We (Coko) are going to work through some smaller issues on XSweet. XSweet is our XSLT scripts that convert MS Word to HTML Typescript. We need to keep filling out small gotchas but mainly we look into table conversion and some font fixes. So far though, XSweet is looking pretty sweeeeeeeeeeeeeeeeeet…..
In other news – just putting together a HTML to JATS pipeline using INK and building some INK Steps around Martin Fenner’s pandoc-JATS. We’ll experiment with this but may ultimately move to a HTML to JATS XSLT solution that doesn’t need to convert to markdown as an intermediary (as pandoc does).
What this means, is that in a week or so we could create a new recipe that chains together the following INK Steps:
XSweet (MS Word to HTML conversion)
HTML to JATS Typescript (a version of HTML ready for ingestion into pandoc)
pandoc-JATS for HTML to JATS conversion
We don’t currently have a use case for this, but as you can see it takes MS Word through this chain and will produce JATS. We’ll test it out and see how far it gets us. In the journal world, we anticipate this would be useful to some but more interesting is to go from MS Word to HTML, ingest this into a PubSweet journal system, improve with the Wax Editor, and then output this to JATS at publish time. This way we don’t try and optimise the file too early which, IMHO, is a big mistake.
One of the things I do a lot, is help people think through their workflows and how to optimise them. We do this for all kinds of projects – book workflows, journals, micropubs, pre-print services etc prior to developing a software with them that will help them do what they do better, enable efficiencies, while leaving the door open for continual optimisation of how they work and for possible future transformations of how they work. Drawing from my 10 or so years of facilitation experience I facilitate these processes, and Kristen, drawing from her 20+ years in publishing, is ’embedded’ in the group to be part of the conversation and foster discussion and ideas from ‘within’ the group. We make a pretty good combo.
To do this we must help people ‘think in web-based workflows’. While most journal platforms out there are accessible via the browser they are not what I would call ‘web-based’. They take no advantage of what a networked digital environment can enable. Instead, the web is used as a common way to access what are, primarily, cumbersome database ‘ledger’ systems where workflow is tracked more than it is enabled. Books are even more interesting in that book production staff primarily work directly on the file system with MS Word files. There is little proof the web exists in many publisher’s book production workflows except that they use the network to email collections of files to each other.
So, how do we get people whose primary work environment is anything but the web, to start thinking about how they might work in the web? Well, we essentially follow 3 stages:
document the current workflow
discuss an ‘optimum’ workflow
map this workflow into browser views (we call them ‘collaborative spaces’ or, more commonly, ‘spaces’)
Each of these steps takes several hours. We allow minimum one day for the entire process detailed below. 1.5 – days would make it more comfortable.
Document the Current Workflow
It is important to start the process with all major stakeholders in the same room. Clear out a few hours, or a day, and bring along a lot of paper, post-its, pens and, preferably, some large whiteboards.
Talking through the Journal of Creative Technologies workflow (Auckland, NZ)
It is important to make sure all the major stakeholders are there (or representatives if some groups are large) because when you go through the current workflow you will discover that no one in the room knows the whole story. It is also often true that the organisers of the event have some fundamental assumptions about the workflow that are wrong, and that most people do not understand the knock-on effect of their actions on a co-worker’s job. All this is important to reveal through discussion, while ignoring the claim that ‘we all know what each other does’ – I haven’t ever found this to be the case so far.
This discussion should start right at the very beginning of the workflow. In the case of a Journal Manuscript Submission System, for example, the process usually starts with an author with a manuscript that they wish to submit. That is your starting point. Make sure you really do identify where it all starts as most people will tend to suggest that the early stages are known and understood and simple and consequently they may try to skip this part or deal with it superficially. But your job is to have a discussion that covers the entire workflow and get exact details of what happens, by whom, and when. So keep asking really annoying pedantic questions to get to the clarity you need. Don’t let assumptions leave anything uncovered – I have often found that items everyone assumes are understood reveal hidden, not widely understood, processes when the right, very straightforward, clarifying questions are asked. For this process, you will have to get over your fear of looking stupid! Ask as many pedantic clarifying questions as possible.
Work through the workflow step by step from start to finish. As you do this, document it clearly – a shared large space (eg whiteboard) is best. As you draw it, ask for affirmations that it is correct. Work through all the eddies and conditional forks in the workflow to their conclusion and document them. In the end, make sure you summarise this in one simple document. Theexample below is a document from the Journal of Creative Technologies workflow discussion.
This is a useful process for exposing the actual (vs assumed) workflow to all players, stimulating ideas on how things could be better, and creating a ‘source of truth’ for the current workflow (people often forget details down the road).
