The point being that publishers take badly structured Word documents and process them. Adding structure etc and then ‘throwing them over the wall’ to outsourced vendors to convert into other formats. When publishers add structure to documents, they often do this with MS Word and custom-built extensions. They simply click on part of the text, choose the right semantic tag, move to the next. Just imagine… how many publishers have built these custom macros (it is very common) and also imagine that each publisher must tweak the macro code with new releases of MS Word. Tricky and expensive!
So, the point is, why not do that in the browser using web-based editors? It not only brings the content into an environment that enables new efficiencies in workflow but it also means publishers don’t have to keep upgrading these macros all the time. Further, if the tools for doing this in the browser are Open Source…well… you get the picture – share the burden, share the love.
So the article is a small semantic manoeuvre to get the conversation away from the rather opinionated, but dominant position, that MS Word-to-HTML conversion is terrible because you can’t infer structure during the conversion process… The implication is that HTML isn’t ‘good enough’. Our point is, you don’t need to infer the structure because it wasn’t there in the first place. Plus, HTML is an excellent format for progressively adding structure since it is very forgiving – you can have as much, or as little, structure as you like with HTML. Hence we can look to shared efforts to build shared browser-based tools for processing documents rather than creating and maintaining one off macros.
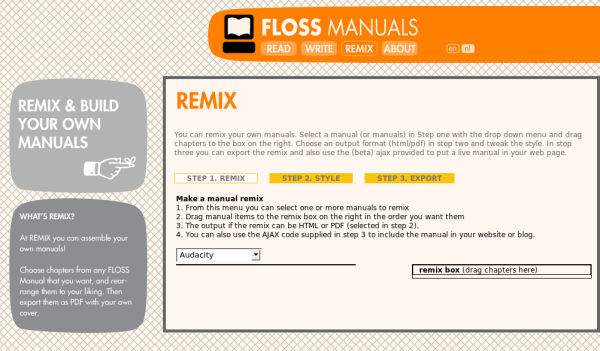
A few years ago, I wrote a brief post on Remix vs Shuffle. At the time, the Open Educational Resources (OER) movement was struggling to work out how existing teaching materials could be remixed and reused. No one had really cracked it. At the same time, we built remix into FLOSS Manuals. The primary use case was for workshop leaders to be able to compile their own workshop manual from existing resources. We had a large enough repository of works, so it was a question of how we went about enabling remix.
Recently, I have been in two separate conversations about remix (after not having thought or talked about it for some time). One conversation was in the context of OER, the other in the context of remixing many journal articles into a Collection. So, I’m revisiting some earlier thoughts on the topic and updating etc…
At the time, we expected the FLOSS Manuals remix to be used a lot. I was a workshop leader myself and thought I could benefit from the feature. However, remixing wasn’t used very much by me (I did get some very useful manuals from using it, but didn’t use it often) or anyone else. Hence I wrote the reflection on remix (linked above). My position is outlined by the following quotes from that article:
I have come to the understanding the ‘remix’ as such has only a limited use when it comes to constructing books from multiple sources.
And the following, where I liken book remix to remixing of music to illustrate the shortcomings:
Text requires the same kind of shaping. If you take a chapter from one book and then put it next to another chapter from another book, you do not have a book – you have two adjacent chapters. You need to work to make them fit together. Working material like this is not just a matter of cross-fading from one to the other by smoothing out the requisite intros and outros (although this makes a big difference in itself), but there are other aspects to consider – tone, tempo, texture, language used, point of view, voice etc as well as some more mundane mechanical issues. What, for example, do you do with a chapter that makes reference to other chapters in the book it originated from? You need to change these references and other mechanics as well as take care of the more tonal components of the text.
