greatly from what is happening now, but even now we are making some fantastic efficiencies.
This is obviously totally based on nothing but observation of dev time across 10-12 years on a few dozen publishing platforms I’ve been involved in. Very anecdotal but not nothing.
My site has been updated bit by bit over the last year by Faith Bosworth. Faith has been updating the texts about me. This is great because I am the worst person in the world to write about me and the process has been really fantastic. Faith and I discussed what it is that I’ve been up to over the years and then Faith captures it in a well-written synopsis deliberately written to sound like me. Latest update is the intro to the page on Art, Activism and Broadcasting.
I highly recommend Faith for writing (Faith has many other talents as well), if you are looking for anyone to do something similar then let me know and I’ll put you in touch.





My buddies Pete n Debs have a growing family, recently adding Lilly (goat) and Helen (turkey). All good except they live in the middle of Auckland…




I kinda liked The Martian by Andy Weir so thought I’d give the follow up a go. Its absolutely terrible. The plot looked like it was going to be good but I didn’t make it through chapter two for all of its sexist troddle. Awful. Don’t bother.