While this part of the process is good for raising ideas on how things could be better, don’t let the group get stuck in the future weeds. Planning an optimum workflow comes next and if you let them stray too far into future thinking, they will either not finish documenting the current workflow, or they will confuse how things are now with how they want things to be. But don’t entirely kill these ‘future thinking’ moments either – let them be aired but if it looks like they are going to evolve into deep, nuanced, discussion of one part of the workflow and how it could be improved, then move discussion along. Also, make sure that all people are paying attention through this entire process. Don’t allow side conversations as these take those participants out of the wider discussion as well as distracting everyone else.
Discuss an Optimum Workflow
Next, we lead the group through an open-ended ‘pie in the sky’ discussion about possible utopian workflow futures. We start this discussion very broad – asking anyone to jump in with an idea. The discussion starts broad and we allow it to roam around a little. Often throughout this process, we are taking note of where there is agreement or ‘energy’ around a given idea or approach.
Sometimes people whiteboard ideas but most of the time it is pure discussion.
Discussing workflow possibilities with Collabra Pyschology Jourmal
After a while, perhaps 30 mins, maybe more than an hour, we start bringing back some of the ideas into the discussion that we know the group was interested in and ask them to expand it together. Sometimes we drop in small hints that a particular idea might be a good one but is technically unfeasible – this starts to give the group a sense of what is possible, or what might be technically achievable in the short, medium, or long term. It’s important not to squash ideas as soon as they emerge but to ‘sober them up’ if they get too fantastical. A little bit of realism doesn’t hurt at this stage but, more importantly, you want to get the ideas flowing. Nothing is nailed down or committed to at this point, it’s just exploration and discussion.
Mapping
Now we get to mapping these ideas onto a web-based platform. The group is going to engage in systems design without knowing they are doing so. We do this by first explaining a little about the web – some of the things that are possible. We might show some examples of sophisticated web-based editors like Wax, or in-browser pagination using Vivliostyle. Perhaps we might look at Trello/wekan or kanban examples of workflow management. We might look at Stencil.a or any number of examples of interesting platforms and approaches the web can offer.
We also talk about the efficiences of the web and how that is enabled – mostly this comes down to unpacking why a single-sourced content environment is so powerful, why ‘everyone working on the same object’ is important, how collaboration and concurrency can change the way we do things. As well as preparing them for the idea of designing a new system that is native to the web, we are introducing some new ideas that might reshape how they think about how they work. Why, for example, do we email MS Word files around when we can simply all see the same document, at the same time, in the browser?…these ideas will mean different things to different groups and how they play with them depends on how ready they are to explore new possibilities, combined with how much of their ‘old ways’ they are prepared to let go, plus how much they understand about the web. So it is important to let this conversation go at its own pace across whatever topics the group feels they need to explore. It is important that the discussion evolves of its own accord from the ideas introduced. We ‘shape’ the conversation, point it in a certain direction and signpost with certain interesting examples, rather than provide a soliloquy or monologue about how we would like things to be done. This is important, because unless the group internalises these ideas, they won’t end up exploring them when it comes to design time.
Next, we give a little rundown about ‘thinking in collaborative spaces’. Basically what we are trying to do is to take some of the ideas that emerged in the ‘optimal workflow’ discussion and start prompting them to think how this might be realised ‘inside the browser’. Most commonly we can do this by talking about very concrete things like browser windows, which everyone knows, and asking ‘how could this part of the workflow happen in a browser window?’ For example, in a journal system, we might ask ‘how might submission happen for an author in a browser window’? As a starter example, we could discuss this and draw a box on a whiteboard and draw some basic ‘UI’ elements in that box. This makes everything very very concrete. You are reducing systems design to something they understand without them realising that they are about to start designing a system.
The next step can take several directions, but the most common is that we split the group into smaller groups. 4 or 5 to a group is usually a good number. We then give them large sheets of paper and a bunch of thick pens, and send them to acoustically separated spaces to draw up proposals for ‘several spaces’ that would represent the workflow in the browser. The time we give them depends on the time at hand. You want more than 15 mins, but 45 is probably too long. Sometimes we might also ask them just to focus one one part of the workflow, usually the first part (however you design this is up to you).
Erich van Rijn (UCPress) pitching some ideas to the group while Dan Morgan (Collabra) documents, and Paul Shannon (eLife), and Yannis Barlas (Coko) listen.