I think these are valid points, but I think, revising this, there is one nuance I would like to add. Sometimes ‘shuffling’ is adequate where you are compiling an anthology which is, as it happens, the case when you are putting multiple journal articles into a collection. Building tools to enable this kind of ‘reshuffle’ is very useful but still I would question the usefulness in certain contexts. It is a use case that, from my experience, would be great as a tool used by, for example, a publisher or curator. I’m not sure of its usefulness in a more generic ‘user space’. Journal publishers do, in fact, make collections where several articles are compiled together to form one ‘bound’ work (often a PDF). In this space, such a tool could make life much easier. Whether members of the research community, for example, would want, need, or use such a tool is still an open question to me.
For information on how FLOSS Manuals Remix worked see here:
Many thanks to friend and colleague Raewyn Whyte who has been maintaining this blog, transferring over a heap of content, editing, forensically digging for images and old posts, filtering spam, tagging, cleaning, and helping me organise and maintain this new version of my site.
Now she has to read and edit this too without blushing. Thanks Raewyn 🙂
ps. if you need a good editor/writer you can find her here
It is always tempting to develop demos when developing software. I have driven myself and others down this path many times. The aim being to come up with an inspiring ‘facade-only’ features quickly that can encourage ‘buy in’ from your target audience.
However, with a few exceptions, I have never actually found they lead to many interesting places . Demos have a few paradoxes that are not immediately apparent when you get that great idea which is where the software could be or should be or maybe, just maybe, might be. So it’s worth spelling out, for myself if for no one else, why demos are, generally speaking, a bad idea.
a good demo works – the ultimate paradox. There is often no difference between building a good demo and building the thing itself. So, don’t kid yourself that a demo is going to be a magically shorter shot to the moon. It’s the same distance to the moon in a demo rocket as it is in a real one.
demos are fake – demos are fake ups, but you think it will better demonstrate to people what your software is capable of doing. But it is not doing it, because it is fake.
demos can yield unreasonable expectations – so you make a great demo software. People buy into it! So when are you going to deliver? Soon, right!? It’s almost there! Wrong.
demos waste development time – that speaks for itself.
The longer I get in the tooth, the more I think you should demo what you have. I think that many times demos are presented as a kind of proxy for the future state of the software. Almost smoothing over some deep anxiety that you aren’t far enough down the road yet. You want people to think you are further down the road than you are. Sure. I get it. I’ve been there. However, I think you have to be confident about what you are doing. Show what you have now and stand strong. It is where it is. Talk about the future, don’t demo it.
note: I’m not talking about exploratory prototypes. I think this is another thing altogether. These are necessary and useful explorations even if they don’t immediately lead anywhere, sooner or later the learnings will emerge when you need them.
A good friend, Enric Senabre, together with Ricard Espelt (who I don’t know) wrote and published an interesting article on designing for platform cooperativism. They set out to define “platform cooperativism UX”, which seems to be to be a very concrete task on one level (UX is nothing if not concrete) for a general state, approach, or category of ‘platform’.
I’m not going to go into detail here about Platform Cooperativism, because I don’t really get it. I do know Trebor Sholz and figure whatever he does is probably right and makes sense. So I’m buying the book to find out more.
Enric and Ricard are approaching software design by intersecting strategies to overcome technically disenfranchising stakeholders while ‘learning as you go’. These are laudable aims, especially in the NFP sector where there is a great need to develop solutions that actually solve problems. As I read somewhere recently, the technology community has no shortage of solutions, what they are in need of are solutions that solve problems. Zara Rahman has also pointed this out recently and is conducting research into just this area.
The issue here is that often technologists see all problems through the eyes of code. Further, they are prone to see the intended beneficiaries of their work as avatars. There are, in fact, many strategies to turn real people with real needs into avatars.
If you try to solve real world problems with code, and your participants are avatars, you are really setting yourself up to be a great game developer. You are possibly not in a good position to solve real problems.
So, Enric and Ricard are starting off with the right premise and in the article they document their experiment, exploring fundamentals to come up with a new facilitation methodology for this context.
we began with a reflection on which specific functionalities and features (other than those available on existing online platforms and social web interfaces in general), if any, could be explored
They seem to have given themselves an extremely difficult task – designing for an open-ended ‘imaginative’ state. Although they couch this as ‘specific functionalities,’ I take it they are trying to define specific functionalities for a generalized approach to platforms. That is tricky. I admire that they took this on. Innovating with design methodologies takes some gusto, and it is a vital process for defining and refining tools for a new method. However, in my experience, open-ended problems like this seldom lead anywhere useful. You need to start smaller, with real, concrete problems. These might add up to, and constitute, larger issues, but the road to those issues is from the bottom, not the top.
It seems that the result was still productive, but perhaps not in the way expected. They appear to have elevated the group’s awareness to issues of trust in the social web. A hot topic at the moment. As such, the process is successful as a barometer of the times, identifying issues that concern people here and now. Enric and Ricard appear to have understood this too and continued on to refine this starting point, moving it towards actual UX design with the well-known method of user stories.
However, user stories are best deployed as a function of software design and I don’t think their process was there yet. User stories require a concrete problem. They are intended to drive people toward designing a concrete solution. Bringing this framework to a general question of reputation is confusing methods and will cause cognitive drag and a mixed understanding of intended results. It would be better to keep this part of the process outside of software design paradigms, and instead, employ general ‘sense making’ methods.
It seems that Enric and Ricard diverted from the goal to produce concrete UX and ended up driving towards requirements. I would say this is a better direction. However, requirements-gathering for a general issue is not well placed to lead to much of use to software development other than a ‘general direction’ – which is what they seem to have achieved but not what they set out to achieve.
As such, I think the results of Enric and Ricard’s experiment are interesting, but the results are not interesting in the way they outline. In the summary they state:
The next steps in addressing “platform cooperativism UX” should continue along these lines: new user stories that generate both potential platform coop requirements and design-driven research outputs.
This overstates the value of their findings as generated by the participants. The real value of this session is that they tried to assemble a methodology for an ambitious context – in essence, they are actually trying to help the ‘platform cooperative’ community to understand itself, to understand the implications of their philosophy. I think that is really interesting and admirable. What they need to do, however, is not to override this aim with the pretense of generating actual user stories, software requirement, and UX for platforms. They need to name and design a method that starts in another place – a place where the articulation of values is the outcome, not the construction of code.
Booktype is still going very well and has also spawned the very interesting Omnibook service. Due to the recent interest in this project, I revisited this old video which documents some of the exploratory thinking I had when leading the Booktype team at Sourcefabric. It was recorded May 2012 at #dev8ed in Birmingham, UK. At the time I was leading a small team, having just migrated Booki (FLOSS Manuals) to Booktype (at Sourcefabric).
I found the video really interesting as it covers my thinking at the time, (developed over many years of experimenting in this area) over many issues, including rendering books in the browser and using the browser as a design environment for books. There are some nice quotes which accurately reflect how I was thinking then which are interesting:
“there is no one taking responsibility for designing environments where you can target both flowable text as an output like Kindle or EPUBS, and at the same time, target fixed page outputs like paper books. So we are trying to work this out at the moment. How do you deal with this? .[…] We are trying to work out how can you possibly find a paradigm that fits both flow-based, and fixed page, design” [36min 25s]
and
“what we want to see [in the browser] is when you are outputting to book-formatted PDF, we want to see like you see in Google Docs – exactly the page dimensions that you are going to get when you output the PDF. Google Docs does some sort of magic where that is possible, we haven’t yet cracked it ourselves, but for fixed page design we think it is quite important that what you see in the HTML page is what you would eventually get in the PDF. [41min 37s]
…
“…how do you actually render one to one representation of a book-formatted PDF in a browser?” [49min 49s]
…
“…we can have JavaScript playing a role in rendering elements of pages for book-formatted PDF.” [16min 58s]
…
“…we take the Booktype content as HTML, HTML as the base format, and Objavi formats that into one long HTML page for which we have specific CSS rules to structure the book in a specific way. Then we run WKHTML over the top of it, and a number of other tools, and we assemble a book out of it, book-formatted PDF” [18min 38s]
…
“Thats because WKHTMLTOPDF is webkit, the browsing engine behind Chrome and Safari, … so you can use CSS, and JavaScript and everything from webkit, and turn it into a PDF” [19min 50s]
…
“…the advantage of using webkit as part of the rendering environment, as webkit is a browser, [is that] if you design in the browser you have a one to one co-relation between content creation environment and output environment” [33 min 49sec]
To be clear, we were already using browser engines to make books for quite some time, and Douglas Bagnall, a friend who also worked with me at FLOSS Manuals, even investigated collaborating with the Gecko (Mozilla layout engine) developers to add widows and orphans controls and the CSS page-break control (which we needed for books), in 2010 or so. Actually, it was pretty cool because Douglas, myself and Robert O’Callahan (Mozilla layout engine dev) were all New Zealanders. But FLOSS Manuals had been making books for many years with browser engines since Behdad Esfahbod advised me to explore this, many years earlier. We knew browsers could be used for producing book-formatted PDF and we had been doing it for years.