It is very important when you send them away to do this that you ask them to draw the interfaces. One big page of paper, for example, per ‘space’ (browser window). If you don’t do this some groups, especially those used to writing requirements docs, will write lists. The problem with that is that these lists don’t tend to be scoped or connected very well. They just turn into a list with as many items relevant to (for example) ‘submission’ as you can imagine. Better is if they draw the spaces as if it was a browser window, putting in UI elements with basic drawing.
Oliver Buchtala (Substance.io) holding up his group’s proposal at Erudit, Montreal.
No one has to be an artist, it just needs to be a rough proposal of what that space would enable, and one most people will understand if they were just to look at it.
John Chodacki (CDL) puts some finishing touches on a proposal he designed together with Andrew Smeall (Hindawi), and Jure Triglav (Coko).
We circle around and make sure everyone is getting on with the task and in good time. At the end, we bring everyone back into the room and ask them to present their proposals to the rest of the group.
Lia Schiff (CDL) presenting a proposal to the rest of the group.
We give them a short amount of time to make the presentations. Perhaps 10 mins, more if the scope of the workflow is larger.
What you will be surprised at, I can guarantee it, is that all the proposals are *great* AND they will all be very similar. We have done this many times and the results of each group are rarely very far apart. When they are far apart, it’s usually because a group has locked onto one idea or another as a starting point and designed everything around that. These ideas usually have something very worthwhile that can be combined with the other proposals to improve them.
As each group finishes presenting a space or group of spaces we ask the group for questions or comments. We don’t let this go too deep into the weeds as time is tight at this point, but some discussion is always useful.
Another proposal at the Erudit workshop.
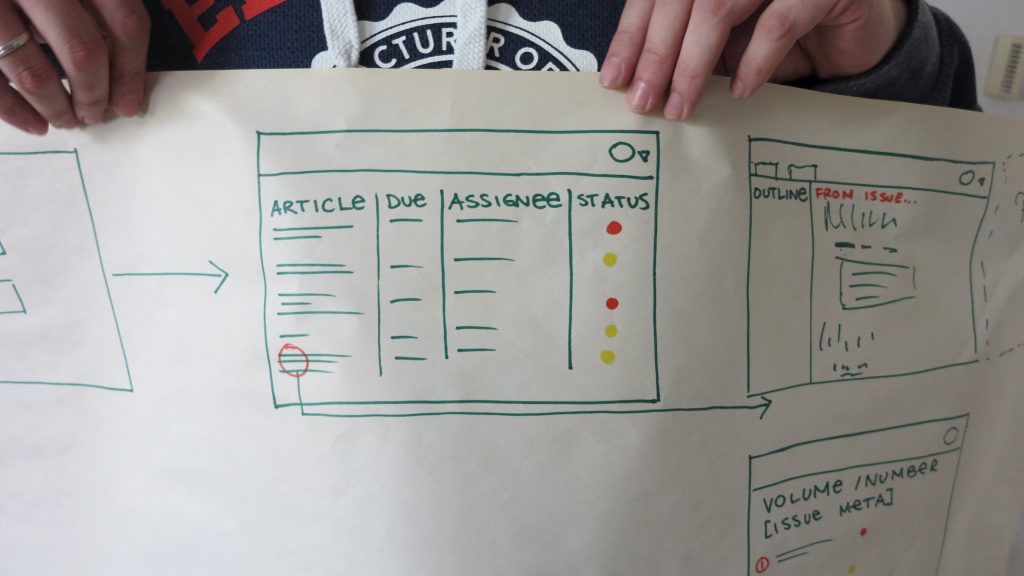
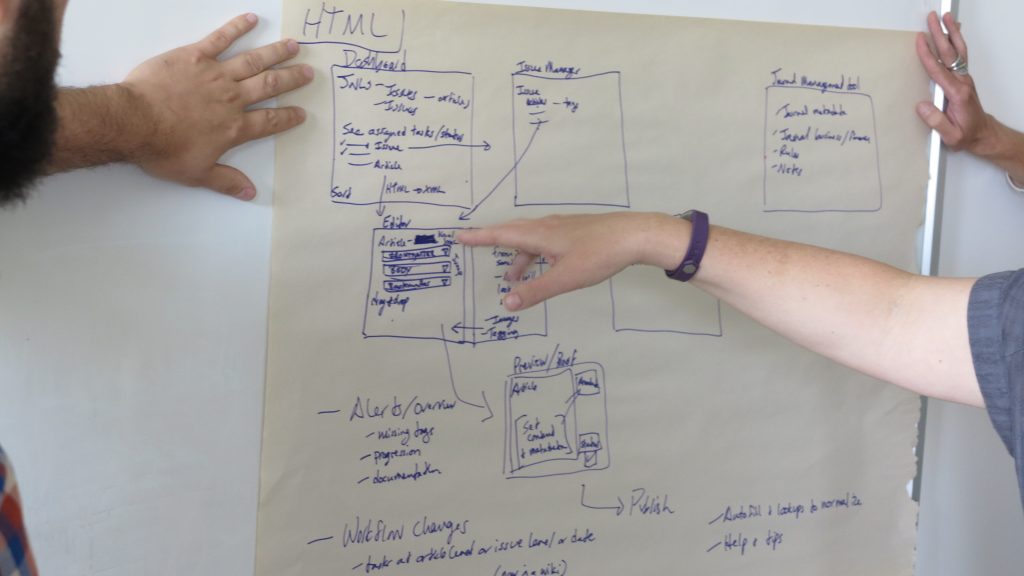
Then at the end, you discuss these approaches and agree on a common approach. We call this an ‘architecture’ which it is to an extent. It is the bird’s-eye view of how their new workflow will fit snugly into a browser based workflow. The following being an early ‘architecture’ or high-level systems view of a journal platform for Collabra.