However, as I have learned over the years, there is an important role for vision, experimentation, and theoretical exploration prior to developing good software. Hence, I was now exploring how you could take these positions further to design books in the browser client. Rendering PDF was one part of the story, the other was working out the tools to take book design to the browser. This was what Adobe was also after, I believe, when they implemented CSS Regions in webkit and started on their Adobe Edge Reflow line of products that leveraged the browser as a ‘design surface’. They were interesting times.
While BookJS didn’t quite get to be the design environment I was (and still am) after, it was still a good tool. In an attempt to get to a design and rendering solution in the browser, we later took the Booktype Designer (demonstrated in the video) ideas to a JavaScript prototype called StyleJS for integrating with BookJS but, unfortunately, it didn’t make it to production. StyleJS enabled a kind of ‘WYSIWYG’ tool for styling a page live. Which is an interesting prototype for future in browser book production exploration.
Work continued on BookJS and it has had a useful life despite some quirky turns in the road. During this time, the Booktype team worked with several people on the development of BookJS and received good advice and contributions from Mihai Balan (from the Adobe CSS Regions team), Phil Schatz (from Connexions), Maria Fraser (University College London) and others. As with many software projects, contributions like this deserve a lot of credit, as I have written elsewhere, since these contributions are not always preserved in the code.
In the Booktype world, Juan Gutierrez (who worked on BookJS at Sourcefabric, and now works with me at Coko) extended BookJS to support the CSS Regions polyfil. It is still in use now with Book Sprints for rendering books. Consequently, we are still very grateful that Booktype and Sourcefabric kept the BookJS product AGPL after I left the project so we could extend it. Hurray for Open Source!
It is good to see Booktype going strong, Sourcefabric still invested in Open Source, and a growing interest around Omnibook. I know the team there, Micz Flor (co-founder of Sourcefabric and Managing Director of Booktype) being an old friend, and Julian Sorge also makes a great Booktype Managing Director. They have brought their own vision to the Booktype products, pushing them in new directions, and it is really great to see. I’m hoping they will continue to go from strength to strength.
In summary, these were interesting, productive times. Sourcefabric provided the opportunity for Booktype to grow, and I experimented a lot, as I had done at FLOSS Manuals (and continue to do now), with new ideas and approaches. There was some great software, books, and ideas that came out of that period. Some of the books we made I have even kept with me through my travels. In the video, for example, I demonstrate the Booktype Designer. We built the Designer before and during the Sandberg Institute workshop I led in Amsterdam and used it in the same month as I did the presentation to create this wonderful artist’s book. I carried it with me all over the world and still have it on my bookshelf now!
A few weeks ago Dave Cramer and I started a new website – Paged Media. The website’s purpose is to promote the use of HTML, CSS and JS to make books, whether the books are displayed in the browser, or in e-readers, on mobile devices, or in print. The site is coming along nicely with blog posts and links to valuable resources to do with the production of books for reading or display on screen. Soon we will introduce podcasts to the site, some weekly how-to posts, and items about the future and past of this very important approach to making books.
While copying over my archives from everywhere, Raewyn Whyte, who is helping me with the copying and cleanup, carried over all the posts from my 2006-07 summer trip to Antarctica. You can find them here:
The original site doesn’t exist anymore so we had to fish them out of the good ole Wayback Machine.
It was an amazing journey to Antarctica. I have some definite highlights and lowlights. Lows included the death of one of our crew on the first day at the base due to very unfortunate circumstances. That was unbelievably horrible. Also, I think I felt quite compromised being in Antarctica in the first place. I almost didn’t go but didn’t want to let down the buddies I had made a commitment to.
I felt uncomfortable because the science bases on Antarctica are strategic placements… waiting, waiting, until the pressure gets too much and the moratorium on extractive industries comes off… I can’t speak for the entire continent but my direct experience was that there was very little real science going on, and a lot of resources were being spent in the name of science while maintaining strategic positions for bases.
The highs were that it was an amazing experience and I felt privileged to be there. I met great people, had good times, even beat the chopper captain in the New Year’s darts finals! We did some amazing stuff too. Building antenna, setting up a radio station and a very low-fi radio talkback system, among other things.
But mostly it was the really unbelievable beauty of the place.
Our mission was to start the build of an autonomous mobile base for art-science collaborations. We did the first phase, others came later. I don’t know if it was ever completed, I lost track of it.
Anyway.. .it was a great experience. I visited the SA Agulhas (the icebreaker we travelled down in) a few years ago at the Capetown wharf. Beautiful boat.
The new Collaborative Knowledge Foundation website is now live. It was designed by the fabulous Dutch design company the van Leeuwen Brothers. I have known designer Henrik van Leeuwen for many years. He’s a good friend, talented designer, and great artist. Henrik has done all the illustrations for Book Sprint books for many years now and does almost all the Book Sprint cover designs. He developed the Book Sprint and Coko logos and now the Coko website. Henrik and his brother Kresten are huge talents and if you are looking around for good designers I highly recommend them.
Editoria is a software platform Coko has been working on in collaboration with the University of California Press and the California Digital Library. It is the first product that we have taken through the Collaborative Product Development process and it is looking pretty good!
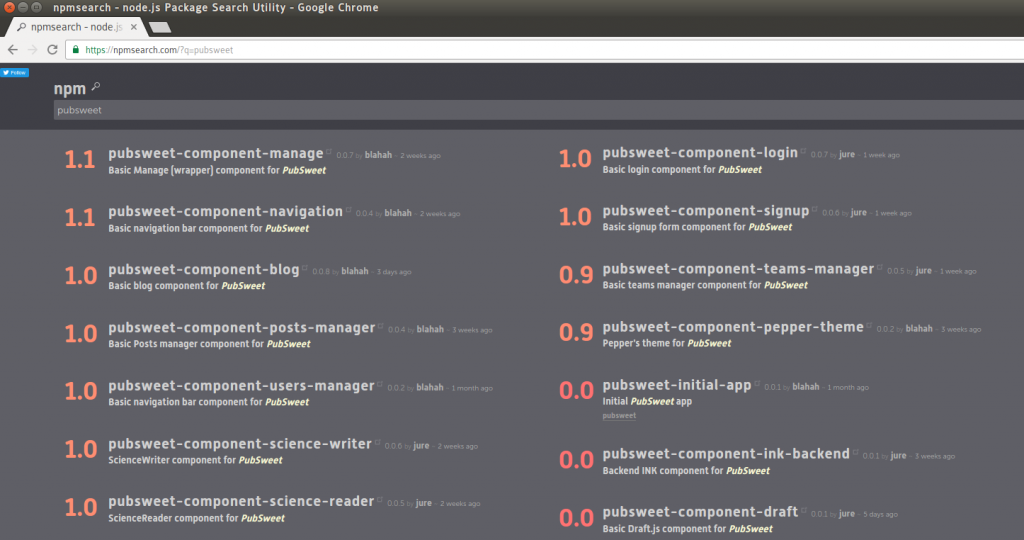
Editoria is built on top of PubSweet, which means there are separate frontend components integrated with the PubSweet core application. These frontend components are available as open source (MIT) in the Coko gitlab repositores. They have not yet been nicely bundled for distribution but this will be available soon as we have done with many other PubSweet components. You can see these if you search the NPM repository online:
PubSweet components on NPM
The frontend components enable 3 workspaces, a book dashboard, the book builder, and an editor. This follows the general pattern of book production platforms I have been involved in since FLOSS Manuals in 2006 or so. This kind of design places the structure of the book itself as a central workspace which gives not only an overview of the structure of the book but of all operations concerning the book. I think this is a good general strategy as I have previously written about here and others, including Micz Flor of Booktype, have also written about.