Handily each of these new spaces can then be built as a PubSweet component! The following is the architecture showing the components we need to design and build – this diagram was the result from early sessions with the staff from UCP I facilitated to produce the Editoria monograph production platform.
This process is a very specific description of the first part of the Cabbage Tree Method. The second part of the Cabbage Tree Method involves facilitating the design of each of these components.
While Yannis and Christos have been in San Francisco they worked on a number of features that will appear in the soon-to-be-released Editoria 1.1
The two standout features include:
automagic book builder
diacritics interface
The automagic book builder built primarily by Yannis enables a user to populate the structure of a book automatically from a directory of MS Word files. Essentially, from the book builder component the user can click ‘upload word files’ and a system dialog opens. They can navigate to a folder on their computer and select the files they wish to use to create the book. Editoria then sends all these files to INK to convert to HTML, creates the structure of the book, and populates all the chapters and parts with the right content. At this moment it ‘knows’ which MS Word file is in the front/body/back matter and whether it is a part or a chapter by the file name. We will add a config so the rules regarding what a file is called and where in the book it lands can be determined per publisher or (perhaps) per user.
This feature means that a production editor can simply ‘point’ Editoria at a directory of MS Word files, which is what they are used to working with, and without doing anything else other than press ‘upload’ the book will be built for them in the correct structure (assuming they named everything right). It’s a lot less work than uploading every file individually.
The second feature is a Diacritics interface for the editor. This rather nicely made by Christos so that you can have per-publisher assigned special characters categorised and listed in a simple interface (opened from the editor). That is in itself interesting as it might lend itself to other options like a special character ‘favorites’ list etc…but two other elements add some elegance to the implementation, the first is a simple checkbox that will determine if you leave the Diatrics dialog open or if it closes automatically once a character is placed. The second is that the user can search through the Diacritics with key words. For example you could type ‘dash’ to get a list of all the dash characters (m-dash etc), or typing ‘turned g’ would give you the result: ᵷ
We observed that copy editors search Wikipedia for the special characters they want. Now they can search within the editor interface, using the naming conventions they are used.
The Diacritics feature is, of course, a wax-editor component….which is used as the editor in Editoria. We are working a lot on Wax and it will become a substantial product in its own right.