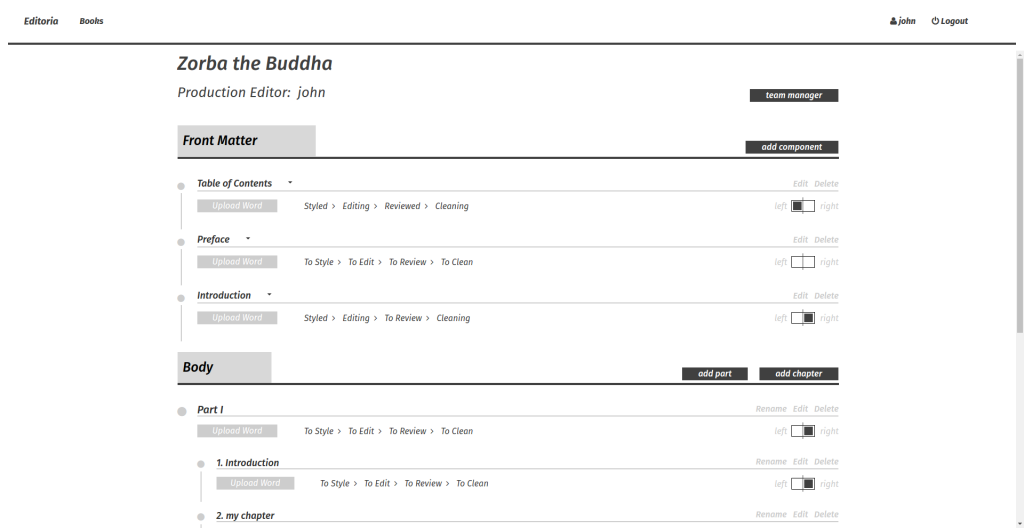
In Editoria, this central workspace is known as the Book Builder, and the following is a screenshot as of Nov 19, 2016.
Editoria Book Builder
It contains a lot of punch but is pretty simple to understand which is the ideal since you really want to get an understanding of the status of a book at a glance.
Before looking at this in detail, first a little disambiguation – we are following the Chicago Manual of Style for the naming of items. In this case, each of the front matter, body and back matter sections are known as divisions. Items within each of these, be they a table of contents, preface, glossary, appendix or chapter (etc) are known as components. A part is a collection of chapters (technically a part is also a type of component).
In the Book Builder we have the following:
Front matter, body, and back matter divisions
A list all book components (chapters/parts)
Status (4 status markers for each component, each with 3 states) – from the Book Builder you can set a status for each component. These are currently hard-coded (but may become configurable at a later date) to the following 4 items with 3 states each: To Style, Styling, Styled To Edit, Editing, Edited To Review, Reviewing, Reviewed To Clean, Cleaning, Cleaned Clicking on a status item moves it to the next state. These states are both indicators of the status of a component (what needs to be done, is being done, or is done) and they are connected to access permissions. When, for example, a chapter is marked To Review, in this case those that are Authors (see Team Manager below) can access the chapter in edit mode and review changes and make alterations as requested by the Copy Editor.
Upload word (converts to HTML, yet to be wired in) – we are working on the MS Word-to-HTML converter which will shortly be integrated. This will enable the upload of MS Word files into the system which is critical since all books come to UCP and CDL from the author(s) to Acquisitions to Production in MS Word format. It is the Production department that uses Editoria.
Tools to add, rename, and delete components – it is possible to add new components dynamically, rename them and delete them. It is also possible to drag and drop these components to reorder them.
Pagination markers – these indicate whether the component should be left or right breaking when paginated for paper book production. A click on the left or right pagination boxes changes the state. This state will later be important for exporting to PDF via the open source Vivliostyle HTML-to- PDF renderer.
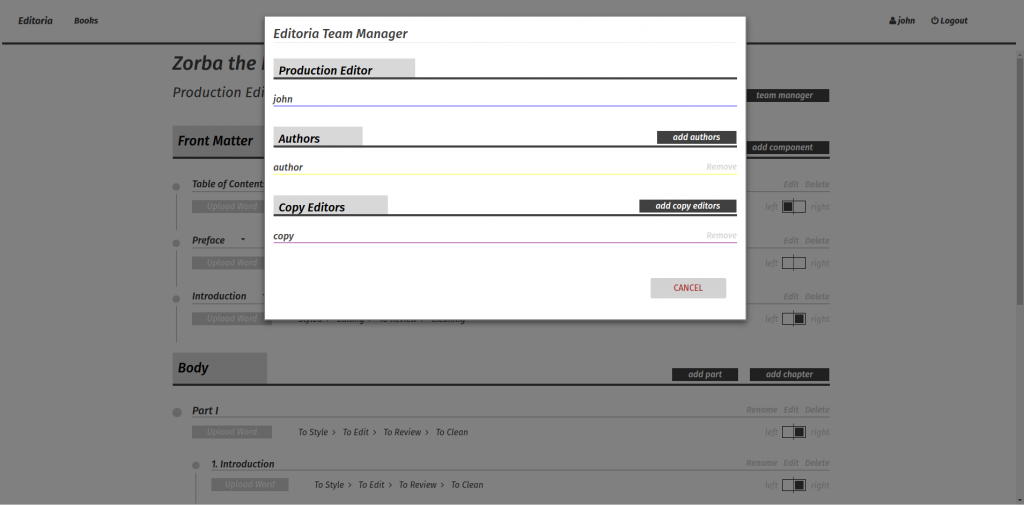
In addition to the above, there is a team manager interface available from the Book Builder:
Editoria Team Manager
Through this interface, you can add team members to the book. This affects access permissions. The team manager, in this case, has three roles – Production Editors, Authors, and Copy Editors. These are all in themselves configurable within the admin side of the system so it is possible to have different types of roles for different organisations (in my experience role names and duties differ quite a bit between publishers).