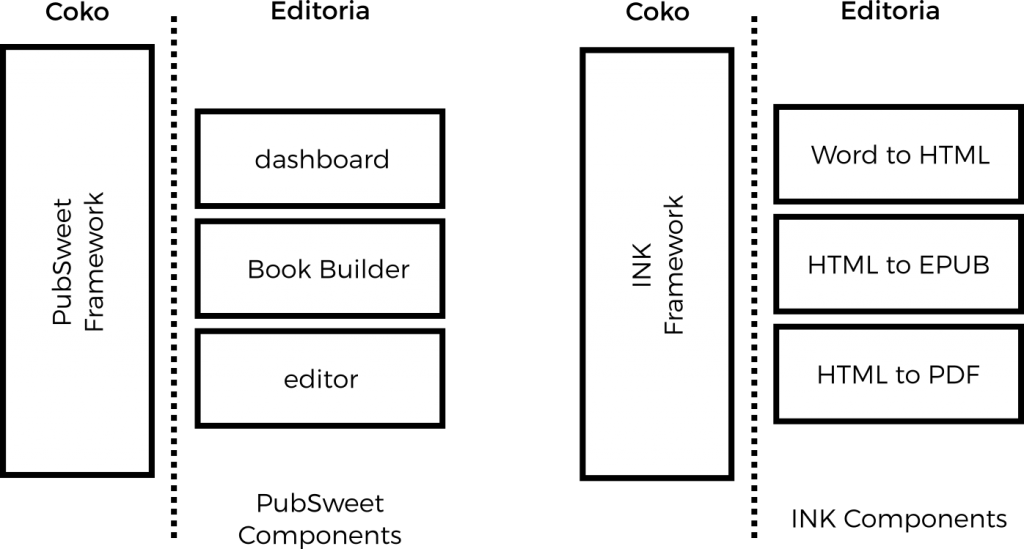
We are currently building multiple systems which are all component based. PubSweet, for example, contains three softwares (which you can find here):
pubsweet-server
pubsweet-client
pubsweet-cli
In addition, Editoria, is built on top of PubSweet and it consists of at least the following standalone components (which you can find here):
editoria
editoria-dashboard
editoria-bookbuilder
wax-editor
To the end user these platforms appear ‘as one thing’ but in effect, they are made of multiple standalone moving parts which are mostly all legitimately within the same namespace (editoria-*)
Which brings about a few interesting questions – the first is regarding versions, the second about what exactly it is that we are building.
First – how do you version something like Editoria when the ‘bona fide’ Editoria repository is ‘just glue’ code that brings the other Editoria components together? Each of those components has different version numbers that advance in a rather traditional semver way, but the actual Editoria glue code won’t move much at all. Hence we need to find a good way to think about versioning that communicates forward movement to the outside world.
So, for this situation, we have decided to simply advance the minor number of the version for each significant feature (or group of features) added to the system at large. So, for example, Editoria is now at 1.0. When we add the multiple MS Word import and the diacritics interface we will advance it to 1.1 – this is kind of arbitrary but as long as we correctly version the other components I think its the best way to do it.
xpub offers a different challenge. xpub started as the working title of journal platform (Manuscript Submission System) built on top of PubSweet. However, we quickly realised that xpub is actually more of a ‘ecology’ of components that can be used to build a journal workflow than it is a journal platform. Our thinking is moving this way because we aren’t really building platforms so much as components that can be assembled into platforms. So we don’t wish to have a single ‘xpub journal platform’, rather we will build many components (just like Editoria) and name them with the xpub-* prefix eg. xpub-dash, xpub-submission etc. These components can then be ‘glued together’ to make the journal platform of your dreams…
Just to make it more complex….we are also breaking down what we now call components into UI libraries…so we will also have an xpub-UI-library which contains ‘sub components’ that are then assembled into a component. For example, what we would call xpub-dash is a component, but it is assembled from several xpub-UI-library sub-components like ‘upload button’, ‘article list’ etc…
When we assemble xpub parts into a journal we will then name it something like xpub-collabra (the first assemblage we will be working on)…
So…you can see the difficulty! How to think about what it is you are building, and, how to version something like xpub-collabra when it is really nothing but the glue code which connects a lot of separate xpub-components which in themselves are assembled from xpub-UI-library sub-components!!!!
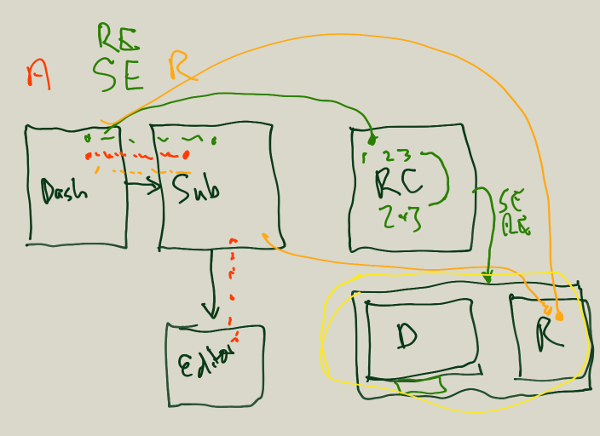
Below is an image from a whiteboard session conducted some weeks ago with myself, Alf Eaton and Dan Morgan.
It shows a number of roles (author, Reviewing Editor, Senior Editor, Reviewer) and their path through a component-based Manuscript Submission System built on top of PubSweet.
The components shown above are:
Dashboard
Submission Page
Editor
Review Control Panel
Review Page
Decision Page
We are currently building this out. Of course we have this broken down in a little more detail! Including the above to give some insight into the starting point of a typical process of mapping workflows onto a component based system. I’ll write more about this at another time.