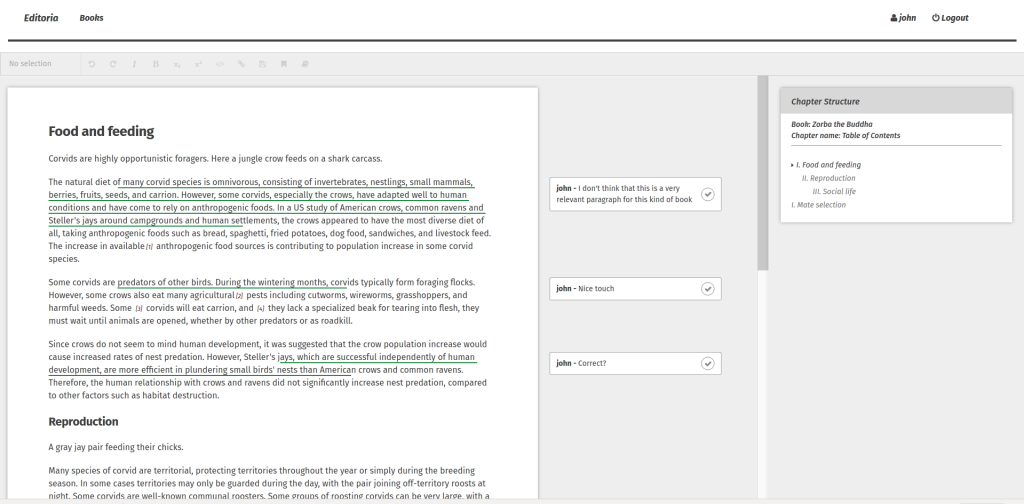
In addition, you can press edit next to any of the components and it takes you through to the editor for that component:
Editoria Editor
This editor has been built with the open source Substance libraries. To build this, we have first conducted an audit of the element types CDL and UCP require within a book. By this I mean we looked at the types of content UCP and CDL already has within chapters (components). For example, they require (as most books do) headings of various levels – Heading 1, Heading 2, Heading 3 etc. In addition, custom elements are required like an Extract, Block Quote or Dialogue etc. Our mission is to capture all these different content types and custom build these into the editor so that you can highlight a part of the text and apply the correct element type. This is extremely important when it comes to outputting the book since we need to know how to style each of these elements to the chosen design.
We also have all the regular features in the editor such as the ability to edit the document, add and remove bold, italics etc. We also have a number of additional features that were designed by the UCP Production Staff during our Collaborative Design Sessions. These features include:
Notes management – it is possible to add, edit, and remove notes. These notes correspond to end, book, or foot notes in books. In the editor, they are displayed at the bottom of the page while in the output they may appear at the end of the page, chapter, or book so we refer to them more generally as just notes in this environment. You can add notes and edit them through an overlay so that this can be done in situ (without having to scroll to the bottom of the page).
Comments – sometimes referred to as annotations. It is possible to select a portion of the text and add a comment. These appear in the margin. It is then possible to reply to, and resolve, these comments. This is intended to be used by Copy Editors and Authors for discussing and resolving issues in the text. For those that are interested, it took about 3 weeks to develop the annotation feature which is pretty quick.
Chapter Structure – the structure of the chapter is currently displayed at the far right of the page. This lists all headings in a nested fashion. Clicking on any heading will scroll the page to that position. It is intended to give a quick overview of the structure of a chapter and to enable fast navigation. It can also be used to check the headings follow the require d nesting conventions.
We are building in a few additional features in the editor before we trial books through the system. These are:
Images – the ability to add and remove images in the book
Spell check
Track changes – the ability to turn on and off a ‘track changes’ type function
We are also integrating the MS Word-to-HTML conversion and the PDF rendering features. MS Word-to-HTML conversion is done through a set of conversion scripts we are writing called XSweet. These convert MS Word to HTML in a series of steps. We have deliberately designed it this way so that we can customise various stages of the conversion for different publishers since content types vary enormously between different organisations (or different departments within the same publisher). The conversion will be executed using an additional software we are building called INK. More about INK can be found on the Coko website.
The HTML-to-PDF conversion will be done using Vivliostyle. This is a great open source software that uses the browser to paginate HTML into a book form that can be output from the browser to PDF. It requires the development of custom CSS for styling the outputs and this takes a little time but so far the results look good.
In time we will layer on more functionality but, for now, this is the overview of the system. The aim is to get it functional for production tests within a couple more months, then trial it, fix issues, and start adding on more functionality. It has been an interesting road so far. Working with the Coko team and the UCP and CDL teams has been a real pleasure and I think we are building an amazing open source system for the production and maintenance of scholarly monographs.
To watch the ongoing development of the system please see the Editoria website. Also, consider reaching out to UCP/CDL via the Editoria mailing list of you are interested in learning more.